
Summary: In this last article in our series on recommenders we look to the future to see how the rapidly emerging capabilities of Deep Learning can be used to enhance recommender performance.
 In our first article, “Understanding and Selecting Recommenders” we talked about the broader business considerations and issues for recommenders as a group.
In our first article, “Understanding and Selecting Recommenders” we talked about the broader business considerations and issues for recommenders as a group.
In our second article, “5 Types of Recommenders” we attempted to detail the most dominant styles of Recommenders.
Our third article, “Recommenders: Packaged Solutions or Home Grown” focused on how to acquire different types of recommenders and how those sources differ.
In this last article in our series on recommenders we look to the future to see how the rapidly emerging capabilities of Deep Learning can be used to enhance performance.
The Deep Learning Landscape
For clarity, when we talk about Deep Learning we’re talking about the group of Artificial Neural Nets characterized by many hidden layers (hence ‘deep’ learning).
Two of these, Convolutional Neural Nets (CNNs) and Recurrent Neural Nets (RNNs) have been at the forefront of bringing image recognition and natural language understanding and response to life. Alexa, Amazon Echo, and the Hey Google appliances are only the latest of many commercial manifestations of deep learning.
Especially with respect to image recognition it wasn’t until just 2015 that these systems reached the point where they could consistently outperform humans at the same task of categorizing images. Image recognition is also one of the key technologies in self-driving cars.
Application to Recommenders
One the takeaways you should have from our previous articles is that while the predictive analytics within the different styles of recommenders is pretty well settled, there are two areas clearly in need of improvement.
- The Cold Start or Sparsity Problem: When you have limited or even no experience with a visitor to your site how do you best personalize the experience with so little to go on? Sparsity, the problem that arises with the low volume ‘long tail’ items in your offering means that very few of these items may have ratings at all. This leads to a problem very much like cold start.
- Limited Item Attributes: Ideally we would like to have coded our inventory for a wide arrange of item attributes that would make our predictions more accurate. However, there are broad categories of digital commerce that don’t lend themselves to understanding item attributes.
- One reason is that they change too rapidly, for example with the huge inventories of movies, music, or news items where human coding of attributes could never be cost efficient.
- A second area is human perception, most evident for example in men’s and women’s clothing. The material may be known (e.g. cotton) and the general category (e.g. button-up sweaters) and even the color (e.g. red). But in the perception of your customer one red sweater in not the same another.
Discovering Item Attributes
CNNs used in image processing are successful because they can discover the features (attributes) of the images they are classifying without human definition. Without deep-diving how CNNs work, keep in mind that through each of their hidden layers CNNs scan and distill the results of the previous layer to generate a numerical vector.
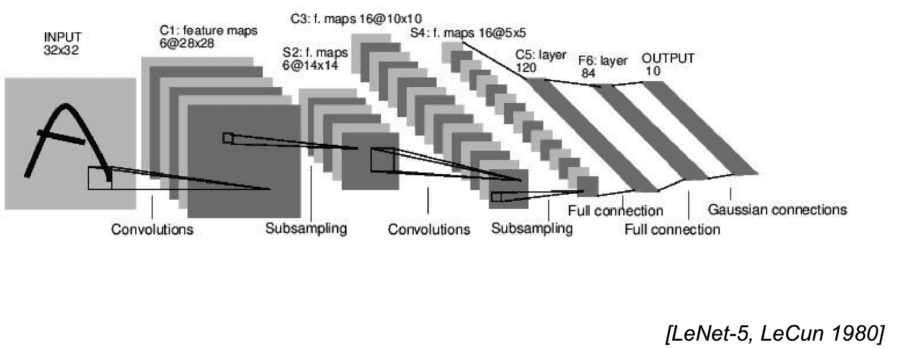
There would typically be five or six hidden ‘convolutional’ layers but Microsoft recently won a prestigious image recognition competition with a CNN of 152 layers. The thing to keep in mind is that each subsequent layer is a smaller more condensed yet more detailed understanding of the original image. If all you had was the final dense layer you could run the process backwards to reconstruct the original picture.
That final most dense convolutional layer is then fed to the final classifier layers where the CNN learns that the image is a cat or a car or a red stop sign. However, that final most dense convolutional layer which might typically be on the order of a 4,000 dimension numerical vector is also an extremely sophisticated description (attribute) of the original image.
This set of images from a smaller CNN used to learn the features of a car illustrates another fact. The attributes that the CNN learns are not going to be easily interpreted directly by a human.

In 2016 research scientists Ruining He and Julian McAuley from the University of California, San Diego applied this ‘attribute generation’ feature of CNNs to the problem of men’s and women’s clothing and also to cell phones where they felt the perceived attractiveness of the product was also a factor in purchase.
The procedure, VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback, involved pre-training their CNN on 1.2 million ImageNet images. They then scanned pictures of all the clothing on an Amazon site and extracted the final dense numerical vector. This new CNN attribute was appended to the other attributes already known such as color, size, price, material, and so on. Now when a customer clicked on an image or purchased an item those preferences became part of the data available to be evaluated by the Collaborative Filtering recommender.
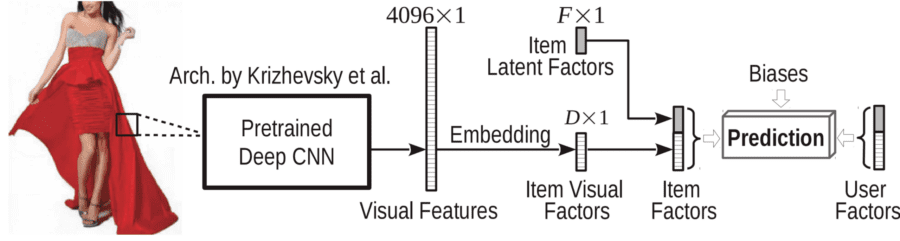
VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback
The use of the new attribute which implicitly coded for the customer’s sense of fashion and comparability with other similar items was remarkably successful. Compared to four other common recommender strategies, the addition of the new attribute allowed He and McAuley to improve overall recommender performance by 10% to 26% on different clothing categories, and by 25% to 45% for ‘cold start’ previously unseen customers.
The improvements were most successful in the clothing categories. Their tests on the cell phone category yielded smaller results perhaps reflecting that cell phones are more interchangeable in the customer’s mind than that hypothetical red sweater.
They have a commercial version called Fashionista. Read the original study here.
Predicting Your Next Click
A great many types of data may be seen as strings of data. Certainly the daily temperature at say one hour intervals, stock prices, steams of sensor data, but also unexpected non-numeric strings like text and speech. Another interpretation of ‘string’ is ‘time series’ so text is time series in that each word or even character is dependent in some way on the word before, just as the word after will be dependent on the current word. RNNs are in fact the major technology at work in all types of chat applications both text and speech, both input of questions as well as automated responses.
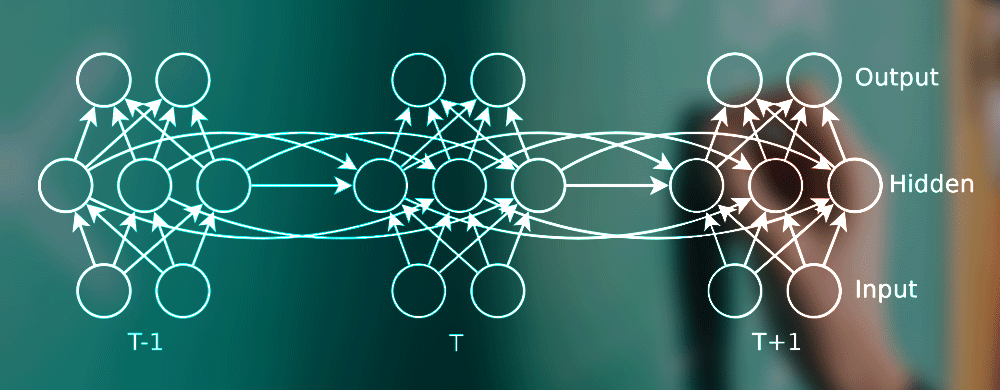
CNNs and almost all other kinds of neural nets assume that each item of input is independent. RNNs assume dependency. For a more thorough review see this article.
In the world of recommenders, Alexandros Karatzoglou, Sr. Research Scientist at Telefonica Research and his collaborators have been using RNNs to predict the next click from a visitor.
The theory they are exploring is that each click during a session on your web site is a series in which the current click is dependent on the prior click and so forth. The value of this is particularly high when you have a cold start user or for example, the site is small and does not require sign in prior to browsing or placing items in the basket. Essentially this means there is no basis for collaborative person – person filtering and all that remains is item-item content filtering.
RNNs are capable of learning from different lengths of prior stream events, not just the immediately prior one. This allows them for example to optimize not just for the next move in the game but also for the many moves taken together that constitute a winning strategy for the game as a whole.
In the past, for each element of prior history that was to be considered an additional hidden layer was added to the RNN. This created a dilution of the original signal known as the disappearing gradient problem and caused early RNNs to frequently fail to train. Recently an advance in RNN architecture called Long Short Term Memory (LSTM) has been added to RNNs which resolves this problem and allows them to be effective over a much longer sequence of inputs.
Like all 2nd generation deep learners, RNNs need to be trained over very large data sets. However, once accomplished the trained RNN was able to predict the next click corresponding to the next item to be viewed. This data was added to the already functional item-item content filter in the same way that image data was appended to the item table in the CNN example above.
The results were quite encouraging with the improved recommender achieving 15% to 30% improvements over the straight content filter. Karatzoglou’s next step will be to combine this approach with the CNN synthetic attribute based on the image of the item and see what improvement that brings.
Are These Ready for Prime Time
It’s fair to say that the application of deep learning to Recommenders is still in the research stage. Nonetheless the examples we offered above have been tested in commercial environments and have shown significant improvement to the Recommenders in which they were implemented. It may not be too early for you to experiment with some of these.
Other Articles in this Series
Understanding and Selecting Recommenders
Recommenders: Packaged solutions or Home Grown
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}