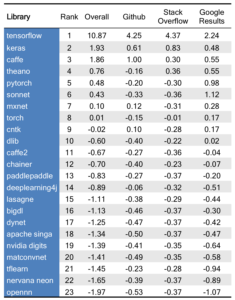
Michael Li is founder and CEO at The Data Incubator. The company offers curriculum based on feedback from corporate and government partners about the technologies they ...
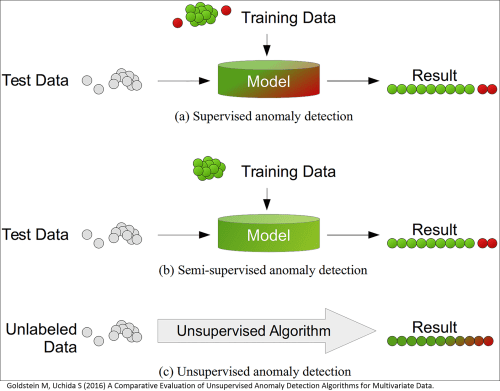
Summary: Unless you’re involved in anomaly detection you may never have heard of Unsupervised Decision Trees. It’s a very interesting approach to decision trees tha...
In one of my previous articles, you can learn the process about how discoveries are made by research scientists, from stating the problem, exploratory analysis, testing, ...
The technology revolution promises to deliver a lot of rewards for organizations that take it by the horns and implement it. The spread of the Internet across every facet...
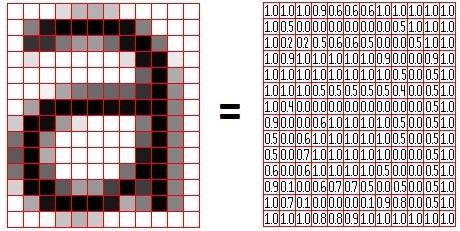
Digital image processing is a discipline that studies image processing techniques. The image referred in this research is a static image form vision sensors (webcam). Mat...
In this post, I explore strategies to switch to Data Science mid-career. This switch is not easy, but based on the experience of many who I have taught/mentored/recruited...
Every year, late in the summer, waves of warm air come off the African continent and enter into the warm open seas of the mid-Atlantic Ocean. When the conditions are righ...
Which type are you? Can you recognize the programming language used in this illustration? Click on the picture to zoom in. Originally posted here. DSC Resources Servi...
Here is a new set of easy questions recently published, covering Statistics Programming (General, Big Data, Python, R, SQL) Modeling Behavioral Culture Fit Problem-Solvin...
Here is a new set of easy questions recently published, covering Statistics Programming (General, Big Data, Python, R, SQL) Modeling Behavioral Culture Fit Problem-Solvin...