
Without using any API or any Python library, yet delivering better results. You would think this is a massive undertaking. However, it took me less time than exploring and mastering all the tools and platforms out there. Of course, it is better for my personal needs and for many other professionals with similar interests, but not for everyone. It does not replace OpenAI / GPT for the general public: that was not the goal. But it symbolizes a new trend: the rise of the more performant, customized LLM (Large Language Model). I call it XLLM, for Extreme LLM. Its strengths: fast, efficient, scalable, flexible, replicable, with a simple architecture.
You can compare it to extreme rock climbing: summiting mount Everest in winter, solo, and with no oxygen. It has been done! The benefits: a lot faster, far less expensive, and much more flexibility in your itinerary.
The Motivation Behind XLLM
It started originally when none of the platforms could really help me when looking for references and related content. My prompts or search queries focus on research and advanced questions in statistics, machine learning, and computer science. I need answers that I can integrate in my articles and documentation, coming from trustworthy sources. Many times, all I need are relevant keywords or articles that I had forgotten, was unaware of, or did not know were related to my specific topic of interest. And use these sources to further extend my search.
I knew my answers were there on the Internet. But I felt I was spending too much time searching, a task that I could automate. Even the search boxes on target websites (Stack Exchange, Wolfram, Wikipedia) were of limited value. OpenAI did not return links. Google, Bart and Edge were hit and miss. Thus I decided to automate this on my own.
When Small Works Better
Probably one of the biggest improvements — I thought — would be the ability to search by top category, fine tune parameters such as relevancy score to my liking, and also show results that the algorithms deemed less important. Rather than downloading the whole Internet, my idea was to select the best sources in each domain, thus drastically reducing the size of the training data. Oversized crawls produce dilution and do not work as well. What works best is having a separate LLM with customized rules and tables, for each domain. Still, it can be done with massive automation across multiple domains.
Instead of focusing mainly on webpage content, the core piece of my architecture is a high quality taxonomy. In my case, man-made and with more than 5,000 categories just for the math domain. The idea was to reconstruct the best existing one via crawling, then add webpages and important navigation tools gathered on these pages: related content, indexes, tags, “see also” links, and so on.
The first encouragement came when I was able to download massive websites in little time: the whole Wolfram only has 15,000 webpages, totaling about 1 GB before compression. It represents 1% of the human knowledge. In addition, it is relatively well structured. While Wikipedia has millions of entries, it only has thousands related to ML, just to give an example. And it has a taxonomy structure similar to Wolfram, albeit of lower quality. So you can download only what you need (a tiny fraction), no more.
In the end, the idea was to blend large repositories such as Wolfram or subsets of Wikipedia, book content (my own books to begin with), and more. And using new sources to complement word embeddings and taxonomy entries built so far, to generate more comprehensive results. In short: RAG, that is, retrieval, augmentation and generation.
Why not Using Existing LLM Libraries?
I will certainly leverage pre-crawled data in the future, for instance from CommonCrawl.org. Apparently, OpenAI relies on it. However, it is critical for me to be able to reconstruct any underlying taxonomy.
As for Python libraries, I tried a few for standard NLP tasks. All had undesirable side effects and need remediations or tricks before I can rely on them. Probably a reason why many search tools are rather poor. For instance, Singularize turned “hypothesis” into “hypothesi”, while it correctly deals with mice –> mouse. I used Autocorrect to fix this, and it worked, but then it changes “Feller” (a well-known statistician) to “seller”. There are workarounds, such as having do-not-singularize and do-not-autocorrect lists. I have yet to find ones that are relevant to my domain of interest.
Same with stop words available in NLTK. In my case, “even” is not a stop word, because of “even number” or “even function”: you can not erase it in this particular context. Regarding singularization, I use my own trick for now: if both “hypothesi” and “hypothesis” are found during crawling, I only keep the former. Of course, only the latter shows up in this case. While this trick is in principle inferior to using Python libraries, in practice I get better results with it.
The Architecture Behind XLLM
It has two versions: XLLM-short for end users, and XLLM for developers. The short version loads the final summary tables, while the full version processes the full crawled data and produces the final tables. Both return the same results, if you use the most recent version of the tables in the short version. Here I describe the long version, in a few simple steps and components. The break-down is as follows:
- Select sources to crawl, especially large high-quality repositories with a good existing taxonomy. In this case I chose Wolfram as the starting point. The next step is to add my books and a subset of Wikipedia: the categories that I am interested in. The crawled content is organized by category, with a cross-category management system. The end user can select specific categories when using the app.
- Extract relevant information from the crawled data: categories, tokens, links, tags, metadata, related items and so on. Build a word dictionary consisting of successive tokens within a same sentence, title or category item: this is your core table.
- Compute token or multi-token associations, for instance using the PMI metric (pointwise mutual information), to produce the embeddings table. Like many tables, its index (words) coincides with that of the dictionary. Additional tables include related content and categories for each dictionary word. I organized each table as an hash of hash. The key to the root hash is a word, and the value is the nested hash. The latter contains all the items attached to the word in questions (for instance, categories), while each value is a count (number of occurrences).
- Allow for easy updates of all tables when adding new crawls. In particular, potentially creating new categories, or detecting existing categories for a new keyword. In a crawl mix, each source should have its own weight.
- Parse the user query: look for all subsets of n-grams that have a match in the sorted dictionary. Retrieve the information from the tables.
The Devil is in the Details
Accented characters, stop words, autocorrect, stemming, singularization and so, require special care. Standard libraries work for general content, but not for ad-hoc categories. For instance, besides the examples that I discussed, a word like “Saint” is not a desirable token. Yet you must have “Saint-Petersburg” as one token in your dictionary, as it relates to the Saint Petersburg paradox in statistics.
Using a single n-gram as a unique representation of a multi-token word is not good, unless it is the n-gram with the largest number of occurrences in the crawled data. Capital letters do matter. A comma or point can not be ignored. The list goes on and on, but now you have a picture of what could go wrong. Incidentally, there is no neural networks, nor even actual training in my system. All tables are category-specific, even the stop words. Reinforcement learning is important, if possible based on user interactions and his choice of optimal parameters when playing with the app.
It would be interesting to test available APIs on customized crawls (even OpenAI), and check whether and how they can help.
Illustration, Source Code, Monetization
The picture below shows the results when searching for “random walks”, entering just that one keyword. I invite you to compare it with OpenAI, Bing, Google, Bard, and the Wolfram search box itself. For professionals like me, this is what I want. For the layman, the other tools are better. In short, evaluation metrics depend on the type of user: there is no one-size-fits-all.
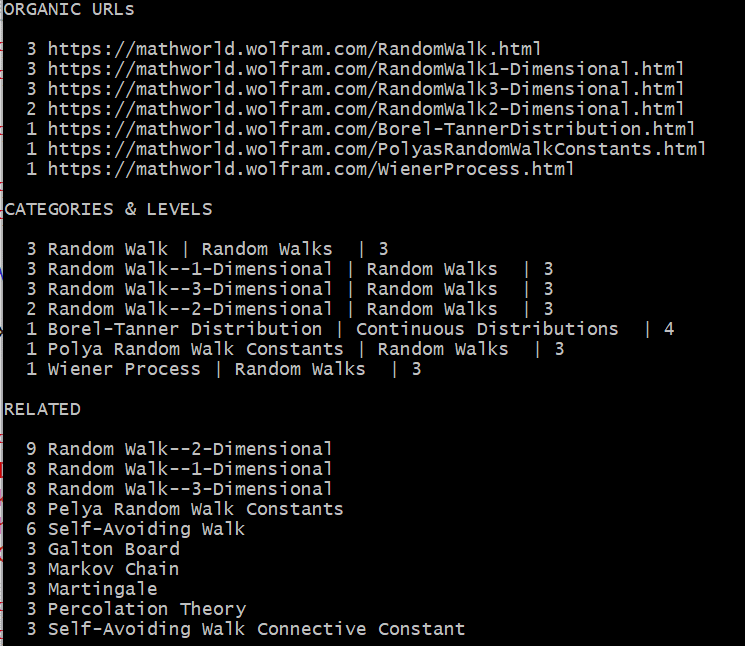
Note that I did not include all the sections from the search results in the above picture. In particular, I excluded the embeddings section. Also, I limited the number of entries to 10 per section. Each integer number provides additional information: category level, weight, or in the case of embeddings, the strength of the association between two keywords. From there, you can continue to search with more specialized keywords, such as “martingale” or “Wiener process”. Also, you can save the results as a report, on your laptop: this file can be quite large when selecting all dictionary sub n-grams: for instance, “random” and “walk” in addition to “random walk”.
In the near future, I will blend with results from Wikipedia, my own books, or other sources. In the case of my books, I could add a section entitled “Sponsored Links”, as these books are not free. Indeed, I can accept advertiser keywords. Another way to monetize it is to have a paid version. It would provide access to live, bigger tables (thus more comprehensive results), fewer limitations and parameter tuning, compared to the free version.
As of now, only one top category is included, and based just on Wolfram crawl. The Python code and tables are on GitHub, here. I am currently writing the documentation (available soon). Also, I plan to offer it as a Web API on GenAItechLab.com. To not miss these future updates, you can subscribe to my newsletter, here. I will also post important developments on Data Science Central.
In the end, the goal of this article is to show you how relatively easy it is to build such a customized app (for a developer), and the benefits of having full control over all the components.
Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET.
Vincent is also a former post-doc at Cambridge University, and the National Institute of Statistical Sciences (NISS). He published in Journal of Number Theory, Journal of the Royal Statistical Society (Series B), and IEEE Transactions on Pattern Analysis and Machine Intelligence. He is the author of multiple books, including “Synthetic Data and Generative AI” (Elsevier, 2024). Vincent lives in Washington state, and enjoys doing research on stochastic processes, dynamical systems, experimental math and probabilistic number theory. He recently launched a GenAI certification program, offering state-of-the-art, enterprise grade projects to participants.
{kind=link}