
Open software provides a multiarchitecture, multivendor solution that addresses the complexities of accelerated HPC and AI computing
The advent of heterogenous computing with accelerators like GPUs has transformed the fields of AI and HPC in commercial and scientific computing environments. Early vendor-specific GPU programming models such as CUDA worked well in jumpstarting GPU computing and in adapting to the rapidly evolving GPU architectures controlled by a single hardware vendor.
Success has bred competition. The availability of GPU accelerators from multiple vendors including Intel (with the Intel® Data Center GPU Max Series), AMD, and NVIDIA has created a combinatorial support problem for software developers. The race to high performance has spurred a rapid evolution in hardware and software architectures as vendors compete to run various workloads more efficiently. Machine learning and AI in particular have driven workload-specific optimizations that can increase performance and efficiency.
The combinatorial explosion issue occurs when a number of possible combinations are created by increasing the number of entities (Source). In support terms, an increasing number of device types in the datacenter can quickly exceed the ability of a programmer to explicitly support all the device combinations encountered by their user base.
CPUs are now entering the AI accelerated fray. New manufacturing technologies give hardware designers the ability to exploit new modular in-package silicon design and manufacturing capabilities. CPUs now incorporate AI-oriented capabilities through in-package accelerators like the Intel® Advanced Matrix Extensions (Intel® AMX) and the Intel® Data Streaming Accelerator (Intel® DSA). [1] These accelerated CPUs can deliver performance competitive with GPUs on some AI workloads. The inclusion of high bandwidth memory (HBM) such as in the Intel(R) Xeon(R) CPU Max Series is also helping to close the CPU vs GPU performance gap for many HPC and AI workloads.[2] [3]
While competition and the many advances in hardware and machine architectures are highly beneficial, from a software perspective these advances resulted in an exponential growth in the number of hardware combinations possible in today’s datacenters. This support problem is only going to get worse as non-Von Neumann hardware devices like FPGAs become more prevalent in the datacenter.
Programmers can no longer rely on the traditional method of targeting specific hardware accelerators with conditional pragmas (e.g., #ifdef) to match the software to the hardware at a particular datacenter or customer site. Humans writing machine-specific code cannot address the exponential increase in possible hardware combinations in the modern multivendor, multiarchitecture computing environment.
Open, heterogeneous software provides support and sustainability path
Based on decades of observation, Joe Curley (vice president and general manager – Intel Software Products and Ecosystem) summarized why vendor-agnostic software is now a necessity, “Intel is fortunate to have great relationships where we supply from core technology to the largest enterprises, cloud vendors, high performance computing centers, and embedded device manufacturers around the world. Our customers bring us issues. We then find ways to aggregate all the issues and solve them.”
He continued, “We found that we need an open, multiarchitecture programming model [e.g., the oneAPI software ecosystem] that sits between diverse hardware and the productive software that lives above it. The programmer wants to write the program in abstraction and benefit from the accelerator beneath it. The developer doesn’t start programming wondering what Intel or any other vendor has to offer. What they really want is to use an FPGA, or a GPU, or a CPU, or perhaps some combination to solve their problem productively.”
To address the need for vendor-agnostic heterogeneity, the open software community devised a twofold solution utilizing a governance model (e.g., for SYCL) and a community model for API and runtime development. This same twofold solution solves the combinatorial problem in supporting applications running in a vendor-agnostic multiarchitecture environment:
- Compilers can transparently target specific hardware devices and capabilities through general-purpose language standards specified by an industry representative governing body. Complementary, domain-specific efforts such as JAX, Triton, Mojo, and others can also enable productivity and accelerator access for target workloads such as AI. These just-in-time and ahead-of-time workload optimizations[4] can benefit compilers and general-purpose language standards.
- Standardized tools can be developed in accord with a community model that supports all the mainstream hardware vendors. Well-designed library interfaces and runtimes conforming to a separation of concerns give programmers the standardized capabilities they need to express their computations with sufficient generality to run efficiently on many different hardware platforms, while simultaneously giving the library and runtime authors sufficient flexibility to target specific hardware and accelerator capabilities.
In both cases, an open, community-based development model gives all interested parties a voice and lets vendors compete by optimizing those software components that are important to their customers for their particular platforms.
The challenge in developing a multiarchitecture software ecosystem, even one with extensive community support, is that application software development teams cannot be forced to start over. Instead, tools must be provided to help programmers migrate existing single-vendor codebases to the open ecosystem while also enabling multiarchitecture support. One example is discussed in the article, “Heterogeneous Code Performance and Portability Using CUDA to SYCL Migration Tools.”
General-purpose standards and libraries and pathways to transition existing apps
From a compatibility perspective, the transition to heterogenous accelerated computing has wide-ranging implications.
Intel’s x86 architecture CPUs, for example, have maintained a large share of the datacenter market for many years.[5] During the planning phase to introduce in-package CPU accelerators and two GPU product families, Intel proactively addressed this combinatorial software challenge to preserve legacy compatibility while enabling heterogenous runtimes in a supportable fashion. The result was the adoption and active participation by Intel and other industry leaders in the oneAPI community software ecosystem. The oneAPI multiarchitecture, open accelerated ecosystem can support x86, ARM and RISC-V CPUs; multivendor GPUs; in-package accelerators; and non-Von Neumann hardware such as FPGAs (Figure 1).
Avoiding cendor lock-in: From AI workloads to HPC
Application-level heterogeneity is not enough. For many data scientists, TensorFlow and PyTorch provide an all-encompassing worldview of the datacenter, on-premises computing resources and cloud computing. This works nicely for the computationally intensive training of artificial neural networks (ANNs), but the money-maker in AI lies in using the trained ANNs to service customer needs. There is a catch though: vendor optimized libraries can cause vendor lock-in if they are utilized during training. From a business perspective these optimized, vendor-specific libraries become a money maker for the hardware vendor, but they are anathema to portability.
AI benefits HPC
AI and machine learning now play a significant role in HPC, which means AI-accelerated hardware benefits the HPC community as well as the AI community. See the first article in this series, for more information about what experts now describe as the 5th epoch of distributed computing.[6]
For example, ANNs can deliver orders-of-magnitude faster and better models for physics-based simulations. CERN provided a ground-breaking example of AI in high-energy physics (HEP) simulations by training an ANN to replace a computationally expensive Monte Carlo simulation. Not only did the ANNs achieve orders-of-magnitude faster performance, they also created simulated samples that were both realistic (indistinguishable from real data) and robust against missing data. More recently, scientists are now using AI to find an ANN that predicts intrinsic charm in the proton better than any previous model. These are just two examples of scientists incorporating AI in their research. Look to the Argonne Leadership Computing Facility (ALCF) Early Science program for the Aurora exascale supercomputer for additional examples.
Proof that the community model can support vendor-agnostic heterogeneity
The US Department of Energy (DOE) effort was tasked with addressing the combinatorics of supporting leadership supercomputers containing Intel, AMD, and NVIDIA accelerators for production AI and HPC workloads. Performance is mandatory given the number of projects of national and societal importance that are vying for time on systems.
In doing so, the US DOE Exascale Computing Project (ECP) demonstrated the efficacy of the community software development model, which is a cornerstone in creating the library APIs [7] and maturing the compiler technology to support a vendor-agnostic multiarchitecture computing paradigm. Validating the oneAPI programming approach is part of this process.
Curley summarized the value of the community model, “When you’re working in the open, the community starts doing work with you. This openness allows the community to be able to lift problems together rather than counting on Intel or counting on customer company A,B, or C.”
When you’re working in the open, the community starts doing work with you. This openness allows the community to be able to lift problems together rather than counting on Intel or counting on customer company A,B, or C. — Joe Curley
Tying it all together
These important workloads (AI and HPC) make accelerators a natural next step as Joe Curley noted, “When a problem gets big enough or pervasive enough, then accelerate it. With acceleration we can get answers with less power, which requires an appropriate software ecosystem.”
When a problem gets big enough or pervasive enough, then accelerate it. With acceleration we can get answers with less power, which requires an appropriate software ecosystem. – Joe Curley
A language standard for accelerators and heterogenous computing
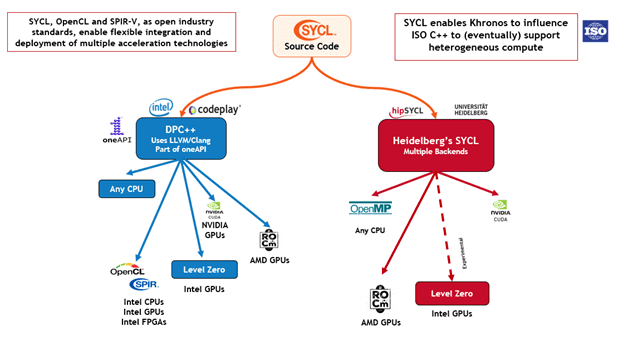
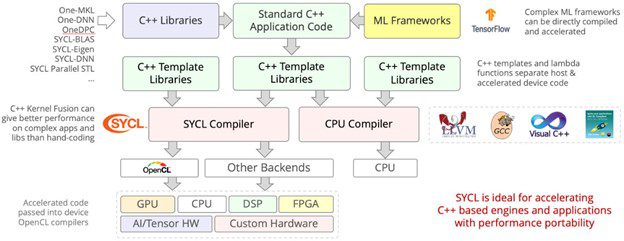
The oneAPI ecosystem is based on SYCL, which is the language component that gives programmers the ability to express the parallelism in their program in a manner that can be mapped to many different types of hardware and accelerators by the compiler developers (Figure 2). The language standard is governed by the Khronos Group standards committee and enjoys wide industry support.[8] A major goal of SYCL is to enable different heterogeneous devices to be used in a single application — for example simultaneous use of CPUs, GPUs, and FPGAs. Curley pointed to the University of Tsukuba paper, “Multi-hetero Acceleration by GPU and FPGA for Astrophysics Simulation on oneAPI Environment” as a working example in the literature.
Languages
SYCL is C++ based. Source-to-source translation from popular GPU languages such as CUDA are possible with the SYCLomatic tool as discussed in “Heterogeneous Code Performance and Portability Using CUDA to SYCL Migration Tools”. SYCLomatic is typically able to migrate about 90%-95% of CUDA source code automatically to SYCL source code, leaving very little for programmers to manually tune.[9]
For legacy HPC applications, Fortran programmers can use one of the two Fortran compilers provided in the latest Intel oneAPI tools release: Ifort which provides full Fortran 2018 support and the Intel Fortran compiler (ifx) which adds OpenMP directive and offload capabilities for Intel GPUs.
Libraries
Intel software teams and the community are working to create compatible library APIs for programmers to use and for source-to-source translation via SYCLomatic. A large number of APIs are already addressed including a number of runtime, math, and neural network libraries.[10] The CUDA API Migration support status can be viewed here.
The ECP project has also been busily porting and validating a number of critical HPC math libraries including PETSc, Hypre, SUNDIALS, and more. These numerical libraries are based on the community development model. [11]
Analysis and debugging
The oneAPI community provides a number of tools to help programmers analyze and debug their oneAPI codes. The ECP, for example, provides TAU, a CPU, GPU, and MPI profiler for all the DOE exascale machines. This includes support for the Intel-based Aurora supercomputer at Argonne National Lab. Intel also provides Intel® VTune™ Profiler and the Intel® Distribution for GDB for analyzing oneAPI codes.
Summary
Transitioning to a multiarchitecture, vendor-agnostic, heterogeneous runtime environment is now a requirement for sustainable, performance portable software. Vigorous competition among hardware vendors benefits users by providing more performant and power-efficient hardware. Only by addressing the combinatorial support problem can users realize the full benefits of these hardware capabilities.
The oneAPI ecosystem focusing on vendor-agnostic heterogeneous programming demonstrates that it is possible to address the exponential combinatorial multiarchitecture support problem via the community model; standards-based compilers, libraries, and runtimes, and compatibility tools. The breadth of these communities also mandates the use of an open community-based development model to create common software components that can deliver performance and portability across multiple types of architectures. Competition, ubiquity, and growth of the global HPC and AI communities demonstrate that a single-vendor software ecosystem is now beyond the reach of any single company.
Rob Farber is a global technology consultant and author with an extensive background in HPC and machine learning technology.
[1] https://www.intel.com/content/www/us/en/developer/articles/technical/ai-inference-acceleration-on-intel-cpus.html
[2] https://www.datasciencecentral.com/internal-cpu-accelerators-and-hbm-enable-faster-and-smarter-hpc-and-ai-applications/
[3] https://medium.com/@rmfarber/balancing-high-bandwidth-memory-and-faster-time-to-solution-for-manufacturing-bd2b4ff7f74e
[4] https://jax.readthedocs.io/en/latest/aot.html
[5] https://www.statista.com/statistics/735904/worldwide-x86-intel-amd-market-share/
[6] See the video the “Coming of Age in the Fifth Epoch of Distributed Computing”. Tim Mattson, senior principal engineer at Intel believes the sixth generation will happen quickly, and start around 2025 with software defined ‘everything’ that be limited by the speed of light: https://www.youtube.com/watch?v=SdJ-d7m0z1I.
[7] https://arxiv.org/abs/2201.00967
[8] https://www.khronos.org/sycl/
[9] Intel estimates as of March 2023. Based on measurements on a set of 85 HPC benchmarks and samples, with examples like Rodinia, SHOC, PENNANT. Results may vary.
[10] https://medium.com/@rmfarber/heterogeneous-code-performance-and-portability-using-cuda-to-sycl-migration-tools-6371be894aa
[11] https://arxiv.org/abs/2201.00967
This article was produced as part of Intel’s editorial program, with the goal of highlighting cutting-edge science, research and innovation driven by the HPC and AI communities through advanced technology. The publisher of the content has final editing rights and determines what articles are published.
{kind=link}