
At NIPS 2016, there was an unprecedented story building up. Something that got every AI enthusiast agog about an unknown AI startup ‘Rocket AI’.
The names associated with the hot startup were pioneers in the AI field and it was informed to the media that there was major announcement soon to come. There was even a workshop held, where one of the researchers explained about the concept of Temporal Recurrent Optimal Learning to the house full of researchers and media personnel.
The whole community was abuzz with the jargons “Temporally Recurrent Optimal Learning”, “Jacobian Optimized Kernel Expansion”, “Fully Automatic Kernel Expansion”, a couple of which were coined by a leading AI researcher. These made rounds on web with a hype so strong that it got 5 Major VCs reaching out to them for investment.
There were rumours about Rocket AI’s acquisition as well — all within a day.
Only to be figured out, later, to be a joke!
Temporally Recurrent Optimal Learning = TROL
Jacobian Optimized Kernel Expansion = JOKE
Fully Automatic Kernel Expansion = FAKE
If you still don’t get the joke, you should probably get yourself the highly coveted RocketAI T-shirt @$22.99 a piece.
The Rocket AI launch story at NIPS16 was a great lesson on why it is imperative to disentangle noise/hype from the real advancements around a technology on surge.
But let’s be honest, can we inculpate anyone when they fall for the AI ballyhoo? Such hype has always been associated to technologies with potential to change the world. In many ways, it already is. Amidst the extravagant hype, there has been multitudinous success stories as well. Autonomous vehicles, AlphaGo victory over world №1 Go player, OpenAI DOTA2 bot challenging top professional gamers, surge in successful applications in healthcare & fashion owing to advancements in computer vision, is a testimony to the fact that AI has arrived and it’s here to stay.
Of late, there has been a myriad of NLU/NLI/QA datasets crowdsourced and released for the research community. It has undoubtedly propelled the DL research efforts for NLP applications. BABI inspired multiple forms of memory networks, SQUAD/newsQA impelled BiDAF, AOA, mnemonic reader, fusion-net etc, SNLI/MultiNLI,RTE exhorted multitude of attention networks.
However, an agonising trend that concerns me is the over-reliance of young AI practitioners on SOTA (State-of-the-Art) for identical problems. Whether you’re a researcher involved in primary research on AI, a product developer utilising the existing frameworks/algorithms to a given business problem, or an executive evaluating a product, one should always be mindful of the capabilities and limitations of any such SOTA, and its applicability to the given use-case/dataset.
After all, “There are no free lunches in AI”.
Lets have a look at a few observations around the issues with a few popular Datasets used for benchmarking NLU/NLI algorithms and the State of art solutions for them.
Issues with the popular State-of-the-Art solutions and the datasets
- Squad performance State-of-the-Art models dropped drastically after adversarial examples were added in V2.0 compared to V1.1.
- Best performing model on Squad dataset only yields close to 40% f1 Score on NewsQA testSet.
- InferSent seems to rely on word level heuristics for high performance, for SNLI challenge. Most of the contradictory sentences have no overlap in words and with high overlaps, it is more likely to be entailed. This indicates InferSent may be simply learning the heuristic that high overlap could mean ‘entailment’, presence of negation could mean ‘contradiction’. For pairs with high overlap between words with the only token difference among the pair being an antonym, they are classified as ‘contradictions’. Presence of an additional non-antonym word throws the predictions off, classifying it as ‘entailment’.
- Try training a fastText classifier on SNLI dataset and ensure that the model doesn’t get to see the premise but only observes and predicts based on the hypothesis. Be ready to be baffled, because the prediction accuracy would be way higher than some of the baselines! A task which makes no sense to be solved without considering both hypothesis and premise together, it’s quite amusing to find a model doing well without the premise.
- Quantifying determiners and superlatives were mostly included to make the sentences look similar but always present a deviation from the hypothesis. Thus, a ‘contradiction’ in most of the cases.
- Negation, presence of hypernym and hyponym, and overlap of words largely contributed to the entailment class.
These unprecedented benchmarks (SNLI inference problem: train accuracy 95%, test accuracy 91%) might give an illusion that natural language inference is already a solved problem. However, these evidences say otherwise.
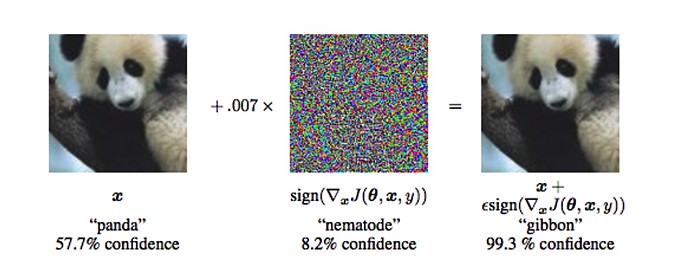
Tesla AI director Andrej Karpathy showed with few simple examples of how a deep-learning model could be fooled, by adding little amount of noise.
Panda gets recognised as gibbon with high confidence.
The results later proved AI still has a long way to go, in making radiologists totally obsolete.

Some interesting excerpts from The former Facebook AI head Yann Lecunn’s interview with Spectrum.



Research frontiers
Lets look at some of the recent AI breakthroughs in computer vision and NLU. Nvidia, OpenAI, Microsoft and Google have been the forerunners.
Below are the image outputs from the OpenAI model which performs Mix-match and Image manipulation. The output is extra-ordinarily high definition and seems natural, although they aren’t real human beings. The third image shows how Nvidia’s model re-creates an unrecognisable object in an extremely blur image automatically.


Source: https://blog.openai.com/glow/ (Image manipulation and Mix-match)

Source: https://www.dpreview.com/news/0229957644/nvidia-researchers-ai-grai…
Learning with lesser data: Meta learning — Meta learning is the process of learning to learn. A meta learning considers a distribution of tasks, and generalises to learn a task efficiently with a very less amount of data. Reptile, MAML are a few popular Meta learning algorithms. Most of the Machine learning usecases at present, are dependent upon supervised approach of Learning, requires a lot of annotated data which is scarce to find. Breakthrough in meta learning approaches can really pave the way to building learning systems which can learn with the very less amount of data, just like how humans learn with substantially small amount of observations.
Automated annotation: There has been a lot of progress in this front, with the evolution of powerful sampling strategies and prediction reliability estimates which can help in sampling a minimum set of instances required to be annotated for the model to approximate a function good enough to replicate the behaviour of the model trained on the full dataset. These frameworks can be applied to automate the annotation process by reducing the manual efforts to a great extent.
Multitask learning: Can you cast each of these NLP tasks as question-answering task and solve it with one network? Question answering, machine translation, summarisation, natural language inference, sentiment analysis, semantic role labelling, zero-shot relation extraction, goal-oriented dialogue, semantic parsing, and common sense pronoun resolution?
Evaluation framework to identify annotation biases: The issues of annotation bias is very much evident by the issues identified in some of the well known public corpuses used for research purpose (SQUAD 1.1, SNLI ). A lot of the existing State-of-the-Art algorithms may not perform high on these datasets if these annotation biases are removed, which will only entice the research community to push the limits and explore better approaches to tackle these problems.
Unsupervised approaches of learning: There has been a lot of research in supervised learning approaches, and its not an unknown fact that given a sizeable training data, it’s no more difficult to train a system to do a varied activities of prediction/recognition/generation etc. The data gathering, annotation, curation is an expansive process and for a lot of real-world problems this becomes a bottleneck.
Unsupervised Sentiment Neuron, Unsupervised Language Modelling using transformers and Unsupervised Pre-training, yielded encouraging results.
Contextual and efficient word representations. Word2vec , Glove & Cove were a good start. FastText made it better, ELmo seems to have surpassed the others based on its performance over a lot of NLU/NLI tasks. The contextual word representation for the words have proved to be quite helpful in downstream tasks.
We are starting to see impressive results in natural language processing with Deep Learning augmented with a memory module. These systems are based on the idea of representing words and sentences with continuous vectors, transforming these vectors through layers of a deep architecture, and storing them in a kind of associative memory. This works very well for question-answering and for language translation
Search for Better optimisers: Using machine learning to find better optimisers proved to be quite beneficial. Optimisers play a pivotal role in the performance of Deep learning architectures. Some of the most commonly used optimisers being Adam, AdaGrad, SGD etc. The search for efficient optimisers is just as important as discovering better optimisation algorithms. Google AI showed that reinforcement learning can be utilised for searching better optimisers for deep learning architectures. PowerSign and AdaSign were discovered using the same, and have proved to quite efficient for many DL usecases.
Zero-shot learning/One-shot learning: Can a supervised learning model be trained to predict a class that is not present or are entirely removed from the training data?
Interpretation vs Accuracy
An interesting debate surfaced up at NIPS 2017, with Ali Rahimi and Yann LeCun locking horns over Rahimi’s remarks of Machine learning becoming the ‘alchemy’. Blaming the present Deep learning systems to be a black box or at best an experimental science, Ali maintained the AI systems need to be based on verifiable, rigorous, thorough knowledge, and not on alchemy. LeCun argued that the “lack of clear explanations does not affect the ability of deep learning to solve problems!” While LRP(layer wise relevance propagation), deep Taylor series and LIME (Local Interpretable Model-Agnostic Explanations) are a few methods being utilised to make these systems explain their predictions, it is still in its nascent stage. Or do we need to settle this debate by saying, “It might just be part of the nature of intelligence that only some part of it is exposed to rational explanation. Some of it is just instinctual or subconscious, or inscrutable.”
The voice in favour of supposedly imminent AI winter is just as strong as the ardent optimists who believe AGI is just around the corner. Although the later may not be likely anytime soon, The former is more likely if AI breakthroughs are overhyped beyond truth.
“AI researchers, down in the trenches, have to strike a delicate balance: Be optimistic about what you can achieve, but don’t oversell what you can do. Point out how difficult your job is, but don’t make it sound hopeless. You need to be honest with your funders, sponsors, and employers, with your peers and colleagues, with the public, and with yourself. It is difficult when there is a lot of uncertainty about future progress, and when less honest or more self-deluded people make wild claims of future success. That’s why we don’t like hype: It is made by people who are either dishonest or self-deluded, and makes the life of serious and honest scientists considerably more difficult.” — Yann Lecunn
Ashish is the VP of AI Product for Active.Ai. Find out what the future holds for Conversational AI at www.active.ai
{kind=link}