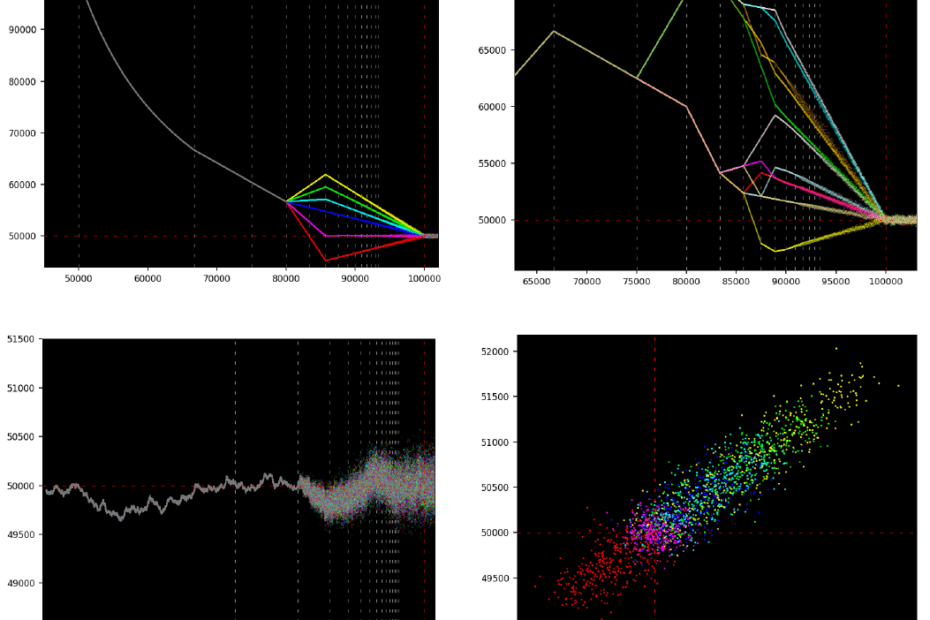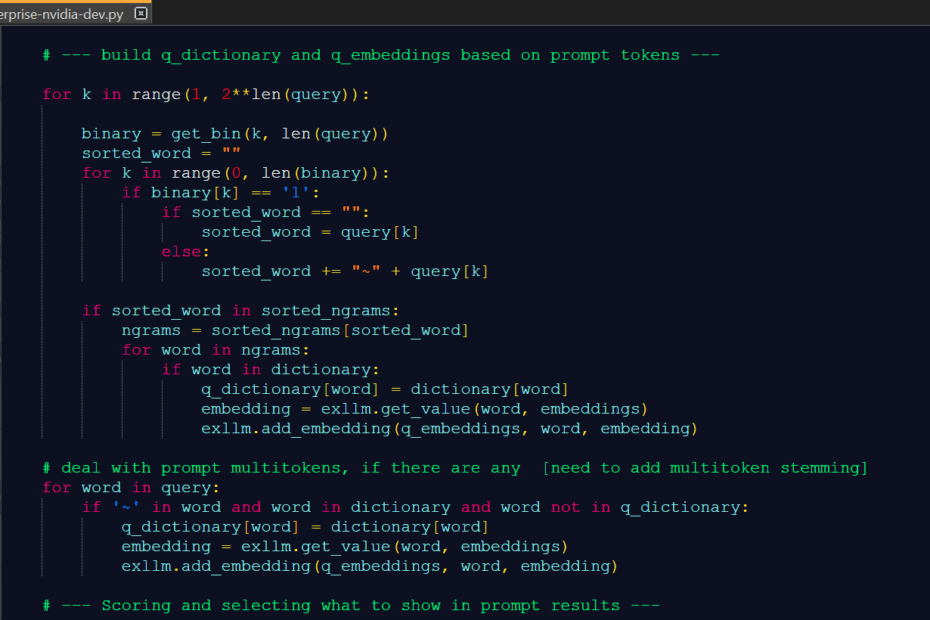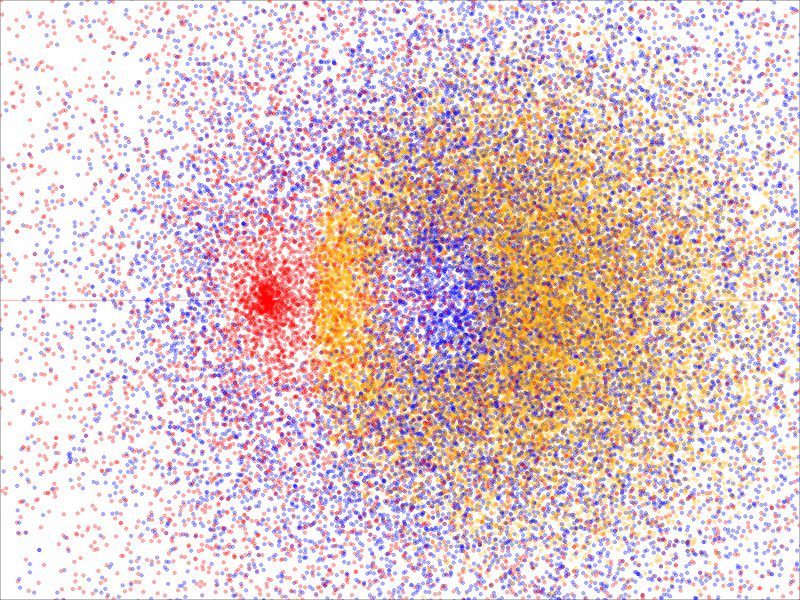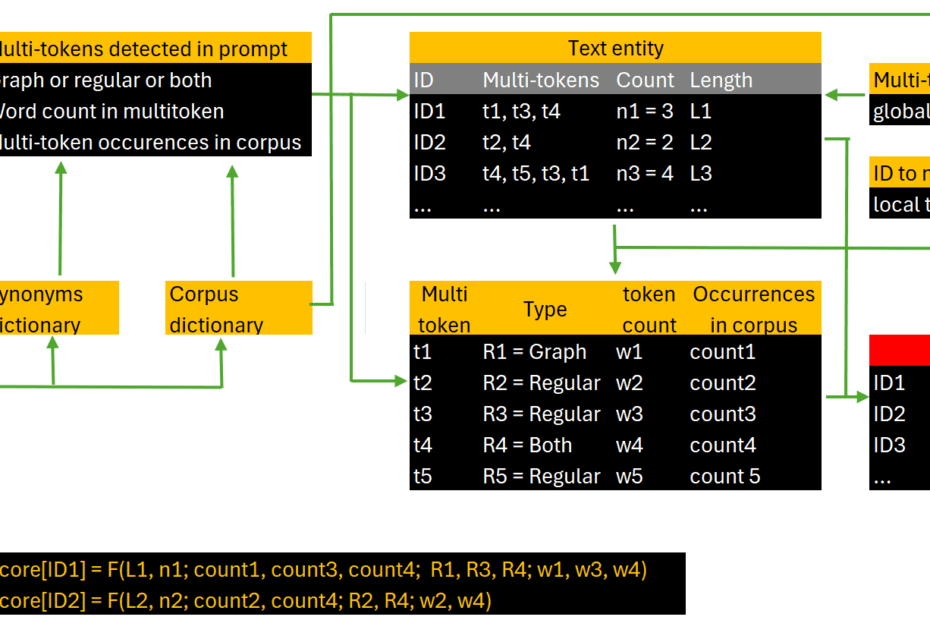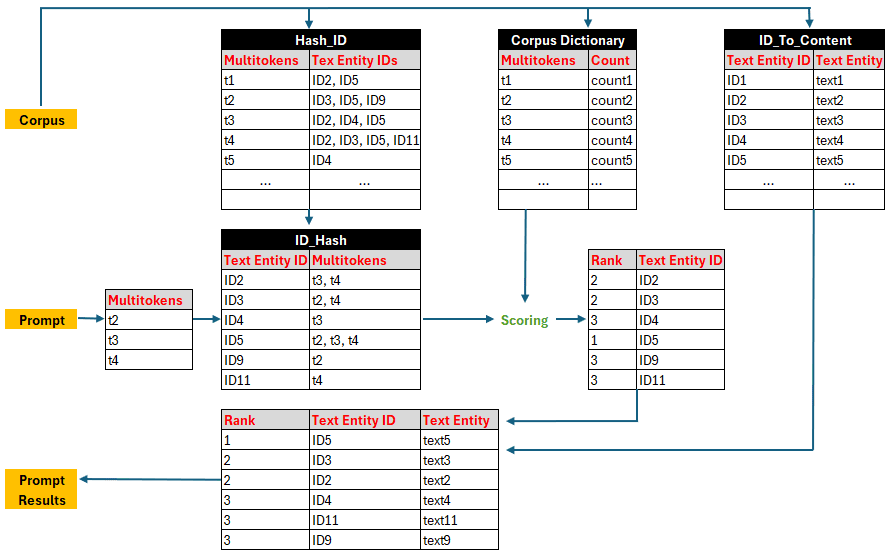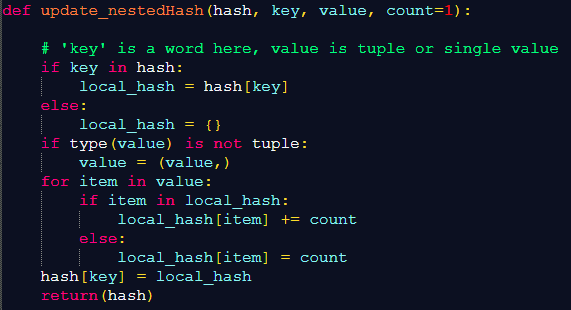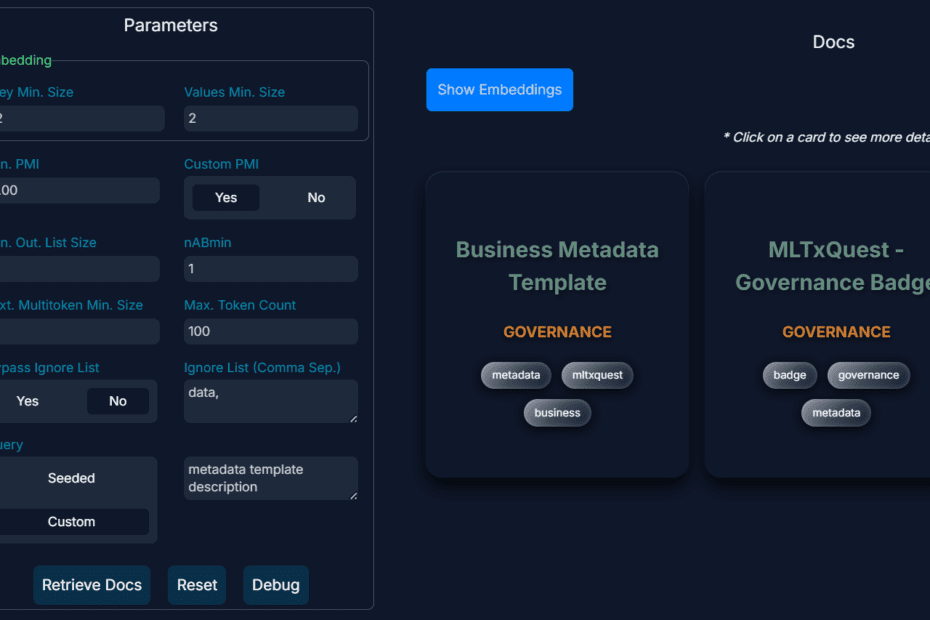
How to Build and Optimize High-Performance Deep Neural Networks from Scratch

With explainable AI, intuitive parameters easy to fine-tune, versatile, robust, fast to train, without any library other than Numpy. In short, you have full control… Read More »How to Build and Optimize High-Performance Deep Neural Networks from Scratch