
Customer success stories illuminate how hardware accelerators speed up the necessary infrastructure to support all aspects of an accelerated AI and HPC computing data center.
Customer success stories illuminate how hardware accelerators speed up necessary infrastructure to support all aspects of an accelerated AI and HPC computing data center.
The real-world impact of accelerated AI technology extends far beyond any single data center or workload. While undeniably important, AI technology is but one of several software components that now comprise what experts term the 5th epoch of distributed computing. [1] [2]
To meet both productivity and efficiency goals, commercial, academic, and HPC data centers rely on heterogeneous computing environments that utilize computational accelerators to speed the tsunami of fast-becoming-ubiquitous AI-based workloads. Cloud computing represents an off-premises alternative that is now the go-to solution for many commercial AI workloads. Cloud computing is also being considered as an additional (and even replacement) platform for some HPC workloads. All this accelerated computational performance can be rendered useless if the data center, cloud provider, or hardware procurement does not address the data management aspects of user workloads.
The key concepts to realize the benefits of heterogeneity and accelerators were discussed in the previous articles in this series (The 5th Epoch, Multiarchitecture Software Frameworks, Investment Guidelines). Succinctly, Intel and the Exascale Computing Project (ECP) have both taken leadership roles in the creation of general-purpose and mutually compatible software frameworks that others can use to achieve performance portability across many data centers (e.g., oneAPI and E4S).
Experts Explain the Data Conundrum
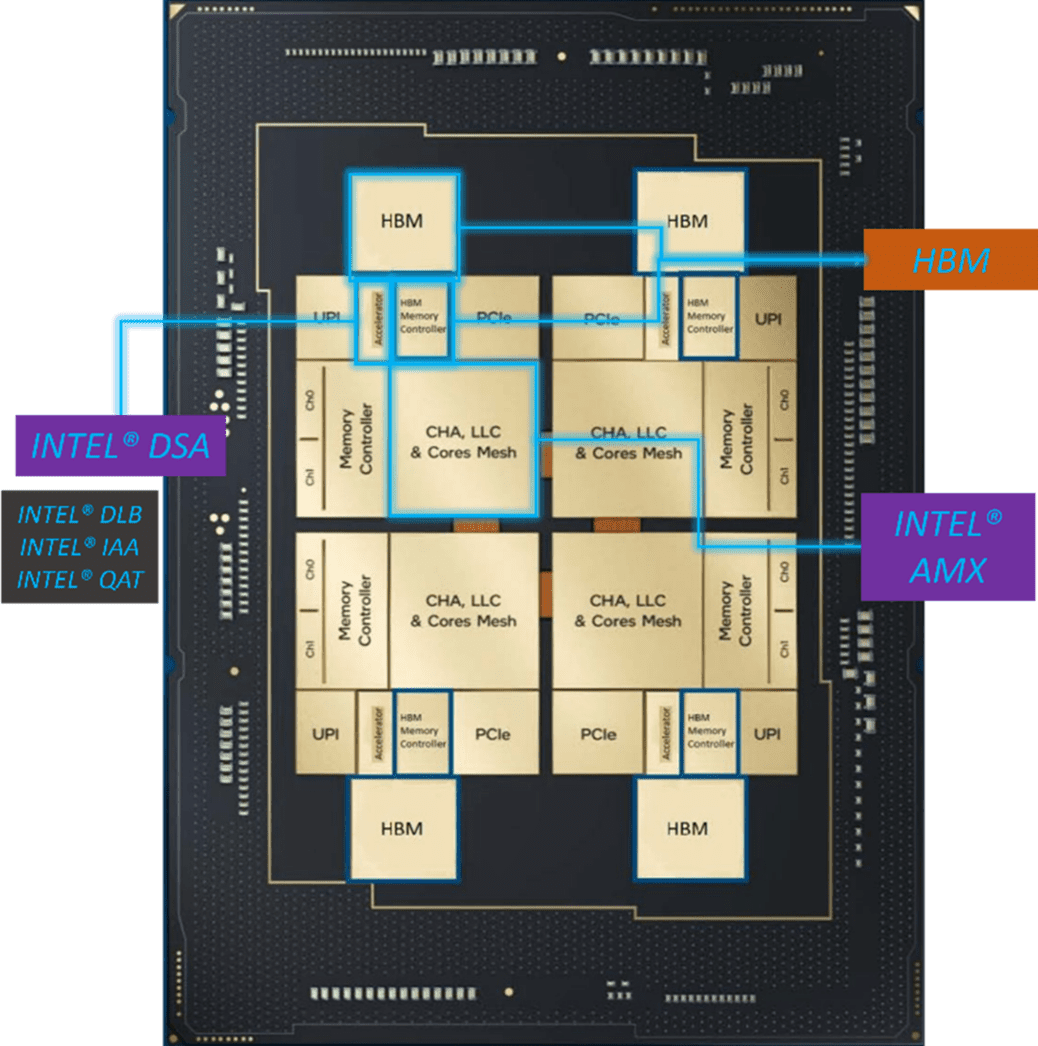
The extreme scale of exascale supercomputers highlights the challenges that must be addressed by accelerated computational devices. All currently announced DOE exascale supercomputers utilize GPUs to achieve their high floating-point performance on AI and HPC workloads. These hybrid systems are inherently unbalanced as the computational accelerators can deliver orders of magnitude greater parallelism and data throughput than their corresponding storage subsystems.[3] This requires new approaches to working with data as exemplified by the addition of multiple on-package CPU accelerators, some of which are focused on data security and management (Figure 1).
Although High bandwidth memory (HBM) is not in itself considered an accelerator, memory bandwidth needs to be considered. As Mark Kachmarek (HPC marketing manager, Intel) noted in his HBM overview presentation, “Memory BW [Bandwidth] sensitive workloads get accelerated performance benefit from High Memory Bandwidth.” [4] Similarly, the addition of Intel advanced matrix extensions (AMX) can greatly accelerate the performance of reduced-precision machine learning workloads. Overall, HBM and Intel AMX plus AVX-512 can increase the efficiency of these with computational accelerators to provide new levels of mobility, security, and performance.[5] It can also make CPUs — as opposed to GPUs — the platform of choice for many HPC and AI workloads.
Customers Need to Interact and Collaborate
CS Chang (Managing Principal Research Physicist at Princeton Plasma Physics Lab) is preparing to run his code on the Aurora supercomputer equipped with the Intel Xeon CPU Max Series and Intel GPU Max Series. He observed that a very important aspect of extreme-scale computing assisted by AI is the creation of surrogate models that can return results in minutes rather than days spent waiting for big, large-scale simulations.
Chang observed, “from the large-scale simulation data, we are beginning to build surrogate models.” These surrogate models utilize machine learning to produce a very simple formula from big simulation data.” Chang continued, “there are many, many of those problems in fusion where surrogate models are just as good as the physics they’re putting into it. PPPL [Princeton Plasma Physics Laboratory] scientists have created an AI model which reduces the [runtime from] days into just minutes.”
Customers also Need to Visualize, Interact, and Train
Also preparing to run on the Argonne National Laboratory managed Aurora exascale supercomputer, Amanda Randles, (Alfred Winborne Mordecai and Victoria Stover Mordecai Associate Professor of Biomedical Engineering at Duke University) noted, “We’re working with the Argonne teams to try to create techniques and capabilities to visualize the data, interact with the data, use it to train machine learning models while it’s still in memory on the system, and really make use of it without having to store it after the fact.”
We’re working with the Argonne teams to try to create techniques and capabilities to visualize the data, interact with the data, use it to train machine learning models while it’s still in memory on the system, and really make use of it without having to store it after the fact. – Amanda Randles, Alfred Winborne Mordecai, and Victoria Stover Mordecai Associate Professor of Biomedical Engineering at Duke University
Randles continued, “We’re just getting into the machine learning and artificial intelligence side of things. The goal is run a minimal number of simulations per patient, train a machine learning model, and then be able to predict and infer what other instances, like what other physiological conditions there may be, and to kind of optimize our use of the resources on that end.”
HPC, Cloud, and Industry Stories
Numerous academic, government, and enterprise customer stories highlight the need for AI data and security-related accelerators to enhance their HPC efforts.
The Texas Advanced Computing Center
TACC is a leading academic supercomputer research facility.
When evaluating hardware for their next procurement, TACC observed that Intel Xeon Max processors with High Bandwidth Memory (HBM) can provide significant performance benefits. These are the processors that were chosen to support future academic research across the U.S. as part of the recently announced a $10M U.S. National Science Foundation (NSF) grant for the new Stampede3 supercomputer. “We believe the high bandwidth memory of the Intel Xeon CPU Max Series nodes will help deliver better performance than any other CPU that our users have seen before,” TACC director Dan Stanzione said. “They offer more than double the memory bandwidth performance per core over the current 2nd and 3rd Gen Intel Xeon processor nodes in Stampede2.”
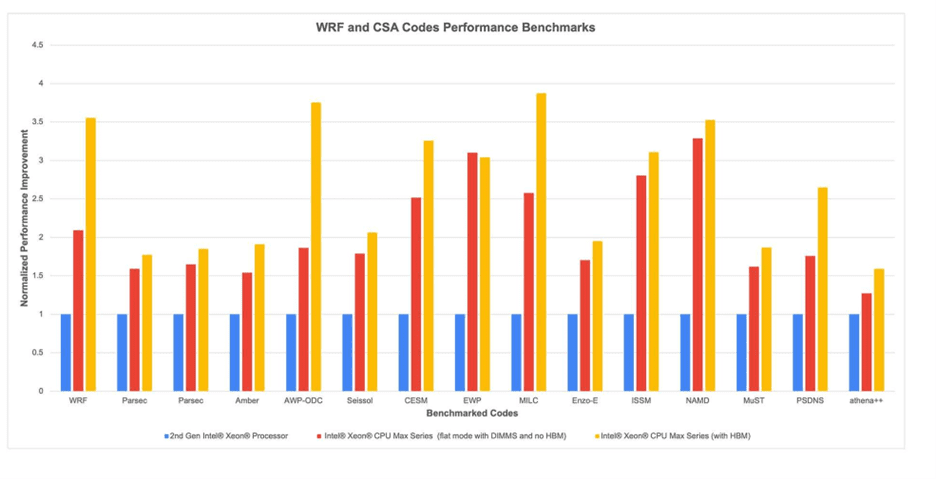
The 14 applications that were assessed include widely used codes from the earthquake and astrophysics communities, software for large international experiments and custom codes that explore innovative approaches to machine learning and black hole modeling. Performance results are shown in Figure 2.
A special configuration of the Community Earth System Model (CESM) developed by the NSF-sponsored EarthWorks project also demonstrated notable performance improvements when running on an HBM-enabled processor with internal accelerators.
CESM is one of the principal climate codes used by the earth science community. It is developed and maintained by the National Center for Atmospheric Research (NCAR) in collaboration with the research community. The TACC benchmarks found that the EarthWorks configuration of CESM ran 2.5× faster on the Intel Xeon CPU Max Series with DDR5 memory than on Frontera. This same code achieved a further 30 percent improvement (to 3.2×) in HBM-only mode.
TACC also observed the 3D earthquake code developed by Yifeng Cui of the San Diego Supercomputer Center, the Anelastic Wave Propagation (AWP) code, ran significantly faster on an HBM-enable Intel Xeon CPU with accelerators. TACC determined this code ran 3.7× faster on Intel Xeon CPU Max Series than on Frontera and showed a 100 percent boost with HBM.
Addressing Regulatory and Privacy Requirements
To create successful algorithms for use in healthcare, financial, government and other institutions, developers need to find ways to make their models generalizable to diverse populations even when confronted with stringent regulatory and privacy requirements.
Equideum Health
Equideum Health provides one customer story that utilizes Intel Software Guard Extensions (Intel SGX shown in Figure 1) to support their Data Integrity and Learning Networks (DILNs). According to Equideum, “The lack of a unified, comprehensive health record for each individual renders effective data analysis nearly impossible. To perform high-quality, trusted analytics, stakeholders must engage in multi-party data sharing, which introduces privacy and security risks.” Through the use of blockchain and AI technology, researchers can work with data compartmentalized among stakeholders such as health insurance companies, pharmacies, provider offices, health systems, and laboratories.[7]
Ropers Majseki
The law firm of Ropers Majeski partnered with Intel, Activeloop and ZERO Systems to create a secure AI-driven solution. Embedded accelerators such as Intel Advanced Vector Extensions 512 (Intel AVX-512) in the 4th generation of Intel Xeon Scalable Processors provided the performance and efficiency gains to run a custom Large Language Model (LLM) so the customer did not have to invest in a proprietary solution. This coupled with a secure, enterprise-grade database for AI made it possible to store both embeddings and multi-modal data for millions of sensitive documents and provided advanced role-based access controls. The system was able to boost worker productivity while meeting strict regulatory and security requirements. “This kind of strategic partnership is just the beginning of integrating generative AI into the legal profession and other highly regulated industries.” Said Gevorg Karapetyan, Co-founder and CTO of Zero Systems.
Accelerated Instruction Set Architectures (ISAs)
On-package and on-chip accelerators are also making CPUs competitive with GPUs in terms of computational performance for many AI workloads. The following customer stories reflect the benefits of this trend.
The Laboratory for Laser Energetics at the University of Rochester
Scientists at the Laboratory for Laser Energetics (LLE) at the University of Rochester are studying and experimenting with inertial confinement fusion (ICF) to harvest energy from the same process that powers stars. The new LLE processor-based Conesus system helps scientists explore machine learning and artificial intelligence (AI) technologies to garner insight into how to harvest power from nuclear energy. William Scullin, HPC Lead at LLE, expects scientists will take advantage of Intel Advanced Vector Extensions 512 (Intel AVX-512), which provides significant acceleration for floating point calculations.
Numenta
Numenta has developed technology to accelerate inference performance for Natural Language Processing applications that customers utilize to analyze extensive collections of documents. Numenta leverages Intel AMX to achieve high inference performance on production-ready Transformer models – from BERTs to multi-billion parameter GPTs — without using a GPU. Numenta observed a 35× throughput improvement versus NVIDIA A100 GPUs for BERT-Large inference on short text sequences and batch size.[8] [9] [10] Batch size 1 is ideal for low-latency inference applications used in production NLP workloads as this batch size provides the most flexibility in real-time scenarios where input data constantly changes.
Siemens
Siemens is using 4th Gen Intel Xeon Scalable processor with Intel Advanced Matrix Extensions, and the Intel Distribution of the OpenVINO Toolkit to support radiation therapy professionals with AI-based auto contouring technology. The company claims they can increase workload efficiency, improve consistency, and help free up staff to focus on value-adding work.
Taboola
Taboola is using Intel AMX accelerated processors to deliver targeted content and recommendations that are most relevant to each Internet visitors’ unique preferences. “We are the cloud for our customers, and we need a CPU that is flexible, versatile, and efficient, so it can perform multiple jobs,” explained Ariel Pisetzky (Taboola’s VP of Information Technology & Cyber), “It [the CPU] needs to be able to scale up and down through the day in terms of power use and have enough memory to do in-memory calculations that we need done really fast.”
Summary
The 5th epoch of computing provides many AI benefits, but only when the data security and accessibility infrastructure are also accelerated to meet user needs. Gordon Moore, anticipated this 5th epoch day of reckoning when we will need to build larger systems out of smaller functions, combining heterogeneous and customized solutions. [11] Happily, many of these solutions fit nicely into small, power-efficient packages. More than that, specialized hardware accelerators help facilitate AI and HPC applications across data silos that have severe restrictions on data sharing.
Rob Farber is a global technology consultant and author with an extensive background in HPC and machine learning technology.
[1] https://www.datasciencecentral.com/ushering-in-the-5th-epoch-of-distributed-computing-with-accelerated-ai-technologies/
[2] https://www.youtube.com/watch?v=27zuReojDVw
[3] https://www.exascaleproject.org/supporting-scientific-discovery-and-data-analysis-in-the-exascale-era/
[4] See https://www.intel.com/content/www/us/en/content-details/762147/video-high-bandwidth-memory-hbm-overview.html?wapkw=hbm at time 2.52.
[5] https://www.nextplatform.com/2021/10/21/how-high-bandwidth-memory-will-break-performance-bottlenecks/
[6] Applications compared by TACC were WRF CONUS 2.5km, Parsec liquid_water_64H2O_0.3A, Parsec Si1947H604_0.9A, Amber STMV_production_BP4_4fs, AWP-ODC Fortran, Seissol tpv5_1node, CESM PFS_Ld5_P56.mpasa120_mpasa, EWP MgB2_16, MILC grid 32x32x32x32, Enzo-E 128^3 root mech 512 root blocks, ISSM test435, MuST muffin_56x32, PSDNS 768x768x768, Plascom, and athena++. These were run on systems installed at TACC that use Intel® Xeon® 8280, Intel® Xeon® Max 9480 (Flat Mode, DDR only), and Intel® Xeon® Max 9480 (HBM only). TACC observed a 2.6x average performance increase from Frontera (Intel® Xeon® 8280) to Intel® Xeon® Max 9480 (HBM only) on these workloads.
[7] https://www.intel.com/content/www/us/en/customer-spotlight/stories/equideum-health-customer-story.html
[8] For more, see: https://www.intel.com/content/www/us/en/products/details/processors/xeon/max-series.html Numenta BERT-Large: AMD Milan: Tested by Numenta as of 11/28/2022. 1-node, 2x AMD EPYC 7R13 on AWS m6a.48xlarge, 768 GB DDR4-3200, Ubuntu 20.04 Kernel 5.15, OpenVINO™ Toolkit 2022.3, BERT-Large, Sequence Length 512, Batch Size 1. Intel® Xeon® 8480+ processor: Tested by Numenta as of 11/28/2022. 1-node, 2x Intel® Xeon® 8480+ processor, 512 GB DDR5-4800, Ubuntu 22.04 Kernel 5.17, OpenVINO™ Toolkit 2022.3, Numenta-Optimized BERT-Large, Sequence Length 512, Batch Size 1. Intel® Xeon® Max 9468 processor: Tested by Numenta
[9] Tested by Numenta as of 03/22/2023. 1-node, pre-production platform with 2x Intel® Xeon® 8480+ processor, 512 GB DDR5-4800, Ubuntu 22.04 Kernel 5.17, OpenVINO™ Toolkit 2022.3, Numenta-Optimized BERTLarge, Sequence Length 128, Batch Size 1.
[10] For more, see: https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow/LanguageModeling/BERT#inference-performance-nvidia-dgx-a100-1x-a100-40gb
[11] https://www.datasciencecentral.com/ushering-in-the-5th-epoch-of-distributed-computing-with-accelerated-ai-technologies/#_edn2
{kind=link}