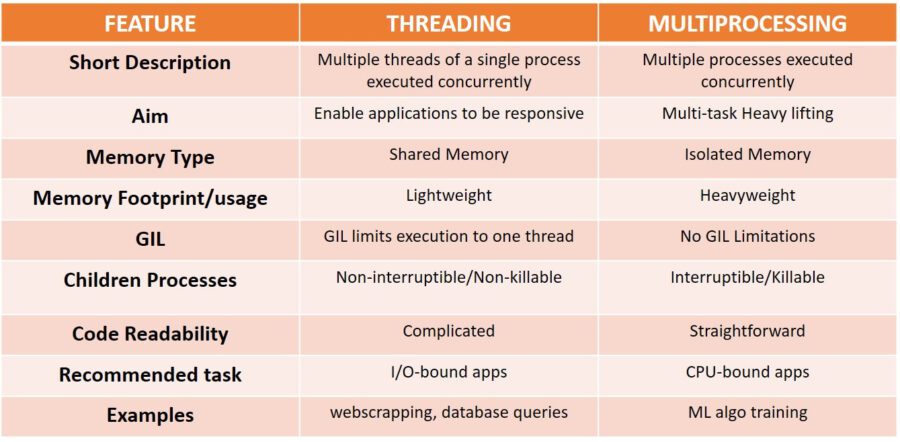
Neuromancer Blues” is a series of posts where I would like the reader to find guidance about overall data science topics such as data wrangling, database connectivi...
Randomised algorithms are built on statistical features played by random numbers. Quicksort is a good example to illustrate this algorithm. For instance, in a class of ...
There are some expressions about data that are getting a bit tired: Data is the new oil; In God We Trust (all others must bring data); Buy data, sell high… Okay, yo...
How can you transition your business analytics from a manual, slow, and prone to error data transformation process in Excel into a reliable and automated solution to empo...
Graph algorithms such as PageRank, community detection and similarity matching have moved from the classroom to the data scientist’s and business analyst’s to...
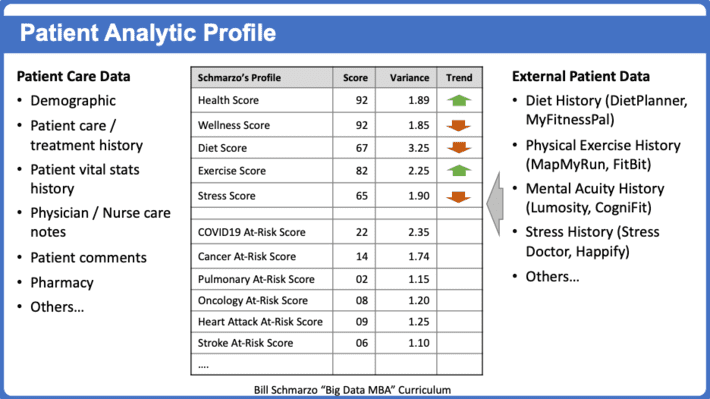
The COVID-19 crisis has hammered home the importance for organizations to become more digital. And I suspect that most organizations are thinking that just means being ...
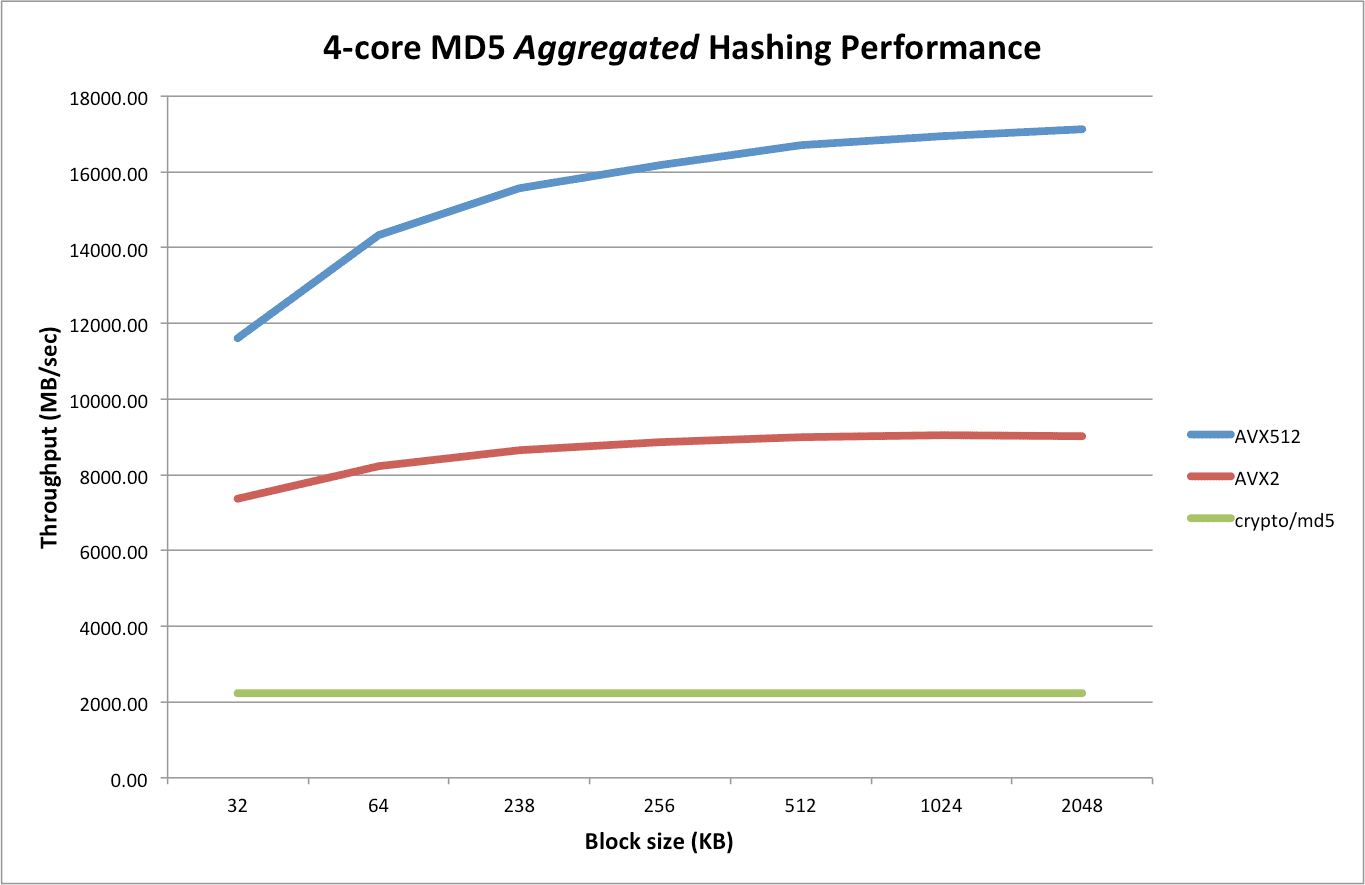
By Frank Wessels Introduction While MD5 hashing is no longer a good choice when considering a hash function, it is still being used in a great variety of applications. As...
For the first time, I taught an AI for Cyber Security course at the University of Oxford. I referred to this paper from Johns Hopkins which covered Deep Neural networks f...
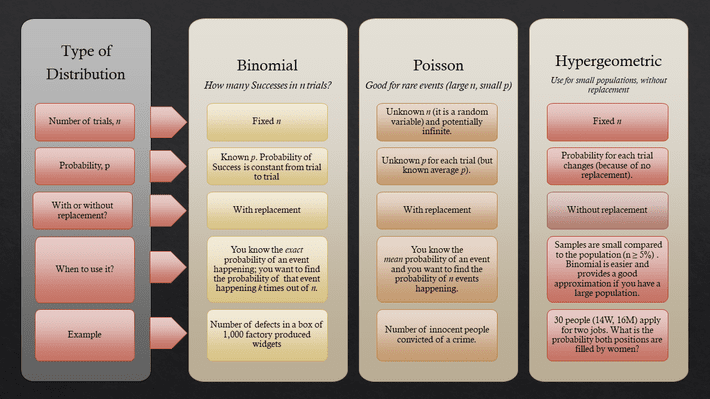
There are a few key differences between the Binomial, Poisson and Hypergeometric Distributions. These distributions are used in data science anywhere there are dichotom...
With mathematical optimization, companies can capture the key features of their business problems in an optimization model and can generate optimal solutions (which are u...