
Why did your chatbot fail miserably ?
Finding the Elusive ‘U’ in NLU Meet Neo ! Neo is a talented developer who loves building stuff. One fine morning , Neo decides to take up a road,… Read More »Why did your chatbot fail miserably ?

Finding the Elusive ‘U’ in NLU Meet Neo ! Neo is a talented developer who loves building stuff. One fine morning , Neo decides to take up a road,… Read More »Why did your chatbot fail miserably ?
At NIPS 2016, there was an unprecedented story building up. Something that got every AI enthusiast agog about an unknown AI startup ‘Rocket AI’. The… Read More »Staying Sane and Optimistic amid the AI hype
This post is ‘not’ intended to teach people how to use popular predictive modelling APIs for free. Although, to your surprise, this isn’t… Read More »Machine learning as a service ? Might lose sleep over this !
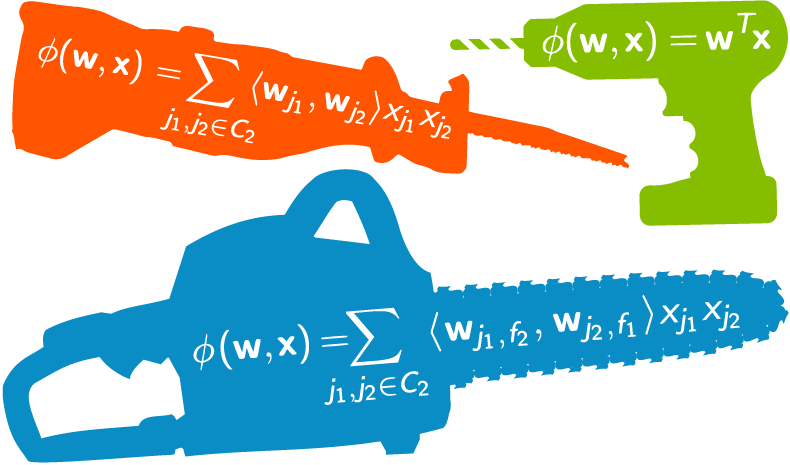
originally posted by the author on Linkedin : Link It is very tempting for data science practitioners to opt for the best known algorithms for… Read More »Feature Engineering: Data scientist's Secret Sauce !

Originally posted on :Linkedin It’s a known fact that bagging (an ensemble technique) works well on unstable algorithms like decision trees, artificial neural networks and… Read More »Random-ized Forest: A new class of Ensemble algorithms

Some of the rarely shared trade secrets in machine learning: Original post: on linkedin 1. Bootstrap sampling & the magic number 0.63 Even though randomly… Read More »Machine Learning : Few rarely shared trade secrets