New & Notable

Top Webinar
Recently Added
GenAI, RAG, LLM… Oh My!
Bill Schmarzo | May 4, 2024 at 8:22 amI am pleased to announce the release of my updated “Thinking Like a Data Scientist” workbook. As a next step...
7 Cool Technical GenAI & LLM Job Interview Questions
Vincent Granville | April 30, 2024 at 8:44 pmThis is not a repository of traditional questions that you can find everywhere on the Internet. Instead, it is a short s...

DSC Weekly 30 April 2024
Scott Thompson | April 30, 2024 at 1:59 pmAnnouncements Top Stories In-Depth...

How long does it take to master data engineering?
Aileen Scott | April 30, 2024 at 10:48 amData engineers are professionals who specialize in designing, implementing, and managing the systems and processes that ...
Data fitness and its impact potential on enterprise agility
Alan Morrison | April 30, 2024 at 9:42 amIllustration by Dirk Wouters on PIxabay I had the opportunity to attend Enterprise Agility University’s prompt enginee...
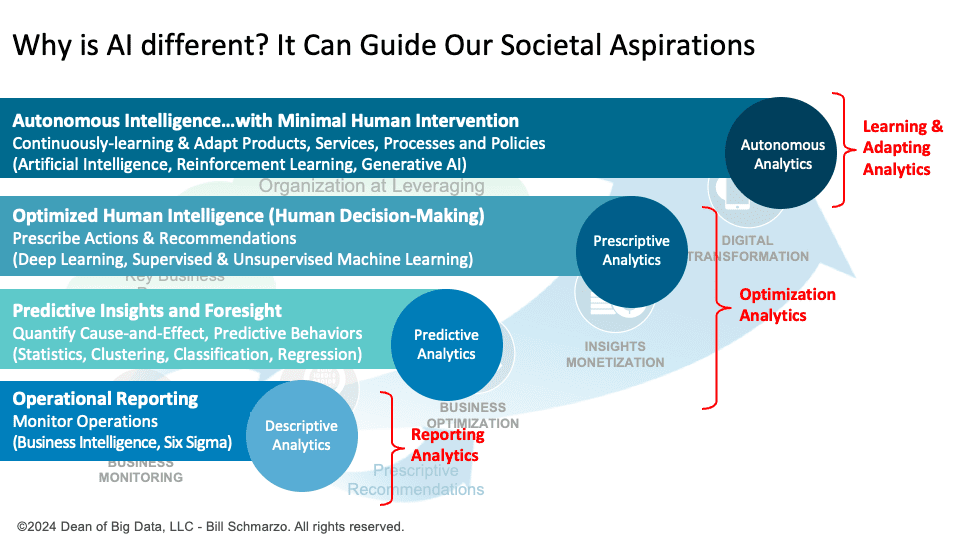
Why is AI different? It Can Guide Our Societal Aspirations
Bill Schmarzo | April 29, 2024 at 11:38 amTraditional analytics optimize based on existing data, reflecting past realities, limitations, and biases. In contrast, ...
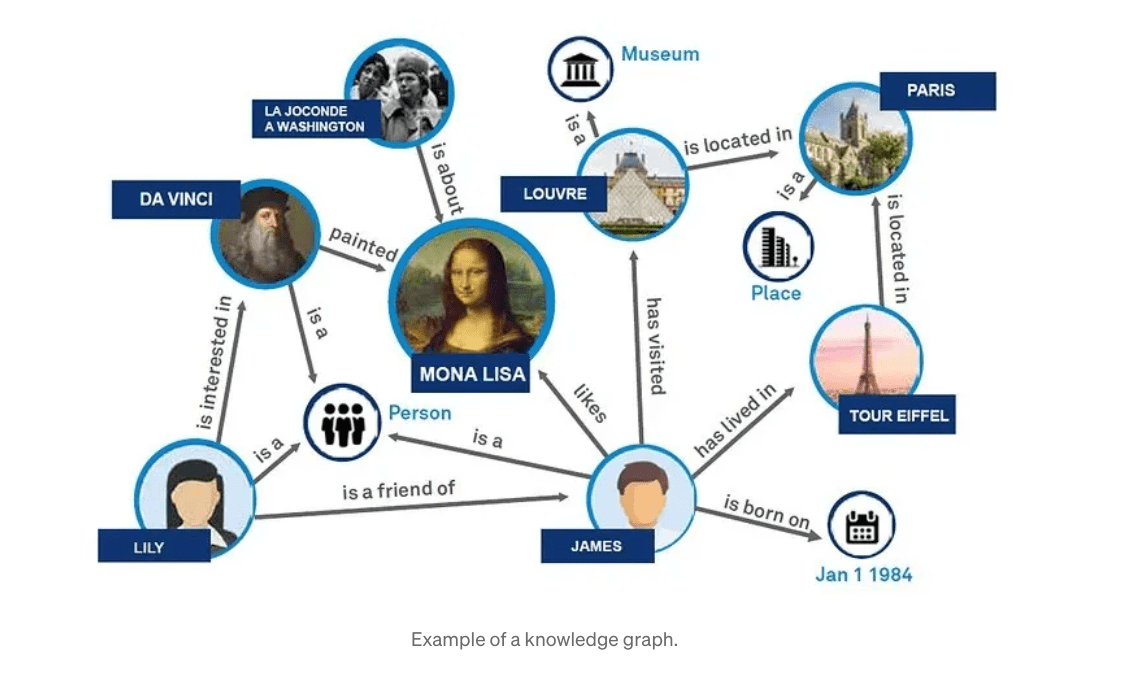
Understanding GraphRAG – 1: The challenges of RAG
ajitjaokar | April 26, 2024 at 1:45 pmBackground Retrieval Augmented Generation(RAG) is an approach for enhancing existing LLMs with external knowledge source...

Optimizing model training: Strategies and challenges in artificial intelligence
Pritesh Patel | April 25, 2024 at 2:51 pmWhen you do model training, you send data through the network multiple times. Think of it like wanting to become the bes...

Top AI Influencers to Follow in 2024
Vincent Granville | April 25, 2024 at 1:28 amThere are many ways to define “top influencer”. You may just ask OpenAI to get a list: see results in Figure...

Losing control of your company’s data? You’re not alone
Alan Morrison | April 24, 2024 at 1:10 pmPhoto by Hermann Traub on Pixabay Losing control of your company’s data? You’re not alone To survive and thr...
New Videos

Cybersecurity practices and AI deployments
For our 4th episode of the AI Think Tank Podcast, we explored cybersecurity and artificial intelligence with the insights of Tim Rohrbaugh, an expert whose career has traversed the Navy to the forefront of commercial cybersecurity. The discussion focused on the strategic deployment of AI in cybersecurity, highlighting the use of open-source models and the benefits of local deployment to secure data effectively.
Implementing AI in K-12 education
Roundtable Discussion with Rebecca Bultsma and Ahmad Jawad In the latest episode of the AI Think Tank Podcast, we ventured into the rapidly evolving intersection…
Retrieval augmented fine-tuning and data integrations
Presentation and discussion with Suman Aluru and Caleb Stevens In the latest episode of the “AI Think Tank Podcast,” I had the pleasure of hosting…