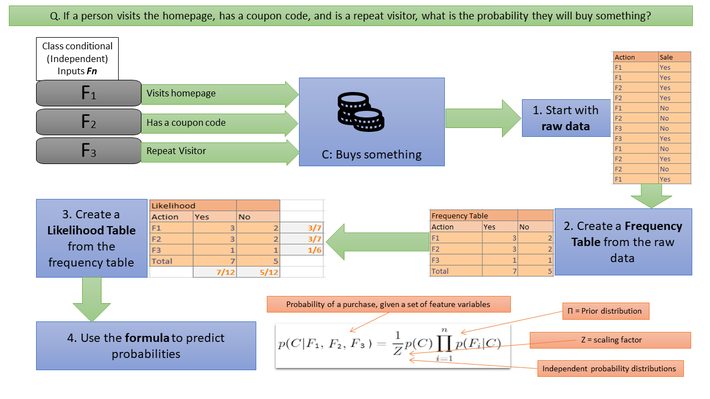
Naive Bayes is a deceptively simple way to find answers to probability questions that involve many inputs. For example, if you’re a website owner, you might be inte...
Lecture notes for the Statistical Machine Learning course taught at the Department of Information Technology, University of Uppsala (Sweden.) Updated in March 2019. Aut...
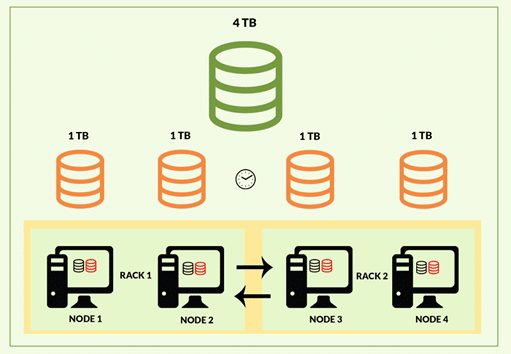
Hadoop and Spark are software frameworks from Apache Software Foundation that are used to manage ‘Big Data’. There is no particular threshold size which classi...
Summary: Finally there are tools that let us transcend ‘correlation is not causation’ and identify true causal factors and their relative strengths in our models....
So many fascinating and deep results have been written about the number (1 + SQRT(5)) / 2 and its related sequence – the Fibonacci numbers – that it would tak...
The world has taken several leaps in the technical aspects in the past few years. This has resulted in tremendous growth for the entire globe. With proper modes of commun...
Quora contribution written by Chomba Bupe. I am actually not even aware of any machine learning (ML) problem that is considered to have been solved recently or in the pas...
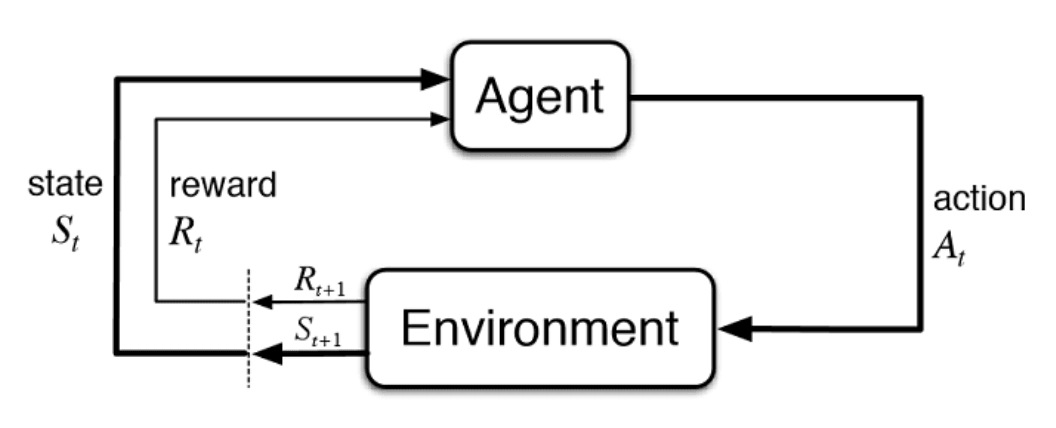
Imagine you’re completing a mission in a computer game. Maybe you’re going through a military depot to find a secret weapon. You get points for the right actions (kil...
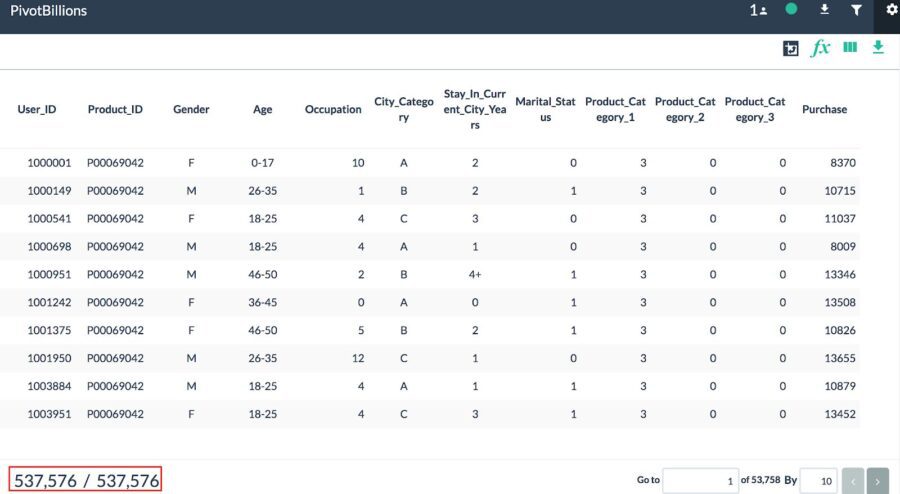
Sales data analyses can provide a wealth of insights for any business but rarely is it made available to the public. In 2018, however, a retail chain provided Black Frida...
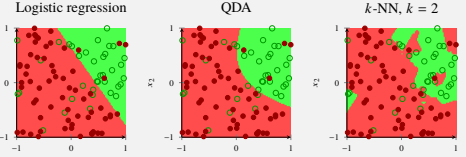
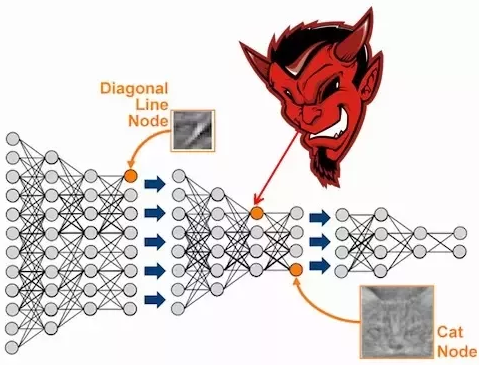
The diverse fields in which machine learning has proven its worth is nothing short of amazing. At the heart of machine learning are the various algorithms it employs to c...