
What I mean here is that traditional LLMs are trained on tasks irrelevant to what they will do for the user. It’s like training a plane to efficiently operate on the runway, but not to fly. In short, it is almost impossible to train an LLM, and evaluating is just as challenging. Then, training is not even necessary. In this article, I dive on all these topics.
Training LLMs for the wrong tasks
Since the beginnings with Bert, training an LLM typically consists of predicting the next tokens in a sentence, or removing some tokens and then have your algorithm fill the blanks. You optimize the underlying deep neural networks to perform these supervised learning tasks as well as possible. Typically, it involves growing the list of tokens in the training set to billions or trillions, increasing the cost and time to train. However, recently, there is a tendency to work with smaller datasets, by distilling the input sources and token lists. After all, out of one trillion tokens, 99% are noise and do not contribute to improving the results for the end-user; they may even contribute to hallucinations. Keep in mind that human beings have a vocabulary of about 30,000 keywords, and that the number of potential standardized prompts on a specialized corpus (and thus the number of potential answers) is less than a million.
More problems linked to training
In addition, training relies on minimizing a loss function that is just a proxy to the model evaluation function. So, you don’t even truly optimize next token prediction, itself a task unrelated to what LLMs must perform for the user. To directly optimize the evaluation metric, see my approach in this article. And while I don’t design LLMs for next token prediction, see one exception here, to synthesize DNA sequences.
The fact is that LLM optimization is an unsupervised machine learning problem, thus not really amenable to training. I compare it to clustering, as opposed to supervised classification. There is no perfect answer except for trivial situations. In the context of LLMs, laymen may like OpenAI better than my own technology, while the converse is true for busy business professionals and advanced users. Also, new keywords keep coming regularly. Acronyms and synonyms that map to keywords in the training set yet absent in the corpus, are usually ignored. All this further complicates training.
Analogy to clustering algorithms
As an example, this time in the context of clustering, see Figure 1. It features a dataset with three clusters. How many do you see, if all the dots had the same color? Ask someone else, and you may get a different answer. What characterizes each of these clusters? You cannot train an algorithm to correctly identify all cluster structures, though you could for very specific cases like this one. The same is true for LLMs. Interestingly, some vendors claim that their LLM can solve clustering problems. I would be happy to see what they say about the dataset in Figure 1.
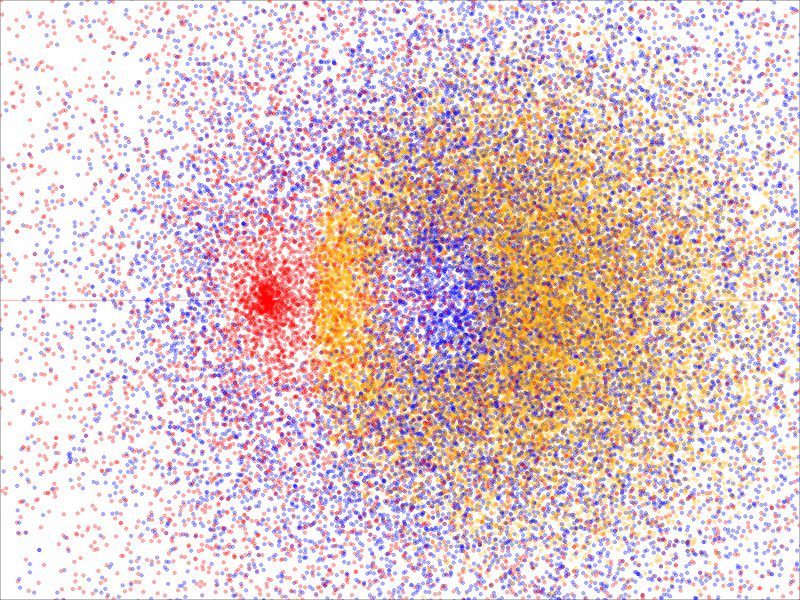
For those interested, the dots in Figure 1 represent points on three different orbits of the Riemann zeta function. The blue and red ones are related to the critical band. The red dots correspond to the critical line with infinitely many roots. It has no hole. The yellow dots are on an orbit outside the critical band; the orbit in question is bounded (unlike the other ones) and has a hole in the middle of the picture. The blue orbit also appears to not cover the origin where red dots are concentrated; its hole center — the “eye” as in the eye of a hurricane — is on the left side, to the right of the dense red cluster but left to the center of the hole in the yellow cloud. Proving that its hole encompasses the origin, amounts to proving the Rieman Hypothesis. The blue and red orbits are unbounded.
Can LLMs figure this out? Can you train them to answer such questions? The answer is no. They could succeed if appropriately trained on this very type of example but fail on a dataset with a different structure (the equivalent of a different kind of prompt). One reason why it makes sense to build specialized LLMs rather than generic ones.
Evaluating LLMs
There are numerous evaluation metrics to assess the quality of an LLM, each measuring a specific type of performance. It is reminiscent of test batteries for random number generators (PRNGs) to assess how random the generated numbers are. But there is a major difference. In the case of PRNGs, the target output has a known, prespecified uniform distribution. The reason to use so many tests is because no one has yet implemented a universal test, based for instance on the full multivariate Kolmogorov-Smirnov distance. Actually, I did recently and will publish an article about it. It even has its Python library, here.
For LLMs that answer arbitrary prompts and output English sentences, there is no possible universal test. Even though LLMs are trained to correctly replicate the full multivariate token distribution — a problem similar to PRNGs thus with a universal evaluation metric — the goal is not token prediction, and thus evaluation criteria must be different. There will never be a universal evaluation metric except for very peculiar cases, such as LLMs for predictive analytics. Below is a list of important features lacking in current evaluation and benchmarking metrics.
Overlooked criteria, hard to measure
- Exhaustivity: Ability to retrieve absolutely every relevant item, given the limited input corpus. Full exhaustivity is the ability to retrieve everything on a specific topic, like chemistry, even if not in the corpus. This may involve crawling in real-time to answer the prompt.
- Inference: Ability to invent correct answers for problems with no known solution, for instance proving or creating a theorem. I asked GPT if the sequence (an) is equidistributed modulo 1 if a = 3/2. Instead of providing references as I had hoped — it usually does not — GPT created a short proof on the fly, and not just for a = 3/2; Perplexity failed at that. The use of synonyms and links between knowledge elements can help achieve this goal.
- Depth, conciseness and disambiguation are not easy to measure. Some users see long English sentences superior to concise bullet lists grouped into sections in the prompt results. For others, the opposite is true. Experts prefer depth, but it can be overwhelming to the layman. Disambiguation can be achieved by asking the user to choose between different contexts; this option is not available in most LLMs. As a result, these qualities are rarely tested. The best LLMs, in my opinion, combine depth and conciseness, providing in much less text far more information than their competitors. Metrics based on entropy could help in this context.
- Ease of use is rarely tested, as all UIs consist of a simple search box. However, xLLM is different, allowing the user to select agents, negative keywords, and sub-LLMs (subcategories). It also allows you to fine-tune or debug in real-time thanks to intuitive parameters. In short, it is more user-friendly. For details, see here.
- Security is also difficult to measure. But LLMs with local implementation, not relying on external APIs and libraries, are typically more secure. Finally, a good evaluation metric should take into account the relevancy scores displayed in the results. As of now, only xLLM displays such scores, telling the user how confident it is in its answer.
Benefits of untrained LLMs
In view of the preceding arguments, one might wonder if training is necessary, especially since training is not done to provide better answers, but to better predict the next tokens. Without training, its heavy computations and black-box deep neural networks machinery, LLMs can be far more efficient yet even more accurate. To generate answers in English prose based on the retrieved material, one may use template, pre-made answers where keywords can be plugged in. This can turn specialized sub-LLMs into giant Q&A’s with a million questions and answers covering all potential inquiries. And deliver real ROI to the client by not requiring GPU and expensive training.
This is why I created xLLM, and the reason why I call it LLM 2.0, with its radically different architecture and next-gen features including the unique UI. I describe it in detail in my recent book “Building Disruptive AI & LLM Technology from Scratch”, available here. Additional research papers are available here.
That said, xLLM still requires fine-tuning, for back-end and front-end parameters. It also allows the user to test and select his favorite parameters. Then, it blends the most popular ones to automatically create default parameter sets. I call it self-tuning. It is possibly the simplest reinforcement learning strategy.
About the Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author (Elsevier) and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent on LinkedIn.
{kind=link}
Dear Vincent,
Thank you for your thought-provoking article. It raises insightful questions about the efficiency and purpose of LLM training paradigms and offers intriguing perspectives, particularly with your xLLM framework. While I appreciate the critical lens you apply to current LLM architectures, I would like to bring your attention to a different perspective on the role of token prediction and its relevance to higher-order reasoning in LLMs.
You argue that training LLMs on token prediction is akin to “training a plane to efficiently operate on the runway, but not to fly.” While this analogy is compelling, one might argue that it oversimplifies the role token prediction plays in enabling the emergent capabilities of LLMs. What may appear to be a trivial process—predicting the next token—could, in fact, be viewed as the foundational building block for the complex reasoning and abstraction abilities exhibited by these models.
The Power of Token Prediction: A Foundational Process
Allow me to propose an alternative analogy: token prediction in LLMs is akin to the firing of neurons in the human brain. At first glance, individual neurons transmitting electrical impulses may seem like a low-level, trivial process. However, as these impulses propagate through intricate neural networks, they eventually give rise to higher-order cognitive functions such as reasoning, planning, and even metacognition. Similarly, token prediction can be seen as a low-level process for LLMs. By optimizing for this seemingly simple task, the model learns patterns, structures, and relationships that scale into capabilities far beyond the task itself.
Here are some reasons why this comparison may hold merit:
1. Sequential Processing as a Basis for Reasoning
Token prediction is not merely about predicting the next word in isolation; it involves understanding statistical relationships between words, grammar, syntax, and semantics over long contexts. This sequential processing could be compared to how the brain interprets sensory input over time to construct coherent thoughts. The model’s ability to predict tokens is what allows it to process and construct meaning, maintain context, and produce coherent outputs.
2. Emergent Behavior from Simple Rules
Just as neural activity in the brain gives rise to emergent phenomena like emotion or reasoning, token prediction enables emergent behaviors in LLMs. Through this task, the model can:
– Generalize across unseen prompts.
– Infer relationships between concepts.
– Perform tasks ranging from summarization to logical reasoning, even though these were not explicitly programmed into the model.
3. Statistical Generalization
Token prediction allows LLMs to learn statistical patterns in language, enabling them to generalize beyond their training data. For example, a model trained on next-token prediction can generate coherent paragraphs, answer complex questions, and even solve logical problems. This generalization mirrors how the brain uses repeated stimuli to form abstract concepts and apply them in novel situations.
4. Contextual Awareness Through Attention Mechanisms
Modern LLMs, particularly those based on Transformer architectures, use attention mechanisms to weigh the importance of preceding tokens, much like the brain prioritizes relevant stimuli. This allows LLMs to maintain coherence, resolve ambiguities, and even disambiguate multiple contexts—all of which are critical for higher-order reasoning.
On the “Triviality” of Token Prediction
You mention that token prediction is “a task unrelated to what LLMs must perform for the user.” While it is true that users may not directly care about token prediction, this process could be seen as the means to the desired end—much like neurons firing in the brain are not the end goal of cognition but an essential mechanism to achieve it.
In fact, the emergent properties of LLMs—their ability to generate creative solutions, answer abstract questions, and adapt to a wide variety of tasks—may rely entirely on the foundational learning achieved through token prediction. Without this process, the model might struggle to generalize across diverse prompts or respond to novel situations, both of which are essential for practical applications.
Token Prediction vs. Specialized Architectures
Your advocacy for specialized LLMs (like xLLM) over generic ones is a valuable point, and domain-specific optimization often yields better results for niche tasks. However, one could argue that the token-prediction paradigm is not inherently at odds with specialization. In fact, the same fundamental training process can be adapted for specialized purposes through fine-tuning and reinforcement learning from human feedback (RLHF), as demonstrated by many existing models.
While you propose moving away from token prediction in favor of pre-made templates or plug-in keywords, this approach might sacrifice the flexibility and adaptability that make LLMs so powerful. The value of current LLMs lies in their ability to handle unstructured, open-ended prompts—a capability that stems directly from their token-prediction training.
Areas of Agreement
That said, your critique of training inefficiencies and evaluation metrics highlights important challenges in the field:
1. Dataset Noise
You point out that much of the training data in LLMs is noisy or irrelevant to end-user needs. This is indeed a challenge, and recent research has explored methods like data distillation and curated pretraining datasets to address this issue.
2. Evaluation Metrics
Your observation that current evaluation metrics fail to fully capture the quality of LLM outputs is also well-founded. Metrics like BLEU or perplexity often do not reflect real-world utility, and there is a growing need for metrics that measure exhaustivity, inference, and user-specific preferences. Your proposed focus on overlooked criteria like depth, conciseness, and disambiguation represents a valuable contribution to these discussions.
A Path Forward: Bridging Perspectives
Your work on xLLM raises important questions about the future of LLM architectures. While one may not fully agree with the assertion that “training is not even necessary,” your focus on practical efficiency and user-centric design is commendable. Perhaps the path forward lies in bridging the two approaches: leveraging the power of token-prediction-based generalization while incorporating modular, user-friendly interfaces like those you propose.
Token prediction may not be a perfect paradigm, but it has proven to be a robust foundation for building systems capable of remarkable reasoning and abstraction. By combining these strengths with innovations like modular sub-LLMs and more intuitive tuning mechanisms, we may arrive at solutions that are both powerful and efficient.
Final Thoughts
Thank you for sharing your insights and for encouraging a deeper exploration of this exciting field. I look forward to learning more about your xLLM framework and engaging in further discussions about how we can address the limitations of current systems while building on their strengths. There is much to gain from combining diverse perspectives, and I hope this response contributes constructively to the broader conversation.
Warm regards,
ALI
I can’t see where anything constrains even the best predictor of next tokens to that which is true or even that which is useful. That cannot “emerge” from lower-level token prediction without feedback from some source of truth or scoring standard. Since educated, thinking humans can debate for a lifetime about whether or not something is true, good, wise, or useful without arriving at a consensus, I have little faith that a machine process would arrive at a solution for these which would satisfy most users.
“The Decision Problem”
Verry Informative post.