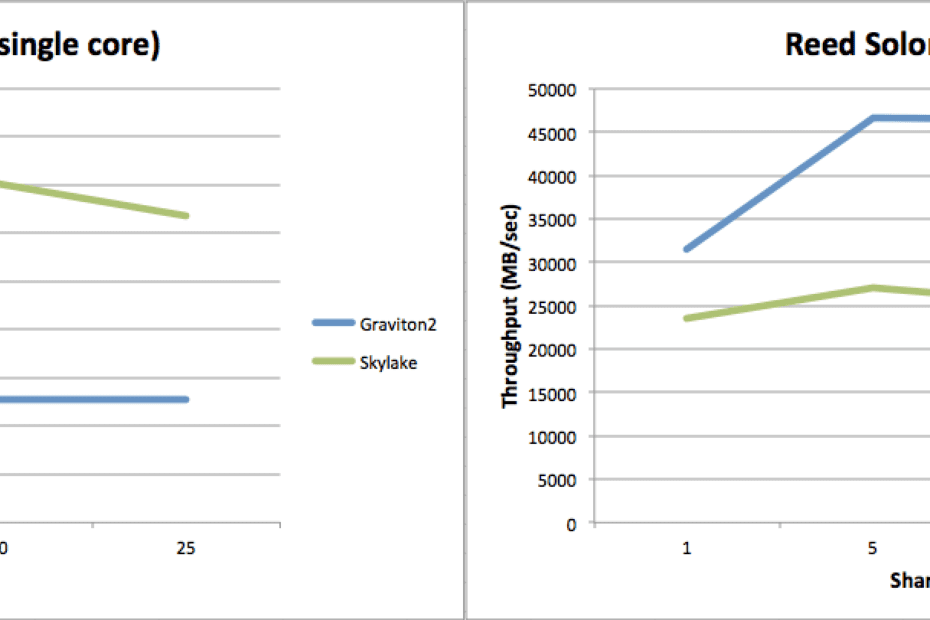
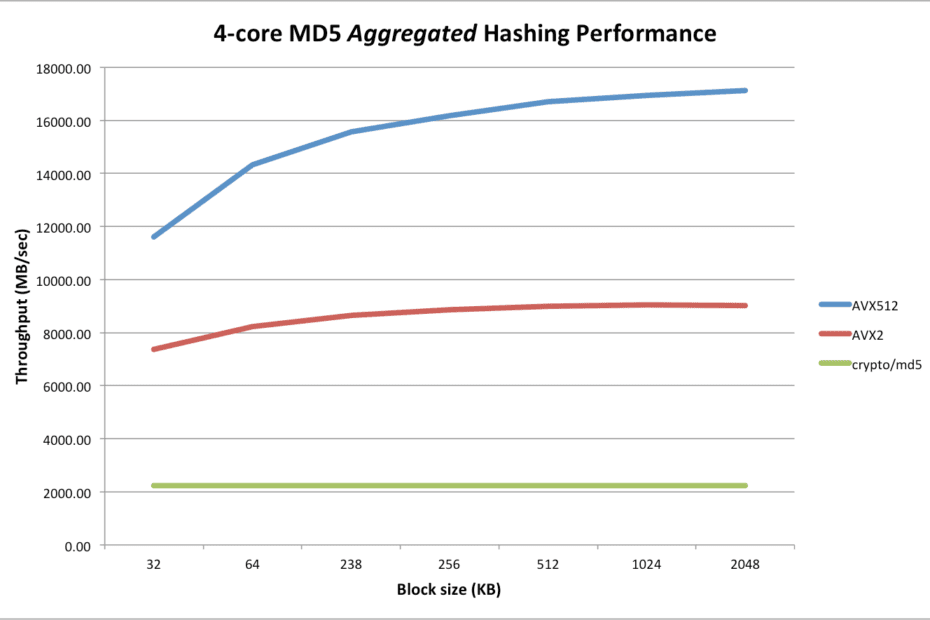
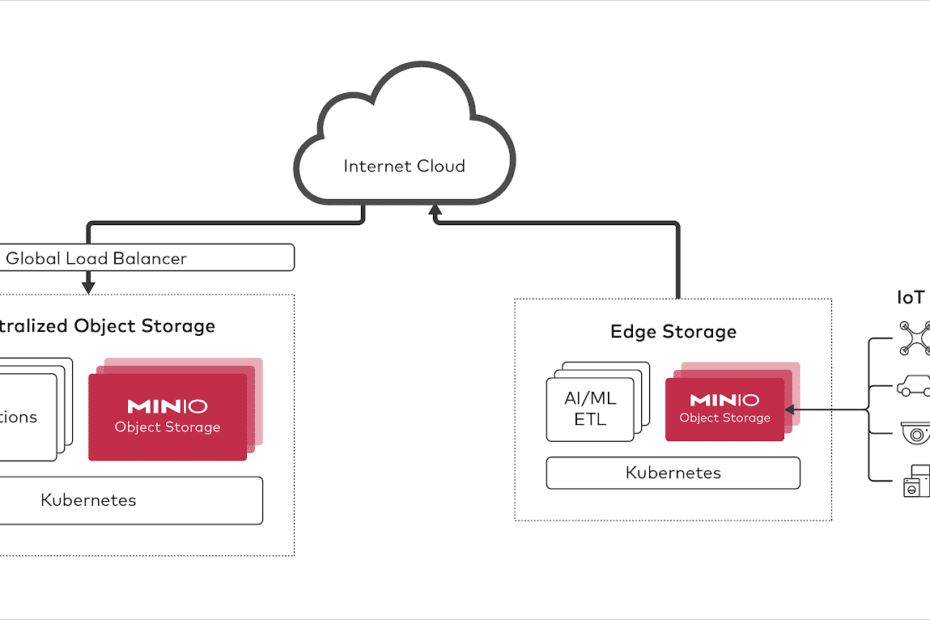
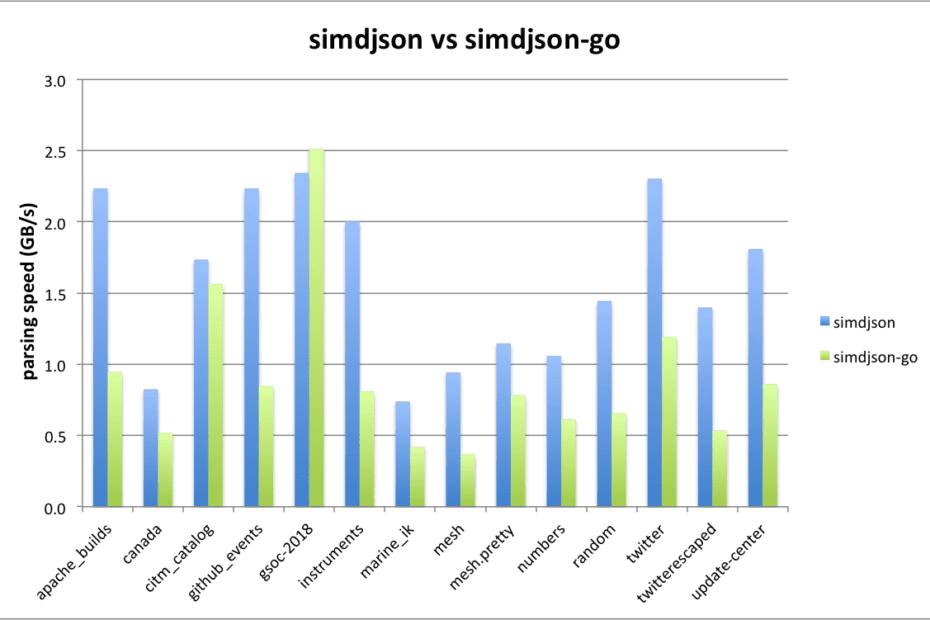
Why Cassandra is a poor choice for an object storage metadata database

Cassandra is a popular, tried-and-true NoSQL database that supports key-value wide-column tables. Like any powerful tool, Cassandra has its ideal use cases – in particular,… Read More »Why Cassandra is a poor choice for an object storage metadata database