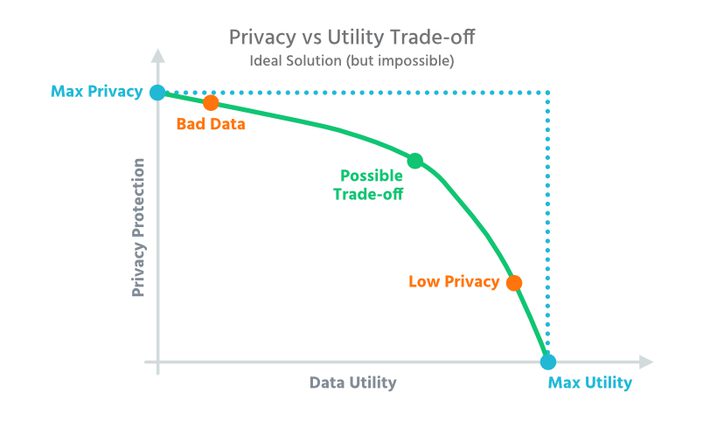
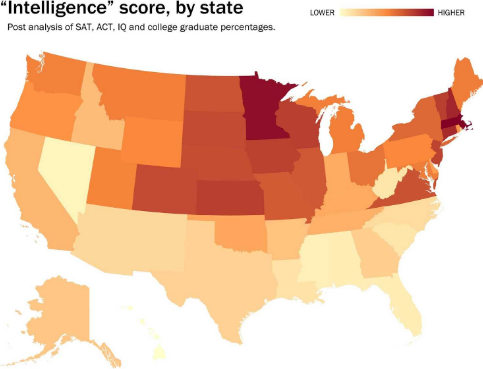
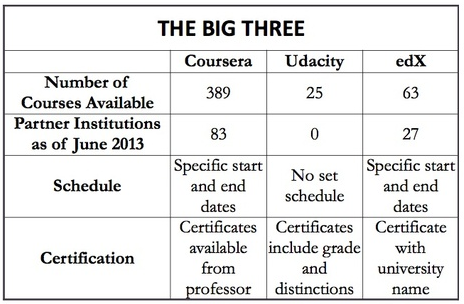
What makes a great CEO? First of all, the answer to that question depends on who raises it: An investor will likely come up with a different answer than an employee. What...
Which company would not like to get significantly improved insights into the market with detailed data and thus optimize its products and services? In most cases, the cor...
Data science has brought new marvelous opportunities to many industries. Along with these possibilities it has also brought constant changes and challenges. Travel and ...
According to technology experts that would have increased from 130 to 40000 exabytes ten and a half years before 2020. Some research writers have estimated that society w...
Introduction This blog is a part of the learn machine learning coding basics in a weekend . We recommend the book Python Data Science Handbook by Jake VanderPlas There ar...
This article is a solid introduction to statistical testing, for beginners, as well as a reference for practitioners. It includes numerous examples as well as illustratio...
Here we describe a simple methodology to produce predictive scores that are consistent over time and compatible across various clients, to allow for meaningful comparison...
It all depends on the classes that you attended. Some are worth listing, some are best not to mention. Here I review of few of these data science curricula, and the impre...
In practice, the Data Scientist wants to know which formula they will write in their Excel sheet when they enter all the data available into it: Bayes’ or usual? The an...
Image recognition and classification is a rapidly growing field in the area of machine learning. In particular, object recognition is a key feature of image classificatio...