
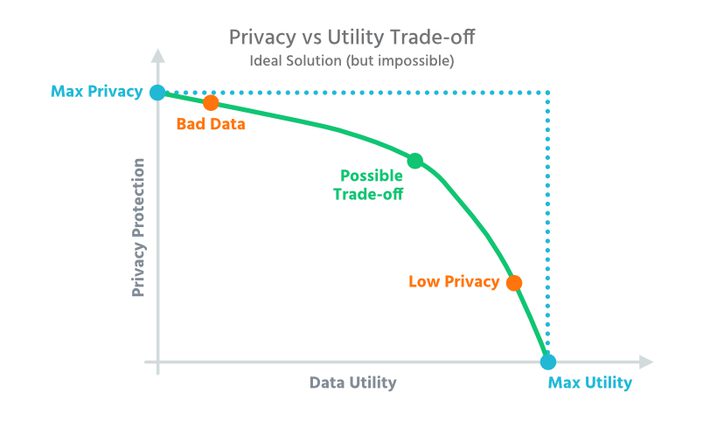
Which company would not like to get significantly improved insights into the market with detailed data and thus optimize its products and services? In most cases, the corresponding data is already available, but its use is often restricted for data protection reasons.
This article first appeared on the Aircloak Blog – feel free to pay us a visit! Aircloak is a company that develops software solutions, enabling the immediate, safe, and legal sharing or monetization of sensitive datasets.
Anonymisation is used when you want to use a data set with sensitive information for analysis without compromising the privacy of the user. Moreover, the principles of data protection do not apply to anonymised data. This means that this information can be analysed without risk. Therefore, anonymisation is an enormously helpful tool for drawing conclusions, for example, from bank transaction data or patient medical records.
Retaining Data Quality and the Misconception of Pseudonymisation
In practice, however, things are less simple: Data records in companies are often anonymised manually. Although special anonymisation tools or anonymisation software are used, many parameters in the corresponding tools must first be determined by experts and then entered manually. This process is laborious, time-consuming, error-prone and can usually only be handled by experts. At the same time, one must choose the lowest possible level of anonymisation, which nevertheless reliably protects the data. Whenever information is removed, the quality of the data record deteriorates accordingly.
Due to the data quality problem, data records in companies are often only supposedly anonymised when they are actually pseudonymised. Pseudonymisation means that personal identification features are replaced by other unique features. This often enables attackers to re-identify the pseudonymised data set with the help of external information (Your Apps Know Where You Were Last Night, and They’re Not Keeping …. For example, pseudonymised data records can be combined with additional information from third-party sources to make re-identification possible (linkability). Likewise, the enrichment of data records classified “unproblematic” can lead to the exposure of sensitive data when you cross-reference it with additional information. [1] Netflix is one company that has had to struggle with such a case: In a public competition, they sought a new algorithm for improved film recommendations. A database with Netflix customers was anonymised and published. However, researchers were able to link it with data from IMDB rankings and thus de-anonymise the users.
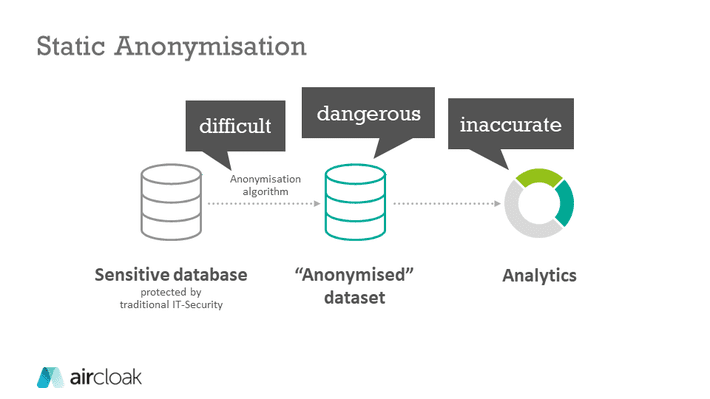
Static Anonymisation – The One-Way- or “Release-and-Forget”-Approach
Almost all anonymization tools can generally be classified into two categories: either they use a static anonymisation or a dynamic anonymisation. With static anonymisation, the publisher anonymises the database and then publishes it. Third parties can then access the data; there is no need for further action on the part of the publisher himself. As already described above, the following things must be carefully considered:
- The list of attributes that must be anonymised (data protection/privacy) and the utility of the data must both be precisely defined.
- In order to ensure the latter, it is crucial to understand the use case for the anonymised data set in detail at this point, because this may better preserve the information quality of the decisive dimensions by accepting a restriction for other, less decisive, data.
- Data is often only pseudonymised. Attackers can thus draw conclusions from the data records by linking them with other information.
Examples of current static (and free) anonymisation tools are:
The website of the ARX Anonymization Tool gives a list of further anonymisation software that works according to the static principle.
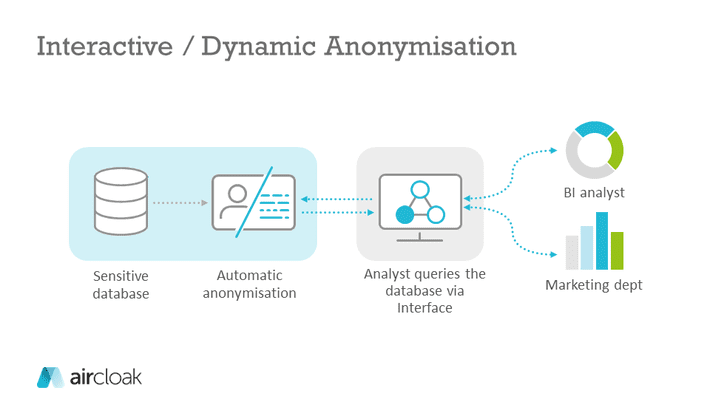
Interactive Anonymisation – Where the Anonymisation is Tailored to the Query
With interactive anonymisation, anonymisation is applied dynamically to the results of a query and not to the entire data set (that’s why we call this procedure “dynamic anonymisation” at Aircloak). The analyst can access a database via an interface and make queries. The anonymisation happens automatically during the query and he receives only anonymised results. This dynamic approach is used for Differential Privacy as well as for Aircloak. Since the results of the queries are changed by noise addition, the number of queries must be limited, at least for differential privacy. Otherwise, it would be possible for attackers to calculate the noise by using simple statistical methods and thus de-anonymise the data set. Aircloak avoids the need of a privacy budget by adding noise tailored to the queries with the framework Diffix.
The great advantage of interactive anonymisation is that the anonymisation is performed automatically and the analyst does not need to have any knowledge of data protection or data anonymisation. This allows the analyst to fully concentrate on evaluating the data.
Of course, it is also possible to create a static dataset from an interactive process: the editor formulates and executes queries for this purpose and the anonymised results are then published. Examples of current anonymisation tools based on the dynamic approach are:
Differential Privacy
Google’s RAPPOR
GUPT
PINQ (and wPINQ)
Harvard Privacy Tools Project: Private Data Sharing Interface
FLEX
Diffpriv R toolbox [2]
Diffix
Which method is better?
Some experts have the opinion that interactive anonymisation tools protect privacy better than non-interactive tools. [3] “Another lesson is that an interactive, query-based approach is generally superior from the privacy perspective to the “release-and-forget” approach”. [4] The probability of poorly anonymised data sets is much higher with static anonymisation due to the very complex selection of data usability/data protection parameters.
Nevertheless, static anonymisation is often sufficient in one-off projects with clearly defined frameworks, preferably in conjunction with further organisational measures. Dynamic anonymisation is particularly suitable in larger projects and with regular use of anonymised data records, where uniform processes and data protection compliance are the highest priority. Ultimately, it always depends on the use case and on how important the privacy of the data is.
Addendum:
“Interactive anonymisation” is not clearly defined. For example, the research paper Interactive Anonymization for Privacy aware Machine Learning describes how an interactive machine learning algorithm interacts with the help of an external “oracle” (e.g., a data protection expert) that evaluates the result of the anonymisation performed by an algorithm and thus makes continuous improvement possible.
By contrast, the Cornell Anonymization Toolkit claims that it is “designed for interactively anonymising published datasets to limit identification disclosure of records under various attacker models”. However, the interactivity here is limited to the fact that the anonymisation parameters can be adjusted in the tool. The result is nevertheless a statically anonymous data set.
1 Leitfaden: Anonymisierungstechniken, Smart Data Forum
2 Differential privacy: an introduction for statistical agencies, Dr. Hector Page, Charlie Cabot, Prof. Kobbi Nissim, December 2018
3 Leitfaden: Anonymisierungstechniken, Smart Data Forum
4 Privacy and Security Myths and Fallacies of “Personally Identifiable Information”, Arvind Narayanan and Vitaly Shmatikov, 2010
{kind=link}