
Mathematical optimization for AI
Interview / Jerry Yurchisin, Sr. Data Scientist @ Gurobi As a lifelong systems thinker and technology advocate, I’ve long been fascinated by the intersection of… Read More »Mathematical optimization for AI
This rubric covers the use of statistical tools working on large datasets to create models and derive inferences, as well as coverage of the field in its entirety. This differs from machine learning primarily in that the latter focuses on functional gradient analysis or neural networks (kernels) to derive models.

Interview / Jerry Yurchisin, Sr. Data Scientist @ Gurobi As a lifelong systems thinker and technology advocate, I’ve long been fascinated by the intersection of… Read More »Mathematical optimization for AI


Biometric authentication systems are one of the most widespread and accessible forms of cyber hygiene in consumer products, and they’ve gone beyond phone face scanners… Read More »Data science is key to securig biometric authentication systems


AI in Agriculture Precision Farming AI-Powered Agriculture Climate-Resilient Crops
Sustainable Farming Practices AI for Pest Control AI for Soil Analysis Machine Learning in Agriculture Smart Farming Solutions IoT in Agriculture Crop Monitoring with AI
Predictive Analytics in Farming AI for Weather Prediction in Agriculture
AI-Driven Precision Irrigation AI in Fertilization Optimization Sustainable Agriculture Technology Advanced Farming Techniques Agriculture Data Analysis with AI
AI-Powered Smart Irrigation Agricultural Innovation with AI

Interview with Dr. Andrea Isoni – SHOW 16 Intelligent systems are evolving faster than ever, and keeping up with the latest advancements requires expertise, foresight,… Read More »Current state of machine learning and intelligent systems

Machine learning enables systems to analyze data and make decisions without manual intervention. However, reliability hinges on the quality of the information they use. Data… Read More »How to ensure data consistency in machine learning

Data centers are consuming a massive amount of power. The easiest solution is to raise temperatures, driving resource utilization down. However, that complicates hardware preservation… Read More »Optimizing data center energy consumption with predictive analytics

As someone who has spent years navigating the exciting and unpredictable currents of innovation, I recently had the privilege of joining Chris Kalaboukis on his show, Think Future.… Read More »A vision for the future of AI: Guest appearance on Think Future 1039
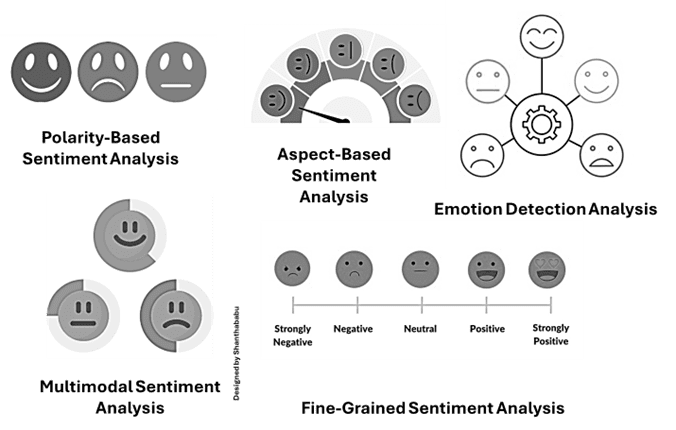
Introduction Sentiment analysis, also known as opinion mining, is a powerful concept in the Natural Language Processing (NLP) technique that interprets and classifies emotions expressed… Read More »Sentiment analysis at scale: Applying NLP to multi-lingual and domain-specific texts


Wirestock on Freepick Mark Twain coined the term The Gilded Age when he published his 1873 novel The Gilded Age: A Tale of Today. Between… Read More »Data science implications of a second gilded age

Image by Gerd Altmann from Pixabay In September 2024, Salesforce AI Research EVP and Chief Scientist Silvio Savarese posted at the Salesforce 360 site on… Read More »Large action models and the promise of true agency