

I am pleased to announce the release of my updated “Thinking Like a Data Scientist” workbook. As a next step, I plan to work on a supplemental workbook incorporating GenAI tools like OpenAI ChatGPT, Google Gemini, and Microsoft Copilot with the Thinking Like a Data Scientist approach. We need to improve our prompt engineering skills to get started with this process.
Prompt engineering is the practice of carefully crafting inputs to optimize the performance and accuracy of responses from large language models (LLM).
Integrating Generative AI (GenAI) tools with the “Thinking Like a Data Scientist” (TLADS) methodology requires an understanding of prompt engineering. Using more relevant prompts, we can direct the GenAI tools to focus on specific hypotheses, test assumptions, and generate analyses aligning with our strategic business goals. Prompt engineering facilitates the iterative hypothesis generation and testing process, which is central to TLADS. It enhances the quality of insights by ensuring that the outputs from GenAI tools are relevant and strategically valuable in light of the targeted business initiative and supporting use cases. By tailoring prompts according to TLADS principles, we can bridge the gap between raw data and strategic insights, optimizing the business value derived from AI technologies.
Levels of Prompt Engineering Mastery
Prompt engineering is vital for creating prompts that utilize large language models (LLMs) for specific business and operational initiatives. The process of prompt engineering involves four levels of development, each building on the capabilities and understanding gained from the previous level (see Figure 1).
- Level 1: Prompt Engineering on Public LLMs. This foundational level involves learning how to create effective prompts from general-purpose LLMs such as OpenAI’s ChatGPT. It is an excellent starting point that emphasizes understanding how prompts impact responses and fueling experimenting with different prompt styles to observe the limitations and biases of these public LLMs.
- Level 2: Retrieval-Augmented Generation (RAG). RAG involves integrating external, validated data sources to enhance the quality and accuracy of responses from LLMs. Level 2 requires understanding how to leverage credible databases, documents, or trusted Internet sites to fetch relevant information that enhances the LLM’s base knowledge to deliver more relevant and accurate responses.
- Level 3: Fine-Tuning. This level refers to the process of customizing a language model (LLM) to improve its performance and relevance for specialized tasks on a specific dataset. This could involve training the model to better suit a particular domain, adapting it to reflect an organization’s unique tone and style, or tailoring it to meet the specific needs of a market or operational niche.
- Level 4: Custom, Proprietary LLMs. Developing custom, proprietary LLMs represents the highest level of prompt engineering maturity. Organizations create these LLMs based on their own exclusive data and knowledge sources. This process involves careful data curation, experimentation with various architectures, and significant computational resources.
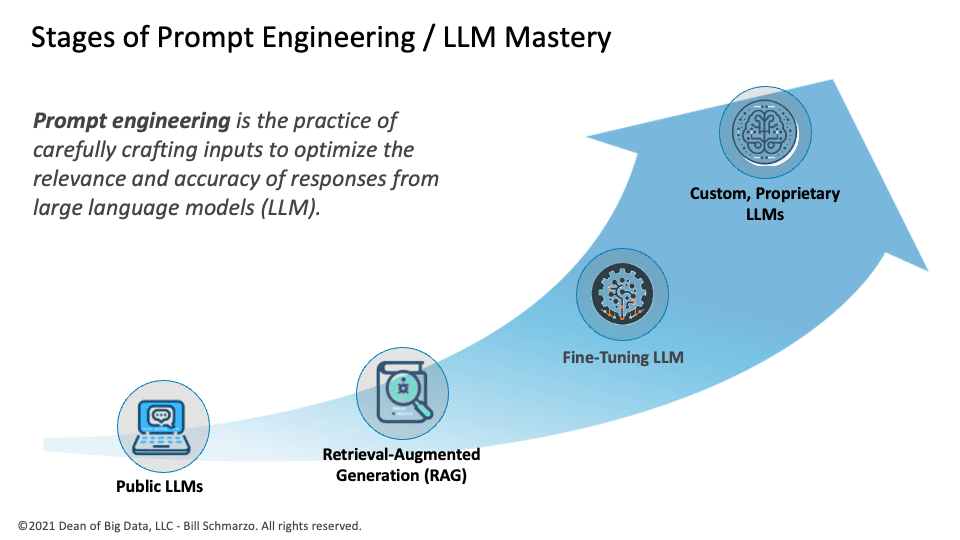
Figure 1: Stages of Prompt Engineering / LLM Mastery
As organizations strive to master prompt engineering, some important factors they should consider include 1) continuous learning and model updating and 2) ethical considerations and bias mitigation.
LLM Continuous Learning and Updating
Continuous Learning and Model Updating focus on keeping models’ accuracy and effectiveness intact over time as new data emerges or conditions evolve. This process is critical for maintaining the relevancy and accuracy of LLMs. It is also connected to Step 8 in my recent book, “The Art of Thinking Like a Data Scientist: Second Edition.”
- Data Monitoring: Regularly monitor input data and model responses to identify shifts in data patterns or emerging inaccuracies in outputs.
- Model Evaluation: Continuously assess the model’s performance using metrics that can signal when the model starts to drift or underperform.
- Feedback Loops: Implementing mechanisms to collect feedback, either from users or automated systems, to inform adjustments in the model.
- Update Strategies: Develop strategies for retraining or fine-tuning the model based on new data or after identifying performance issues. This can involve incremental learning, where the model is periodically updated with new data without retraining from scratch.
- Testing and Validation: Before deploying updated models, rigorous testing ensures that changes improve the model without introducing new problems.
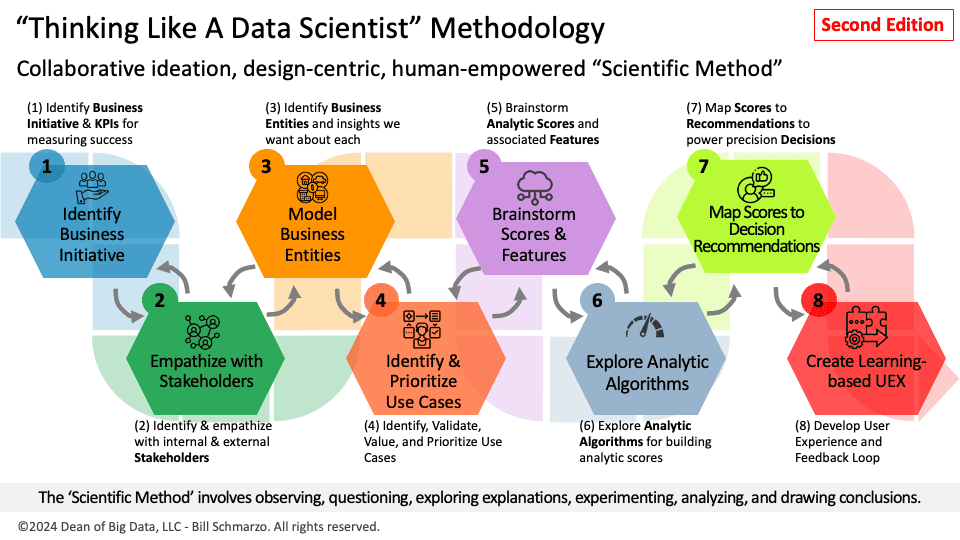
Figure 2: “The Art of Thinking Like a Data Scientist Second Edition”
Users Role and Responsibilities
It is crucial for users to actively participate in the continuous learning cycle of large language models (LLMs) to ensure that these models stay relevant, accurate, and aligned with the evolving real-world applications. This includes the following:
- Providing Feedback: Users monitor and report discrepancies or shortcomings in the model’s performance. For example, an editor using a text-generating AI might note and report that the model frequently misinterprets technical jargon, prompting necessary refinements.
- Validating Outputs: Users ensure that the model’s outputs remain accurate and practical for real-world applications. For instance, a user employing an AI for stock market predictions would verify the AI’s forecasts against actual market movements to ensure reliability.
- Guiding Adjustments: Users play a crucial role in shaping the model’s development by providing specific insights on how it can better meet their needs. For example, a teacher using an educational AI could suggest enhancements to better align the AI’s tutoring responses with curriculum standards.
Reinforcement Learning through Human Feedback (RLHF) is a machine learning technique that utilizes human input to improve an LLM’s performance. RLHF combines reinforcement learning with feedback from people to create a more precise and reliable model. It is an automated companion that ensures our LLMs continually learn and improve through human feedback via:
- Training Signal from Human Feedback: In RLHF, the model adjusts its algorithms based on positive or negative feedback from human evaluators, learning to replicate successful outcomes and avoid errors.
- Iterative Improvement: This method emphasizes iterative adjustments to the model, closely aligning with the principles of continuous learning.
TLADS Step 8: Create a Learning-based User Experience
In my updated TLADS, Step 8 is focused on creating a learning-based User Experience (UEX) that leverages algorithmic learning with human learning to enhance decision-making processes. It accomplishes that by focusing on two aspects of creating a learning-based user experience (Figure 3).
- Integrative Feedback Systems: Part of creating a learning-based UEX involves integrating feedback mechanisms that improve user experience and feed valuable data into the model.
- User-Centric Design: Ensuring that the model updates and learning processes are driven by user needs and behaviors, creating a more effective and intuitive user experience.
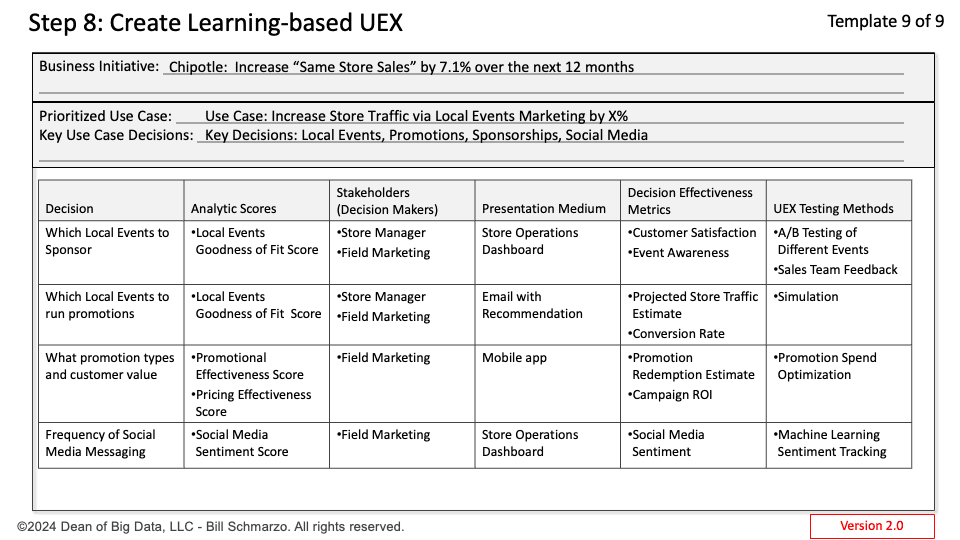
Figure 3: TLADS Step 8: Create a Learning-based User Experience (UEX)
GenAI, RAG, LLM Summary
I am thrilled to be working on a supplement to my recently published second edition of “The Art of Thinking Like a Data Scientist” (TLADS) workbook. The supplement will explore integrating GenAI tools like OpenAI ChatGPT with the TLADS methodology to generate more accurate, meaningful, relevant, responsible, and ethical AI outcomes.
Our goal of integrating GenAI with TLADS begins with prompt engineering, which involves the process of crafting GenAI requests. These requests should not only drive but also significantly enhance the output quality of large language models (LLMs). With this alignment between GenAI and TLADS, we can encourage the exploration, imagination, and creativity necessary to deliver more relevant, meaningful, responsible, and ethical AI outcomes.
As we progress through the levels of prompt engineering mastery, from simple interactions with public LLMs to developing complex and exclusive models, we uncover a path of growth and depth in how we interact with GenAI tools. With each level, we get closer to a deeper integration where our prompts become more than just inputs; they become conversations that guide AI to generate accurate insights aligned with our specific business needs. This journey involves continuous learning and ethical diligence, ensuring that as our models learn and evolve, they do so by upholding values that respect and enhance user trust and regulatory compliance.