
Summary: There are five basic styles of recommenders differentiated mostly by their core algorithms. You need to understand what’s going on inside the box in order to know if you’re truly optimizing this critical tool.
 In our first article, “Understanding and Selecting Recommenders” we talked about the broader business considerations and issues for recommenders as a group. In this article we’ll cover the five basic types of recommenders and their strengths and weaknesses.
In our first article, “Understanding and Selecting Recommenders” we talked about the broader business considerations and issues for recommenders as a group. In this article we’ll cover the five basic types of recommenders and their strengths and weaknesses.
Given that Recommenders add 10% to 25% of incremental income to your ecommerce business you need to know exactly how these are working. Optimization will involve fine tuning as well as potentially combining different models.
Keep in mind from our last article these general differences among recommenders:
- Some have a greater focus on customer similarities, some on content similarities, and some a blend of the two.
- Different algorithms vary in their utility based on how much you know in advance about your customers, your content, and whether you can get your customers to give you feedback about their purchase.
5 Types of Recommenders
In the following section we describe the five broad types of recommenders ordered roughly from most simple to most complex.
- Most Popular Items
- Association and Market Basket Models
- Content Filtering
- Collaborative Filtering
- Hybrid Models
1. Most Popular Items – The Simplest Strategy
The simplest strategy is to simply offer the customer whatever is most popular, be that a movie, a book, or an article of clothing. Without doing anything more than looking in your sales records you could accomplish this. No data science required.
It’s not particularly personalized but could be useful if you know very little about your visitor. It does require some basic content attributes to create subcategories that can match your visitor’s current browsing. For example, if you are offering a wide variety of merchandise like everything from tools to clothing, or movies, books, or news that appeal to different interests then you’ll need to try to match items at least in the same category just viewed by your visitor.
Despite these limitations Home Depot regularly uses ‘best sellers’ and the GAP regularly uses ‘latest products’ and ‘arriving soon’ to increase revenue. Most likely you will consider ‘most popular’ recommenders as a supplementary strategy.
2. Association or Market Basket Analysis
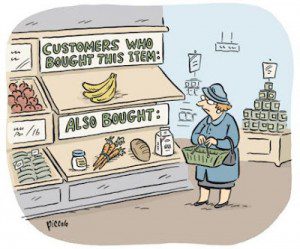 Association Analysis and Market Basket Analysis looks almost exclusively at content. This type of statistical analysis relies on only the simplest of calculations to find items that are frequently consumed together. Association and Market Basket analysis are mathematically the same. When customers typically acquire the items or services one at a time (like banking services) we call this Association. When customers potentially buy several things at once we call this Market Basket. So Association Analysis is conducted at the customer level (what’s in their account) while Market Basket Analysis is conducted at the transaction level (what’s in their basket). There are three main steps:
Association Analysis and Market Basket Analysis looks almost exclusively at content. This type of statistical analysis relies on only the simplest of calculations to find items that are frequently consumed together. Association and Market Basket analysis are mathematically the same. When customers typically acquire the items or services one at a time (like banking services) we call this Association. When customers potentially buy several things at once we call this Market Basket. So Association Analysis is conducted at the customer level (what’s in their account) while Market Basket Analysis is conducted at the transaction level (what’s in their basket). There are three main steps:
- Evaluate the strength of the relationship between each of your products and every other product you offer using the algorithms of Association math.
- Identify those pairings that have very strong affinity (typically an affinity score of 2 or higher). For example, a customer with a credit card might be found to be twice or three times as likely to have an auto loan than an auto loan customer selected at random.
- Create a personalized offering for customers who have one product of a strongly associated pair but not the other.
There are several advantages to this very simple technique.
- It’s extremely simple and fast.
- It will work with very small and sparse customer bases. For example if you are a small service provider like a regional bank with perhaps fewer than 5,000 customers and perhaps only 30 products or an similarly small boutique ecommerce provider.
- Knowledge of the customer beyond what products or services they currently have is not necessary. Data prep is minimal. Since adding to your knowledge of the customer can be time consuming and expensive and is not required here, Association and Market Basket Analysis are likely to be the most cost effective method for creating personalized offerings.
Association and Market Basket Analysis are at the core of ecommerce recommendations under the heading “customer who bought this also considered these” or “items bought together” which is a staple at Amazon. Since very little customer information is required it’s not going to work as well where the selection is extremely broad like movies, books, or music and little is known about what the customer typically likes. You can however filter using the visitor’s current browsing activity.
3. Content Filtering (CF)
Content based filtering was the state of the art 10 years ago. It is still found in wide use and has many valid applications. As the name implies CF looks for similarities between items the customer has consumed or browsed in the past to present options in the future. CFs are user-specific classifiers that learn to positively or negatively categorize alternatives based on the user’s likes or dislikes (the user profile).
The Algorithm:
The system creates a user-specific content-based profile using discrete attributes. The user’s history of consumption or browsing is used to create a weighted vector of the item features. Weights are learned or assigned to vary the importance of attributes for the particular user. That weight is used to compare to the vector weight of different items that might be recommended. Techniques for calculation may vary from simple weighted averages to Bayesian classifiers, cluster analysis, decision trees, or more complex approaches including artificial neural nets. You will need to closely examine any packaged solution to evaluate the method of calculation and its effectiveness.
Item Attributes:
An obvious requirement is that you are able to provide a reasonably large number of content descriptors to use in the classification. These can be Boolean (the movie is animated, the book’s author is Clive Cussler, the shirts material is cotton, the opening week movie revenues were $XX). They can also be continuous such as the rating received by the movie from a ratings source, the ‘average star rating’ of other customers who have consumed the item, or the percentage or number of minutes in the movie judged to be ‘action’ or ‘romance’.
The ability to acquire and maintain content attributes is both a key criteria and a key limitation of CF. Some attributes may be easy to acquire but others may not (e.g. constantly updated attributes of new electronics or attributes of movies). In environments like movies, music, and news the inventory may change so rapidly and be so large that acquiring and maintaining attributes is too difficult or too costly.
In a few large-volume high-turnover environments external data may be available. For example Pandora Radio which uses CF is able to make use of 400 attributes for both song and artist provided by the Music Genome Project in order to find similarities. Rotten Tomatoes, the movie recommendation site is another example of a CF implementation.
Enhancing Performance:
 If the classifier has nothing to work with other than the binary purchased/ not purchased of a recommendation the results will lack accuracy. Typical solutions that are valuable in some environments but not in others include:
If the classifier has nothing to work with other than the binary purchased/ not purchased of a recommendation the results will lack accuracy. Typical solutions that are valuable in some environments but not in others include:
- Post suggestion rating: The user is given the option of using a like/dislike button for recommendations presented even if they are not purchased or selected.
- Post purchase rating: The user gives a rating (typically 1 to 5) regarding their satisfaction with the item.
- Pre-consumption voluntary profile: For many applications asking the user in advance to provide some profile information regarding preferences aids greatly in pre-filtering alternatives.
- User profiling: The user profile can be enhanced with segmentation or demographic information.
Strengths and Weaknesses:
- CF largely solves the ‘cold start’ problem of how to deal with a visitor with which you have little or no history since the recommendations can be driven by a combination of browsing history (however short) plus like/dislike or voluntary profiling.
- Enhancing profiles may not be feasible or at equal levels for all users leaving a sparsity problem in the calculations. You may not have a tag for every category for every item.
- Typical implementations of CF are able to learn from only one source (your site) which limits its ability to make recommendations that are not part of the original ‘seed’. Some systems such as news aggregators have been designed to combine content from multiple sources to improve this limitation.
- Without expanded user profiling or feedback the CF system has little on which to base its calculation other than consumed/didn’t consume.
4. Collaborative Filtering (CB)
Collaborative filtering focuses on the user and other users found to be mathematically similar to the user. In theory no specific attributes are required for the content which CB can infer. Later we will see that adding content attributes can enhance performance but is not technically required.
The underlying premise is that if two users have a strong similarity of likes and dislikes in the past that they will continue to have strong similarity in the future. CB will match people who like romance films to those films that have strong romantic content without the requirement for defining ‘romance’. Once the similarity is established then items consumed by one user can be recommended to other similar users.
The existence of a post-selection rating, an immediate like/dislike indication, and/or a pre-existing user profile is necessary to make this technique viable. CB attempts to predict the user rating for an unseen item. Accuracy of the prediction can be determined by comparing the predicted rating to the rating actually given when the recommended item is consumed.
The Algorithm
Most CB systems use vector factorization and begin by creating a feature vector describing the user (products and features identified as interesting, size and frequency of prior purchases, etc.). In more advanced CB systems (combined CB/CF systems) feature vectors are also constructed for the products (author, genre, features, etc.). Cosine similarity calculations are made against the feature vectors to identify similar customers and similar products. Recommendations can be made based on either the similarity of the customers or the similarity of products to other products the customer has purchased or browsed.
Customer based factorization is straightforward linear algebra and can be refreshed in memory in real time after each ranking or selection/non-selection of the recommended item. Performance will theoretically improve during the user’s interaction with your site as they rank and select new items. Note that for very large user bases with very large content inventories the compute power may be significant but well within the range of MPP cloud services.
Product based factorization is more likely based on clustering or statistics like Pearson’s correlation and are conducted in batch off line.
User Attributes
CB systems rely on two types of data to perform well. The first are items we ask the user to provide including:
- Rating an item on a five point scale or using an immediate like/dislike button.
- Asking the user to search for an item and observing the terms used.
- Creating a profile of likes and dislikes by different factors such as genre, author, or similar factors.
- Presenting two alternatives and asking the user which is better (conjoint analysis).
We will also be gathering data on the user’s actual on-line behavior including:
- Observing items viewed including time spent viewing.
- Actual purchases.
- If allowed, gathering data from the user’s computer such as lists of items actually listened to or watched.
- Using outside data sources like social network sites to add likes and dislikes for this user.
Strengths and Weaknesses:
- CBs do not rely on predefined content attributes and can make accurate recommendations for different categories of content without requiring a human-designated understanding of the item itself. These synthetic attributes are valuable can also be exported to Content Filtering systems however they may be difficult to make human interpretable.
- CBs require large amounts of data to analyze. Where item variety is very large there may be many untagged items creating a sparsity problem in the calculation. It may be difficult to find other users that have rated the same items. Even the most popular items may have only a few ratings.
- Items that are new and have never been rated cannot be recommended since recommendation relies on prior rating.
- CBs tend to recommend items that are popular and therefore may under perform for users with unique tastes.
- Matrix factorization may over fit if there are too many parameters.
- Most popular items (for example movies) can be processed separately from the full inventory (if it is very large) so that the most popular items can be updated in real time even if the entire inventory is too large to be processed after each user selection.
5. Hybrid
There are two interpretations of Hybrid recommenders and you should think of them as two sides to the same coin.
- Brute Force or Knowledge Based
- Combined CF/CB Systems
Brute Force or Knowledge Based
This variation is quite easy to understand since it involves the addition of rules by human subject matter experts. Good Product Marketing Managers can frequently define what products do and do not go together, and which may be complementary versus supplementary.
Combined CF/CB Systems
As you read about CF and CB recommenders it may have already occurred to you that it would beneficial to have the benefit of both. Note that some versions of CB systems already use both customer and item attributes although the item attributes in this case are typically synthetic calculated variables that may not have any easily understood logic associated. In this case the combined CF/CB systems are different based on the many ways these two system types can be combined.
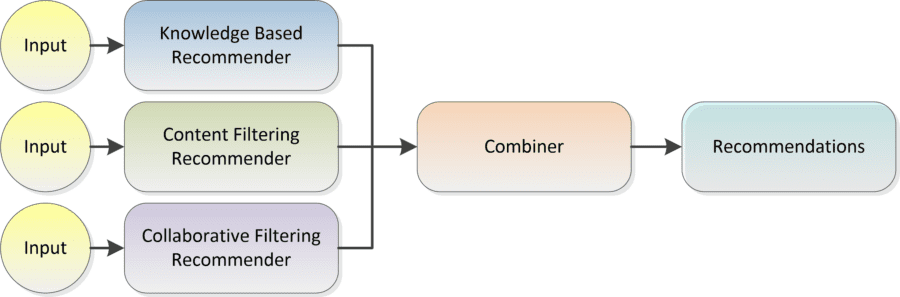
There are no specific universal best practices for hybridizing recommenders which will require your insight into the special circumstances of your business. Some strategies might include:
- Weighting: A voting strategy among competing recommenders.
- Rules base selection: Based on rules you devise, in some cases one recommender will be dominant over the other.
- Combination: Recommendations from both are presented together.
- Attribute Integration: Taking meta data from both recommenders to drive still a third recommender.
As a practical matter, adding the Knowledge Based component to the other techniques, you might always choose that have the Knowledge Based rules as the first filter on potential recommendations or as a final filter.
Netflix uses a hybrid CB/CF recommender. It offers both recommendations based on the habits of similar customers (Collaborative Filtering) as well as recommendations based on highly rated films seen to be similar by content attributes (Content Filtering).
Remember also that you may have to make several different types of recommendation depending on where your customer is in his journey. So if your recommendation is supplementary (replacing the customer’s primary selection), or complementary (adding value with other items to the primary item already selected), or providing new ideas and inspiration to your customer’s shopping, the techniques may need to be completely different for each.
It is likely that your optimum recommender will be a hybrid. How the components are designed and assembled will be up to you.
Other Articles in this Series
Article 1: “Understanding and Selecting Recommenders” the broader business considerations and issues for recommenders as a group.
Article 3: “Recommenders: Packaged Solutions or Home Grown” how to acquire different types of recommenders and how those sources differ.
Article 4: “Deep Learning and Recommenders” looks to the future to see how the rapidly emerging capabilities of Deep Learning can be used to enhance performance.
About the author: Bill Vorhies is Editorial Director for Data Science Central.and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}