

Deep learning guru, NYU professor, and chief AI scientist at Meta Yann LeCun has been bullish about neural nets for years now. But in March 2023, his position became more nuanced. Here’s a slide he shared from a talk via Twitter:

An auto-regressive large language model, I understand from LeCun’s March talk at the Philosophy of Deep Learning conference, is one with millions or billions of parameters, and one that continually predicts the next tokenized word or subword in a string of such words. Referring to AR-LLMs, he said, “Those things also suck. They’re amazing in many ways, but they’re nowhere near what’s required for human-level intelligence.”
It’s a relief to hear that folks like LeCun are also dissatisfied with the current state of these models. And it’s wearisome to hear enthusiasts who may know very little about large language models (LLMs) heap praise on GPTx like it’s the AI answer to all our prayers. My Twitter and LinkedIn feeds have been full of this talk for months.
Bizarrely, Geoff Hinton of the University of Toronto and a deep learning luminary himself with many decades of experience, went on the PBS News Hour in May 2023 to claim that GPT4 and other giant statistical language models like it have “understanding” and “intuition.”
Granted, LLMs can be useful tools, and the prompt + machine-assisted coding help they offer for developers is one of the most useful things about them. But when it comes to mainstream use, are they creating more problems than they’re solving right now?
The stochastic parrot and documentation debt
The more I read about LLMs, the more I find out about their long-term, detrimental effects.
For example, Emily Bender of the University of Washington and team have been critical of the LLM approach and particularly the size of and the less-than-painstaking approach to the datasets used to train the models.
Their most telling criticism is what they call “documentation debt”: “When we rely on ever larger datasets we risk incurring documentation debt,” they say, “i.e., putting ourselves in the situation where the datasets are both undocumented and too large to document post hoc…. The solution, we propose, is to budget for documentation as part of the planned costs of dataset creation, and only collect as much data as can be thoroughly documented within that budget.”
“Stochastic parrot” is a term Bender, et al., came up with to describe the fact that LLMs are just parroting what they’re being trained on. Here’s their definition:
“A Language Model is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot.” –Emily Bender, et al.,
“On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?,” ACM paper presented at FAccT ’21, March 3–10, 2021, virtual event, Canada
In that context, stochastic parrot worshippers IMHO are those who mindlessly praise LLMs without realizing they’ve mistaken the parrot part—probabilistic language methods alone–for the whole. These worshippers seem to assume those methods alone will deliver artificial general intelligence.
As Bender and team have pointed out, LLM question answering does not evidence natural language understanding (NLU). NLU requires the involvement of other disciplines–experts besides the existing cadre of statistical machine learning folks. In fact, it’s best if those experts bring other thinking styles to the table, welcomed by the ML folk. Otherwise, the result will be groupthink.
Avoiding AI groupthink: An oil and gas metaphor
Think of today’s LLMs as the tech industry equivalent of the energy industry’s kerosene, first distilled from coal and shale oil by the Chinese as far back as 1500 BC. Kerosene today is used as a base for jet fuel. But back then, the most common use for kerosene was as lamp oil and to heat homes.
The process used for making kerosene through the mid-1800s was expensive, just as LLMs are expensive today. But then people in Poland, Canada and the US discovered how to distill kerosene from petroleum. By the 1860s, kerosene displaced whale oil as the favored fuel for lamps.
In 1863, John D Rockefeller with his brother William and some other partners founded what became Standard Oil in the US. Standard Oil first gained prominence by making kerosene much more efficiently and cheaply than its competitors. Standard acquired its competitors and put the inefficient ones out of business.
Through the early 1900s Standard Oil diversified its products considerably by diversifying its petrochemical refineries. Instead of discarding the by-product gasoline, it used gasoline to power its own machines, and gasoline then became the standard fuel for cars. It bought a company that invented Vaseline, a petroleum-based lubricant and moisturizer. It developed and sold paraffin, a synthetic replacement for beeswax. Today, over 6,000 commercially made products are petroleum based.
A hybrid AI approach
Standard Oil created a system to extract, refine and distribute petroleum and petroleum-based products for various purposes. Similarly, what we need to create now is the data equivalent of a comparable system that extracts, refines, stores, and provides discoverability of and access to ready-to-use data and data products–not applications.
Today’s machine learning relies on probabilistic modeling only, as pointed out before. A hybrid AI approach called neurosymbolic AI, by contrast, incorporates the reasoning capabilities of knowledge representation and rules along with neural nets.
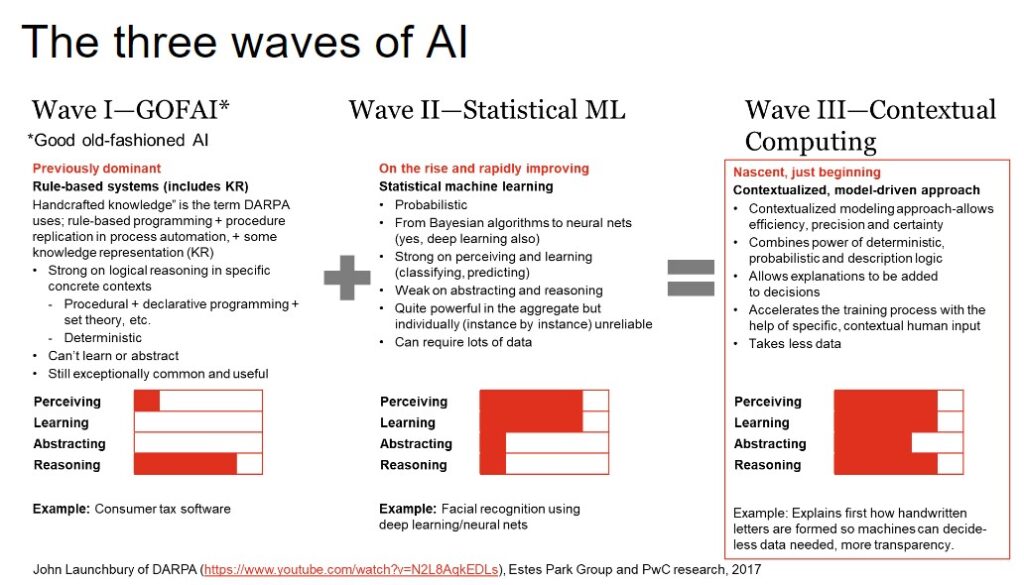
The following diagram, based on a video John Launchbury made when he was at DARPA, spells out how the probabilistic and deterministic can be blended together, which is how machines can reason their way to more certainty. With the right data, that is. Neurosymbolic AI is a means of contextual computing in Wave III. Statistical machine learning alone is still in Wave II.
To get to Wave III, data scientists need to collaborate with those who understand and value the symbolic side of AI.
{kind=link}