
Edge computing is a hot topic and carries with it some confusion, particularly around storage. Handling data properly at the edge can ensure a scalable, cost-effective and secure infrastructure – but failing to set up the right architecture can lead to data loss, security vulnerabilities and sky-high costs related to the bandwidth needed to transfer data repeatedly to and from the public cloud. Bandwidth is a key consideration from an architecture perspective, and the reason why is clear: it is 4X more expensive per GB than storage (.023 vs. .09 on AWS for example).
While there are multiple models, ultimately, we think they can be simplified down to just two: edge storage and edge cache. This post looks at both models and articulates the storage attributes that matter to deliver against them.
Edge Storage
The edge storage model is employed when the goal is to do your processing and analytics on the edge, filtering out the noise and retaining/sending up just the insights and data associated with those insights. In this model, the application, compute and storage exist at the edge and are designed to store and process data in situ. The goal is not to store PBs of data at the edge – rather, this model envisions 100s of GBs up to a few PBs or so. Visually it looks like this:
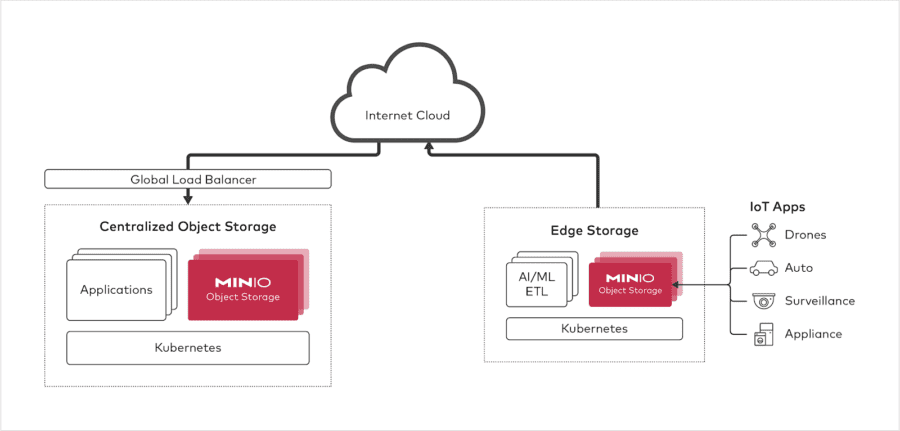
At the most remote edge you have the data producing devices, coupled with storage and compute/analytics. The compute/analytics can range from something like a Splunk DSP to a deep neural network model, but the key point here is that there is ETL, processing and insight generation at the remote edge. These instances are containerized and managed with Kubernetes as data pipelines.
Kubernetes effectively imposes the requirement that the storage be disaggregated and object based.
To complete the architecture, one would add a load balancer, another layer of Kubernetes and then have an origin object storage server and the application layer (training the models, doing large scale analytics etc) in a more centralized location.
This model is employed by restaurants like Chick-fil-A. It is used for facial recognition systems. It is the default design for manufacturing use cases as well as 5G use cases.
In each case, there is enough storage and computation onsite or in an economically proximate location to learn from the data.
Let’s use an example of a car producing data from sensors – an area where MinIO has considerable deployment expertise. The purpose of collecting data is to build and train machine learning models. Cars don’t have the compute resources internally to do the training, which is the most GPU-intensive part. In this case, the data is sent to an edge data center to build and train the machine learning models. Once the model is trained, it can be sent back to the car and used to make decisions and draw conclusions from new data coming in from sensors.
It makes sense to distribute the training and process geographically to be as close to the devices as possible.
Eventually, that data will end up in the cloud (public or private). It will accumulate quickly and in the case of autonomous vehicles will be multiple PBs in no time. As a result, you will need the same storage on each end – at the edge and in the cloud.
Object storage is the storage of choice in the cloud. As a result, object storage is the storage of choice for the edge. We get into what attributes the storage at the edge needs to have below – but it is important to note that legacy SAN/NAS systems are inflexible and often incompatible for these use cases since data processing applications are adopting S3 API natively.
A quick note on the private cloud. Some conflate the edge with the private cloud, but this is a mistake. The private cloud is an emergent force that has blossomed as traditional IT adopts the practices and approaches of the public cloud – from RESTful APIs to microservices and containerization. The private cloud looks and feels like the public cloud but with superior economics, data security and performance.
The edge is different. The edge is a net new world.
Yes, it follows the cyclical technology path of centralization -> decentralization -> centralization -> decentralization but it is taking advantage of endpoints that simply didn’t exist before – cars, cameras, mobile apps and appliances and technology that didn’t exist before – for high-performance, lightweight object storage and AI/ML. As a result, there needs to be a new architectural framework.
Edge Caching
Recalling the first rule of the edge: to treat bandwidth as the highest cost component (4X on AWS), we find our second core edge case: edge caching. Edge caching is not a new concept, CDNs are decades old – but it is also one where object storage has again changed the rules. CDNs need to be tightly integrated into the object storage system in order to maintain the security and consistency model of the objects.
In this model, the edge serves as a gateway cache, creating an intermediary between the application and the public cloud. In this scenario, the gateways are backed by servers with a number of either hard drives or flash drives and are deployed in edge data centers around the world. It looks like this:
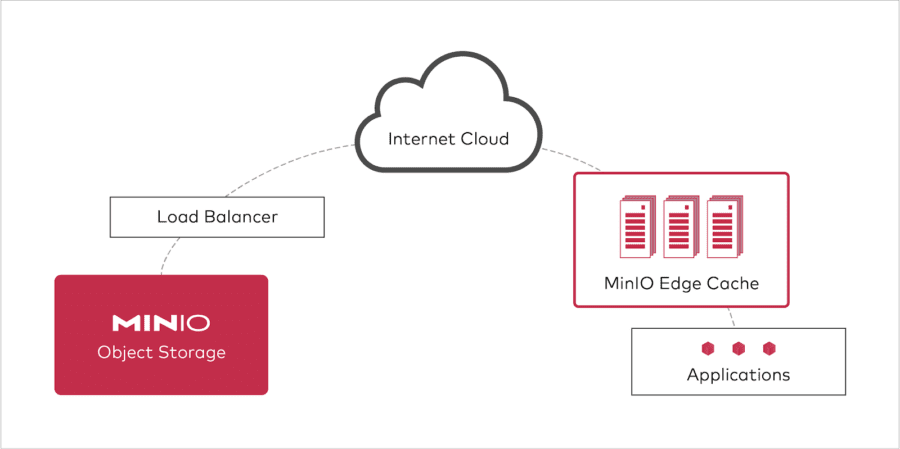
All access to the public cloud goes through these caches (write-through cache), so data is uploaded to the public cloud with strict consistency guarantee. Subsequent reads are served from the cache based on ETAG match or the cache control headers. This architecture reduces costs by decreasing the bandwidth needed to transfer data, improves performance by keeping data cached closer to the application and also reduces the operational cost – the data is still kept in the public cloud, just cached at the edge, so it is still there if the edge data center burns to the ground.
With MinIO’s object storage gateway, one is also able to employ a shared nothing architecture with zero administration. You deploy it once and forget it. Adding a node, two nodes, two thousand nodes – it does not matter, they are architecturally independent of one another and totally stateless. Just keep scaling. If a node dies, let it go.
The Attributes of the Edge
Regardless of which type of architecture you are building at the edge, there are certain attributes that need to be backed in to any edge storage system, whether in an edge processing center, in IoT devices themselves or as part of an edge caching system. The first, as noted, is that the storage needs to be object based and accessible over HTTPs. Object is the default pattern for the edge. File and block protocols cannot be extended beyond the local network.
There are, however, additional requirements for that object storage and they are as follows:
Resilience
Resilience is essential for storage at the edge. It is harder for skilled engineers to physically access and maintain IoT devices or edge data centers. At the same time, the drives in IoT devices – and even in edge data centers – are subject to harsher physical conditions than drives in a traditional data center.
These architectures, and in particular the storage component, need to be able to fail in place. Drive failures will happen. Without the right architecture, drive failures can lead to data loss. In addition to losing data, replacing drives can be an operational nightmare because they require experienced technical staff to visit geographically distributed data centers and/or attend thousands of edge devices.
It’s crucial for the storage architecture to use self-healing and automation to ensure data is safe even when drives fail, as well as to build in the ability to automatically fail over to other data centers if all of the drives in a particular edge location fails.
Software Defined + Container Friendly + Open Source
Software defined storage solutions provide a measure of flexibility that does not exist with traditional systems. They can run on a variety of hardware platforms with equal ease and can be easily maintained from afar.
Further, software defined storage solutions are superior for containerization and orchestration. As we have written, it is impossible to containerize a hardware appliance. Given the need to spin up/down and grow/shrink edge solutions, a kubernetes-friendly solution is a requirement.
Third, solutions need to be open source. This is a given for telcos who have long seen the value in open source, but is also important to other industries where freedom from lock in, freedom to inspect and freedom to innovate are key to the selection process. Another underappreciated value proposition for open source is ease of adoption – it is run in a highly heterogeneous number of configurations and is hardened in ways that proprietary software can never be.
Stateless
Edge storage systems need to be made up of completely disposable physical infrastructure. If they catch fire, there should be no data loss. The critical state should be stored in the public cloud so that individual hardware elements can be disposable.
It’s impossible to treat drives at the edge as pets. They will almost invariably be subject to tougher physical conditions, which leaves them at risk for not just failure but also corruption.
Speed
The faster you can process data, the faster you can make business decisions. Speed is one of the primary reasons for moving data processing away from traditional data centers and the public cloud. The ability to speed up data processing and data transfer is essential for getting the most out of edge computing.
Latency is tricky to solve, even when dealing with data centers located at the edge. Building applications that can process data quickly requires architecting the system in such a way that applications can process data in memory. The key to speed at the edge is to remove any dependency on the high-latency networking.
Lightweight
Edge devices are small. For a storage system to be viable at the edge, it has to be able to provide speed, resilience and security with very little compute and storage resources. The ability to run on devices with low resources of a Raspberry Pi, for example, is essential to building a storage system that might run on a single solid state drive in an IoT device. The key, however, is for that single solid state drive to look and act like a full-blown server from an application and API perspective.
Security
There is no way to completely ensure the physical security of either edge data centers or IoT devices. Ensuring encryption at rest and in transit is critical, because placing the same physical security measures around an edge data center as would be in place around a traditional data center is impractical – and it’s impossible in the case of IoT devices. The physical vulnerability of drives at the edge makes encryption essential, so that even if data is accessed it can’t be read or tampered with.
Summary
Designing the appropriate architecture is critical in the edge world. This post presents two models, one where data is gathered at the edge and another where the data is pushed to the edge. While the models are fundamentally different, the storage choice is the same: object.
Further, the object storage requires certain attributes around resilience, performance, security and flexibility that narrow the consideration set.
{kind=link}