
In this article, I describe some of the most common types of databases that apps such as RAG or LLM rely upon. I also provide tips and techniques on how to optimize these databases. Performance improvement methods deal with speed, bandwidth or size, and real-time processing.
Some common types of databases
Vector and graph databases are among the most popular these days, especially for GenAI and LLM apps. Most can also handle tasks performed by traditional databases and understand SQL and other languages (NoSQL, NewSQL). Some optimize for fast search and real time.
- In vector databases, features (the columns in a tabular dataset) are processed jointly with encoding, rather than column by column. The encoding uses quantization such as truncating 64-bit real numbers to 4-bit. The large gain in speed outweighs the small loss in accuracy. Typically, in LLMs, you use these DBs to store embeddings.
- Graph databases store information as nodes and node connections with weights between nodes. For instance, knowledge graphs and taxonomies with categories and sub-categories. In some cases, a category can have multiple parent categories, and multiple subcategories, making tree structures not suitable. Keyword associations are a good fit for graph databases.
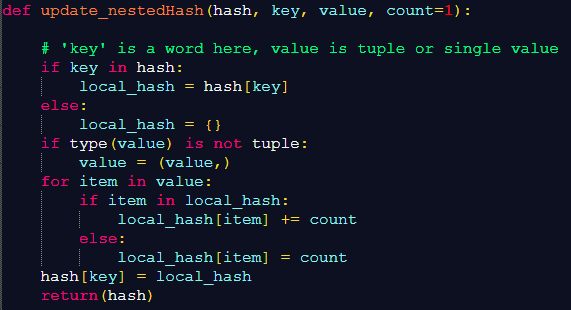
- JSON and bubble databases deal with data lacking structure, such as text and web content. In my case, I use in-memory key-value tables. That is, hash tables or dictionaries in Python, see Figure 1. The values are key-value tables themselves, resulting in nested hashes (see here). The benefit: in RAG/LLMs, this structure is very similar to the organization of JSON text entities from the input corpus.
- Some databases focus on columns rather than rows. We call them column databases. Some fit in memory: we call them in-memory databases. The latter offer faster execution. Another way to increase performance is via a parallel implementation, for instance similar to Hadoop.
- In object-oriented databases, you store the data as objects, similar to object-oriented programming languages. Database records consist of objects. It facilitates direct mapping of objects in your code, to objects in the database.
- Hierarchical databases are good at representing tree structures, a special kind of graph. Network databases go one step further, allowing more complex relationships than hierarchical databases, in particular multiple parent-child relationships.
- For special needs, consider time series, geospatial and multimodel databases (not the same meaning as multimodal). Multimodel databases support multiple data models (document, graph, key-value) within a single engine. You can also organize Image and soundtrack repositories as databases. In general, file repositories are de facto databases.
Quick tips to increase performance
Here are 8 strategies to achieve this goal.
- Switch to different architecture with better query engine, for instance from JSON or SQL to vector database. The new engine may automatically optimize configuration parameters. The latter are important to fine-tune database performance.
- Efficiently encode your fields, with minimum or no loss, especially for long text elements. This is done automatically when switching to a high-performance database. Also, instead of fixed-length embeddings (with a fixed number of tokens per embedding), use variable length and nested hashes rather than vectors.
- Eliminate features or rows that are rarely used or redundant. Work with smaller vectors. Do you need 1 trillion parameters, tokens, or weights? Much of it is noise. They keyword for this type of cleaning is “data distillation”. In one case, randomly eliminating 50% of the data resulted in better, more robust predictions.
- With sparse data such as keyword association tables, use hash structures. If you have 10 million keywords, no need to use a 10 million x 10 million association table if 99.5% of keyword associations have 0 weight or cosine distance.
- Leverage the cloud, distributed architecture, and GPU. Optimize queries to avoid expensive operations. This can be done automatically with AI, transparently to the user. Use cache for common queries or rows/columns most frequently accessed. Use summary instead of raw tables. Archive raw data on a regular basis.
- Load parts of the database in memory and perform in-memory queries. That’s how I get queries running at least 100 times faster in my LLM app, in contrast to vendors. The choice and type of index also matters. In my case, I use multi-indexes spanning across multiple columns, rather than separate indexes. I call the technique “smart encoding”, see illustration here.
- Use techniques such as approximate nearest neighbor search for faster retrieval, especially in RAG/LLMs apps. For instance, in LLMs, you want to match an embedding coming from a prompt, with your backend embeddings coming from the input corpus. In practice, many times, there is no exact match, thus the need for fuzzy match. See example here.
About the Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author (Elsevier) and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent on LinkedIn.
{kind=link}
Great summary – especially the focus on vector and graph databases feels very timely!
Interesting take.
So you’re going to transform relational data into either a hierarchical model.
I wonder what happens when your key/value store exceeds available memory and if you’re looking to spill to disk.