
Summary: There are many sources of packaged recommenders including the more comprehensive Digital Personalization platforms. It’s also possible to code your own. Here are a few things to consider.
 In our first article, “Understanding and Selecting Recommenders” we talked about the broader business considerations and issues for recommenders as a group.
In our first article, “Understanding and Selecting Recommenders” we talked about the broader business considerations and issues for recommenders as a group.
In our second article, “5 Types of Recommenders” we attempted to cover the waterfront, or at least most of it by detailing the most dominant styles of Recommenders that vary mostly in the algorithms they use.
In this article we’re going to focus on how to acquire different types of recommenders and how these sources differ.
Packaged Solutions
Cloudera / Hortonworks / MapR
If you are already committed to one of these major distributions then chances are that you’ll be staying within that distro to assemble your recommender. The source could as easily be one of the proprietary distributions from the likes of IBM, Oracle, or HP. It’s likely you’ll be using the components of Spark or even Spark Streaming since that platform has so rapidly overtaken Hadoop.
Building a recommender using the components of your favorite major distro is going to look a lot like working with Legos, lots of pieces but maybe not as easy to snap together. Each of these companies is going to prescribe a series of components from their packaged versions that will work well together to solve your recommender problem. Here for example is a sample from Cloudera.
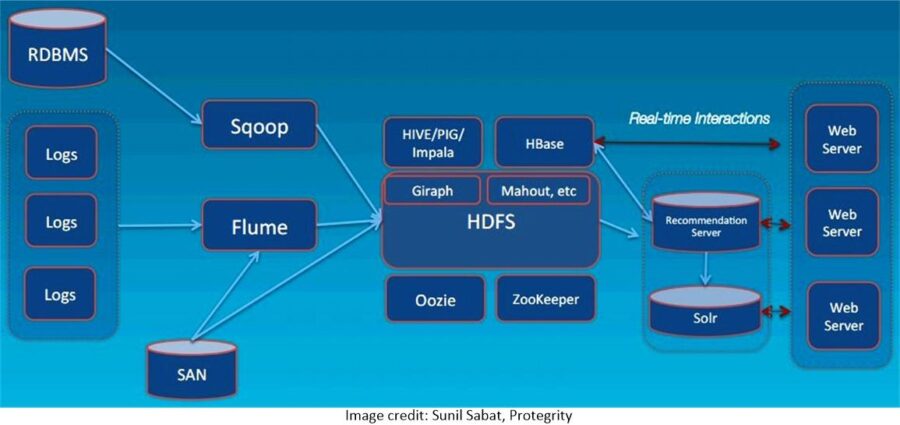
You will need to have substantial on-board (or hired in) expertise since some of these can result in quite complex architectures.
Some providers like MapR have quick start packages designed for specific industries. For ease and quick implementation you’ll want to evaluate these.
SAS / IBM SPSS / Other Major Analytic Platforms
If you are already a SAS shop, committed to IBM SPSS, or any of the other major analytic platforms it may also be reasonable to turn to these providers for both the data platform as well as the data science platform.
This is mostly a matter of emphasis. Using a predictive analytic platform as your starting point emphasizes the underlying data science and may be more comfortable for your on-board data science team.
While much of the predictive analytics is pretty straightforward there are still a wide variety of underlying algorithms from which to choose in order to optimize sales. A short and not exhaustive list would include:
- K nearest neighbor and other clustering algos
- Matrix factorization
- Association Rules
- Slope One
- Ensemble Methods
- Pearson’s Correlation
In some cases these analytic platforms will have simplified the implementation of the data science by creating compound rules. SAS for example has a single command PROC RECOMMEND which encompasses the main calculations in collaborative filtering.
Two of the most important takeaways from focusing on the data science will be:
- Your recommender needs to be tested for accuracy in the same way as any other model, by comparing the result to holdout test data to ensure it’s not overfitting.
- The models that drive your recommender will lose accuracy with time. There needs to be a specific process for monitoring and refreshing the analytic components of your recommender.
Digital Personalization Engines (DPEs)
We’ve been focusing on Recommenders but it may be time to take a more expansive view. The goal is personalization and it’s reasonable to argue that personalization should extend to every aspect of your digital interaction with your customer.
What CRM and Marketing Automation platforms did for inbound and outbound marketing Digital Personalization Engines (DPEs) are seeking to do for digital commerce.
DPEs are relatively new. So new that neither Gartner nor Forrester has an explicit ranking. Gartner says that about 2/3rds of the implementations it looked at are less than four years old. Even more interesting, 70% are SaaS implementations as opposed to on prem.
Gartner publishes a ‘Market Guide for Digital Personalization Engines’ which is the best place to start if you want an in-depth understanding.
What’s appealing about DPEs are a couple of things:
- They provide a holistic approach to personalizing your customer’s web experience on your site. This includes the recommendation engine but extends to page customization and search customization as a minimum.
- Since the great majority are SaaS that will limit the amount of infrastructure maintenance you have to perform and should significantly lighten the data science load. If you don’t have a substantial on-board data science team or if you are more inclined to the Citizen Data Scientist simplified model DPEs should be particularly appealing.
Gartner says that DPEs must do at least the following to be considered in the running:
- Customize landing pages for known or unknown shoppers.
- Make continual presentation layer changes.
- Have digital-marketing capabilities, (e.g. email reminders for abandoned shopping carts).
- Incorporate multiple types of analytics and analyze multiple types of customer data.
- Suggest or serve unique content to an individual via:
- Search
- Landing pages
- Product offers and recommendations
- Should be continually running A/B and multivariant testing — incorporating two or more variants of a web page to two different sets of users to determine which variant is most effective.
- Serve multiple digital channels including personalization for mobile and even social.
Among the 36 vendors reviewed in the Gartner report you’ll find the expected major players like IBM, Oracle, Salesforce, SAP, and SAS. You’ll also find 31 other new small players all trying to make their way in this space.
Most of the heavy data science remains in the recommender engine; the balance appears to be mostly multi-arm bandit and rule-based if-then-else instruction. There are some curious omissions in the category. For instance I would have thought that dynamic pricing to avoid giving unnecessary discounts would have been a feature, but not so.
To some extent this field of competitors does codify best practices within their platforms which seems like a natural progression. The other natural progression will be the convergence of DPEs, marketing automation, and CRM.
Code Your Own
Of course you can write your own recommender. R and Python both have recommender macros in their ML libraries with perhaps a nod to Python for its superiority as production code. In the Hadoop ecosystem and particularly with respect to Spark, Scala is the most natural choice. Although you can use Python PySpark and even R, Spark’s native language is Scala.
In our next article in this series we’ll talk about Deep Learning and its future impact on recommenders. There we’ll talk about how to write a recommender with just 10 lines of C++ code on Amazon’s DSSTNE system.
Other Options – Graph Databases
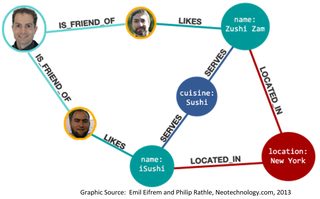 In the mid-2000s about the same time Hadoop became open source there was a renewed flurry of interest in graph data bases. Because they are natively structured with graph-like connections between nodes it seemed they had a big inside lead on the recommender engine market.
In the mid-2000s about the same time Hadoop became open source there was a renewed flurry of interest in graph data bases. Because they are natively structured with graph-like connections between nodes it seemed they had a big inside lead on the recommender engine market.
It remains true that excellent recommendation engines can be constructed on NoSQL graph data bases like Neo4j or Oracle’s graph data base. The downside however is the need to adapt to a completely new way of thinking about databases that has slowed adoption. If you’re interested in graph databases or have already implemented one then you might explore building CF/CB recommenders directly on these platforms.
Other Articles in this Series
Article 1: “Understanding and Selecting Recommenders” the broader business considerations and issues for recommenders as a group.
Article 2: “5 Types of Recommenders” details the most dominant styles of Recommenders.
Article 4: “Deep Learning and Recommenders” looks to the future to see how the rapidly emerging capabilities of Deep Learning can be used to enhance performance.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}