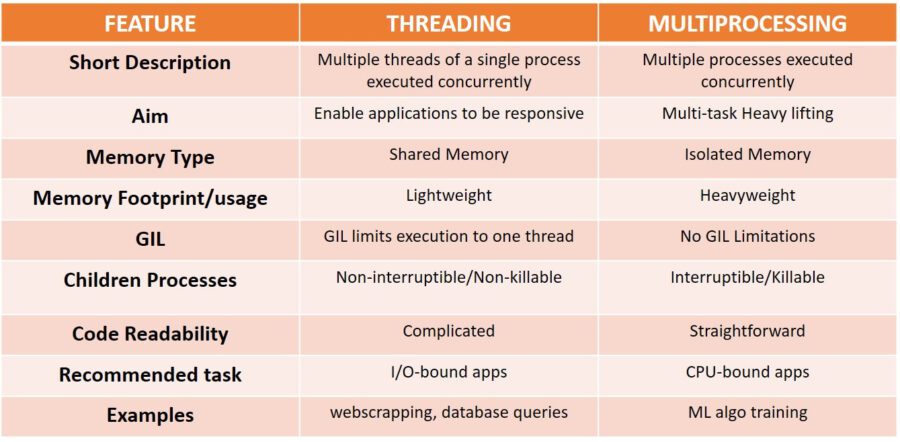
Neuromancer Blues” is a series of posts where I would like the reader to find guidance about overall data science topics such as data wrangling, database connectivi...
Randomised algorithms are built on statistical features played by random numbers. Quicksort is a good example to illustrate this algorithm. For instance, in a class of ...
There are some expressions about data that are getting a bit tired: Data is the new oil; In God We Trust (all others must bring data); Buy data, sell high… Okay, yo...
Graph algorithms such as PageRank, community detection and similarity matching have moved from the classroom to the data scientist’s and business analyst’s to...
For the first time, I taught an AI for Cyber Security course at the University of Oxford. I referred to this paper from Johns Hopkins which covered Deep Neural networks f...
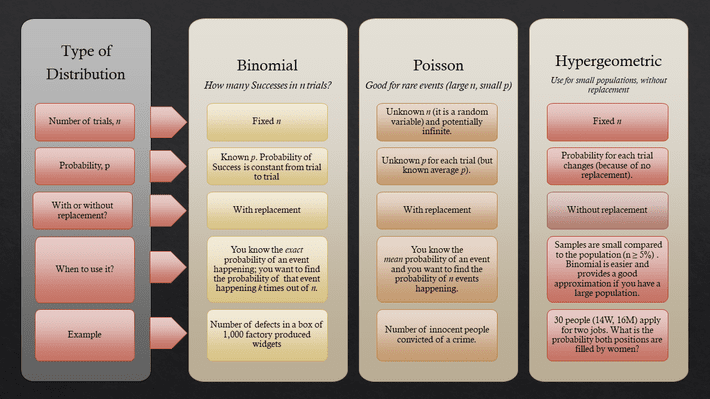
There are a few key differences between the Binomial, Poisson and Hypergeometric Distributions. These distributions are used in data science anywhere there are dichotom...
A Generative model aims to learn and understand a dataset’s true distribution and create new data from it using unsupervised learning. These models (such as StyleGAN) h...
Summary: Now that you have a little time for introspection, how about reviewing the performance of your chatbots. Chances are this lock down period has given you a litt...
Mike Romeri, A2Go CEO April 21, 2020 As commerce slowly opens up in our world over the next few months, competition for customers will accelerate like never before. It re...
The eLearning industry is already surging on today’s words and finding ways to enhance the learning experience through leading technologies that are loved by many. Rece...