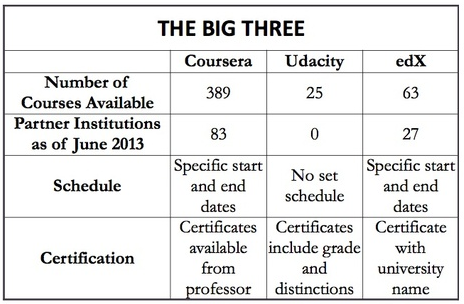
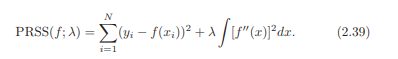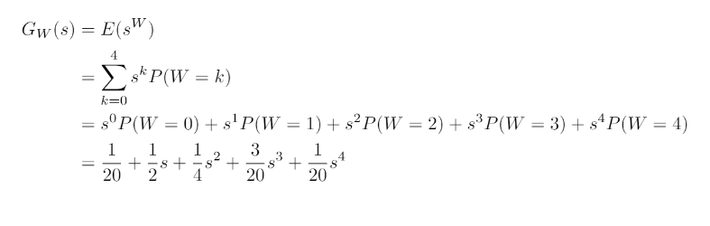It all depends on the classes that you attended. Some are worth listing, some are best not to mention. Here I review of few of these data science curricula, and the impre...
In practice, the Data Scientist wants to know which formula they will write in their Excel sheet when they enter all the data available into it: Bayes’ or usual? The an...
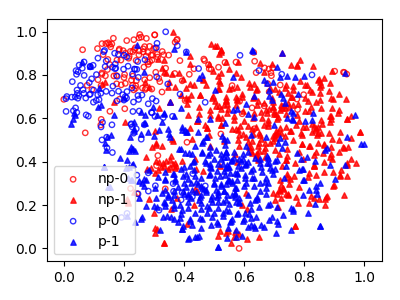
Image recognition and classification is a rapidly growing field in the area of machine learning. In particular, object recognition is a key feature of image classificatio...
Grab a copy of The Elements of Statistical Learning (“the machine learning bible”) and you might be a little overwhelmed by the mathematics. For example, thi...
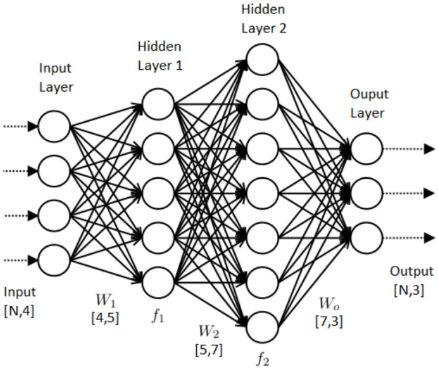
This article was written by Jason Brownlee. Artificial neural networks have two main hyperparameters that control the architecture or topology of the network: the numbe...
This article was written by Enda Ridge. Data Scientists need to communicate without jargon so customers understand, believe and care about their recommendations. Here is...
This article was written by Vitaly Shmatikov. Machine learning is eating the world. The abundance of training data has helped ML achieve amazing results for object reco...
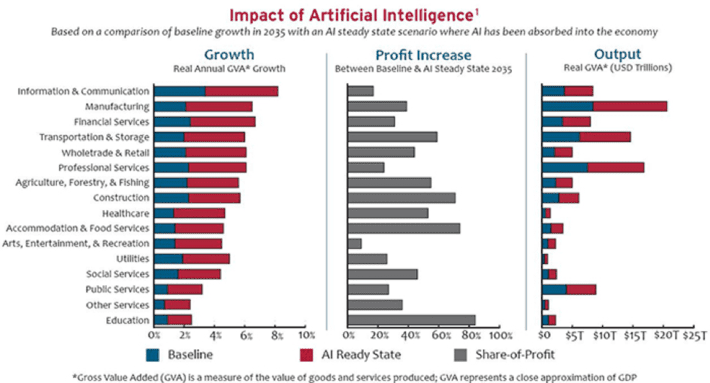
There are several technology and business forces in-play that are going to derive and drive new sources of customer, product and operational value. As a set up for this ...
PREFACE Previously, I tackled the Gambler’s Ruin problem using conditional probability and difference equations as well as visualising the simulations of the proble...
Introduction During the most recent decade, the force originating from both the scholarly community and industry has lifted the R programming language. Also, they have wo...