
Michael Li is founder and CEO at The Data Incubator. The company offers curriculum based on feedback from corporate and government partners about the technologies they are using and learning, for masters and PhDs.
The Rankings
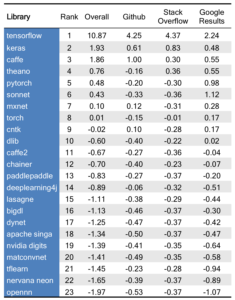
Below is a ranking of 23 open-source deep learning libraries that are useful for Data Science, based on Github and Stack Overflow activity, as well as Google search results. The table shows standardized scores, where a value of 1 means one standard deviation above average (average = score of 0). For example, Caffe is one standard deviation above average in Github activity, while deeplearning4j is close to average. See below for methods.
Results and Discussion
The ranking is based on equally weighing its three components: Github (stars and forks), Stack Overflow (tags and questions), and Google Results (total and quarterly growth rate). These were obtained using available APIs. Coming up with a comprehensive list of deep learning toolkits was tricky – in the end, we scraped five different lists that we thought were representative (see methods below for details). Computing standardized scores for each metric allows us to see which packages stand out in each category. The full ranking is here, while the raw data is here.
TensorFlow dominates the field with the largest active community
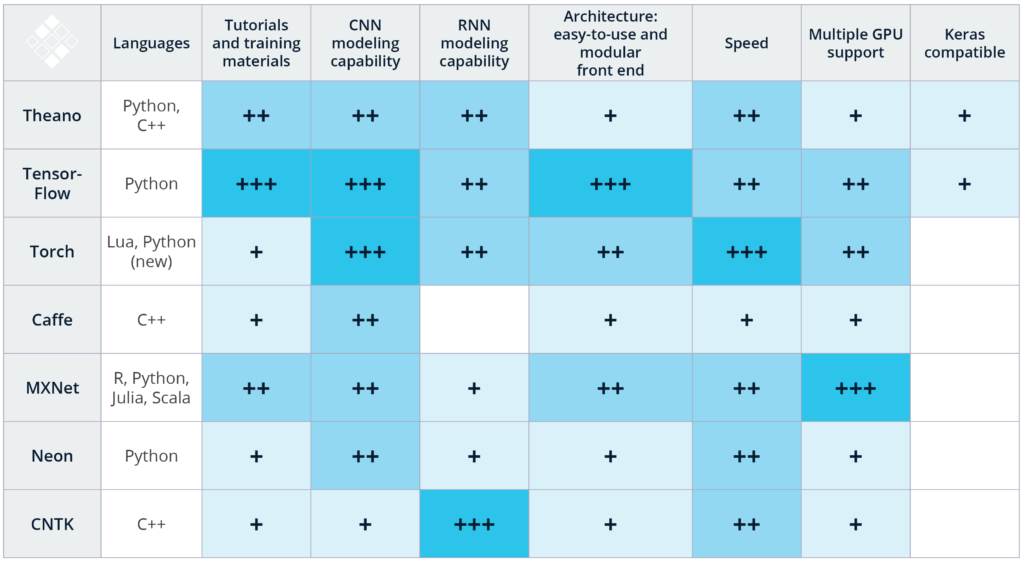
TensorFlow is at least two standard deviations above the mean on all calculated metrics. TensorFlow has almost three times as many Github forks and more than six times as many Stack Overflow questions than the second most popular framework, Caffe. First open-sourced by the Google Brain team in 2015, TensorFlow has climbed over more senior libraries such as Theano (4) and Torch (8) for the top spot on our list. While TensorFlow is distributed with a Python API running on a C++ engine, several of the libraries on our list can utlize TensorFlow as a back-end and offer their own interfaces. These include Keras (2), which will soon be part of core TensorFlow and Sonnet (6). The popularity of TensorFlow is likely due to a combination of its general-purpose deep learning framework, flexible interface, good-looking computational graph visualizations, and Google’s significant developer and community resources.
Caffe has yet to be replaced by Caffe2
Caffe takes a strong third place on our list with more Github activity than all of its competitors (excluding TensorFlow). Caffe is traditionally thought of as more specialized than Tensorflow and was developed with a focus on image processing, objection recognition, and pre-trained convolutional neural networks. Facebook released Caffe2 (11) in April 2017, and it already ranks in the top half the deep learning libraries. Caffe2 is a more lightweight, modular, and scalable version of Caffe that includes recurrent neural networks. Caffe and Caffe2 are separate repos, so data scientists can continue to use the orginial Caffe. However, there are migration tools such as Caffe Translator that provide a means of using Caffe2 to drive existing Caffe models.
Keras is the most popular front-end for deep learing
Keras (2) is highest ranked non-framework library. Keras can be used as a front-end for TensorFlow (1), Theano (4), MXNet (7), CNTK (9), or deeplearning4j (14). Keras performed better than average on all three metrics measured. The popularity of Keras is likely due to its simplicity and ease-of-use. Keras allows for fast protoyping at the cost of some of the flexibility and control that comes from working directly with a framework. Keras is favorited by data scientists experimenting with deep learning on their data sets. The development and popularity of Keras continues with R Studio recently releasing an interface in R for Keras.
Theano continues to hold a top spot even without large industry support
In a sea of new deep learning frameworks, Theano (4) has the distiction of the oldest library in our rankings. Theano pioneered the use of the computational graph and remains popular in the research community for deep learning and machine learning in general. Theano is essentially a numerical computation library for Python, but can be used with high-level deep learning wrappers like Lasagne (15). While Google supports TensorFlow (1) and Keras (2), Facebook backs PyTorch (5) and Caffe2 (11), MXNet (7) is the offical deep learning framework of Amazon Web Services, and Microsoft designed and maintains CNTK (9), Theano remains popular without offical support from a technology industry giant.
Sonnet is the fastest growing library
Early in 2017 Google’s DeepMind publicly released the code for Sonnet (6), a high-level object oriented library built on top of TensorFlow. The number of pages returned in Google search resutls for Sonnet has grown by 272% from this quarter compared to the last, the largest of all the libraries we ranked. Although Google aquired the British artifical intelligence company in 2014, DeepMind and Google Brain have remained mostly independent teams. DeepMind has a focus on artifical general intelligence and Sonnet can help a user build on top of their specific AI ideas and research.
Python is the language of deep learning interfaces
PyTorch (5), a framework whose sole interface is in Python, is the second fastest growing library on our list. Compared to last quarter, PyTorch had 236% more Google search results. Out of the 23 open-source deep learning frameworks and wrappers we ranked, only three did not have interfaces in Python: Dlib (10), MatConvNet (20), and OpenNN (23). C++ and R interfaces were available in just seven and six of the 23 libraries, respectively. While the data science community is somewhat close to a consensus when it comes to using Python, there are still many options for deep learning libraries.
Limitations
As with any analysis, decisions were made along the way. All source code and data is on our Github Page. The full list of deep learning libraries came from a few sources.
Naturally, some libraries that have been around longer will have higher metrics, and therefore higher ranking. The only metric that takes this into account is the Google search quarterly growth rate.
The data presented a few difficulties:
- neural designer and wolfram mathematica are proprietary and were removed
- cntk is also called microsoft cognitive toolkit, but we only used the originial ctnk name
- neon was changed to nervana neon
- paddle was changed to paddlepaddle
- Some libraries were obviously derivatives of other libraries, such as Caffe and Caffe2. We decided to treat libraries individidually if they had unique github repositories.
Methods
All source code and data is on our Github Page.
We first generated a list of 23 open-source deep learning libraries from each of five different sources, and then collected metrics for all of them, to come up with the ranking. Github data is based on both stars and forks, Stack Overflow data is based on tags and questions containing the package name, and Google Results are based on total number of Google search results over the last five years and the quarterly growth rate of results calculated over the past three months as compared to the prior three months.
{kind=link}
A few other notes:
- Several of the libraries were common words (caffe, chainer, lasagne), for this reason the search terms used to determine the number of google search results included the library name and the term “deep learn
ing”. - Any unavailable Stack Overflow counts were converted to zero count.
- Counts were standardized to mean 0 and deviation 1, and then averaged to get Github and Stack Overflow scores, and, combined with Serch Results, the Overall score.
- Some manual checks were done to confirm Github repository location.
All data was downloaded on September 14, 2017.
Resources
Source code is available on The Data Incubator‘s GitHub. If you’re interested in learning more, consider
- Data science corporate training
- Free eight-week fellowship for masters and PhDs looking to enter industry
Authors
{kind=link}