

- A new study evaluates ML models that classify fake news from fact.
- The best models can only achieve up to 77.2% accuracy.
- AI will probably never be able to fully replace the nuanced analysis of human journalists.
Many Natural Language Processing (NLP) techniques exist for detecting “fake news”. Multi-phase algorithms with Determined Decision Trees, Gradient Enlargement, and others have been used by various researchers and organizations with varying results. One study from researchers at Rensselaer Polytechnic Institute reported 83% accuracy in predicting whether a news article is from a reliable or unreliable source [1], while Facebook’s 2019 attempt at developing an algorithm failed miserably, with some users experiencing a “maelstrom” of fake news [2].
A new study, published in the November 2021 issue of the Journal of Emerging Technologies and Innovative Research [3] performed an analysis of a wide range of AI models for efficacy in identifying reliable news, finding that models generally perform poorly, ranging from 60% to 77% accuracy. That’s a huge amount of fake news slipping through the net.
The Classification Problem
Separating fake news from real news is a challenge even for the most sophisticated AI. Simple content-related programs and shallow marking of the speech part (POS) fail to consider contextual information and are unable to accurately classify news stories as fact or fake unless combined with more sophisticated algorithms. Even then, algorithms fail to achieve high accuracy, faltering when it comes to deciphering the nuances of human language and opinion.
Compounding the problem is that existing models created to detect one type of “fake” may not work well with others. For example, Feng and colleagues [4] AI model successfully classified deceptive from non-deceptive social media reviews partly using a PCFG (probabilistic context free grammars) feature set. However, while PCFGs features worked well for fake reviews, they added little to the efficacy of models detecting fake news.
A Starting Point for Classification
Many attempts have been made at classifying media sources as unreliable (or not), and no system is perfect because a “reliable” news source for one person is a biased source for the next. To combat the issue of identifying data sources, the study authors referred to Conroy and colleagues work [5], which outlined several requirements for a useful trustworthy/untrustworthy reference list. These include:
- Availability of both truthful and deceptive instances,
- Homogeneity in lengths and writing matter,
- Verifiability of ‘ground truth’—whether a source is generally considered credible or not.
A dataset of 1 million articles was obtained for the study, which included both verified trustworthy articles (e.g., from Reuters) and verified untrustworthy. This was cleaned and reduced to 11051 articles.
The Analysis
The team evaluated models trained on three feature sets:
- Bigram Term Frequency-Inverse Document Frequency.
- Normalized frequency of parsed syntactical dependencies.
- A union of (1) and (2)
Articles were rubbed of the source name, Twitter handles, and email addresses, so that the AI couldn’t use those in the classification process. After cleaning the data and generating features, the study authors executed a 90/10 random test-train split on the dataset, which was fed into a modeling pipeline. Models were executed up to 50 times and tested on the 10% holdout data. The following graphic shows the pipeline from the study:
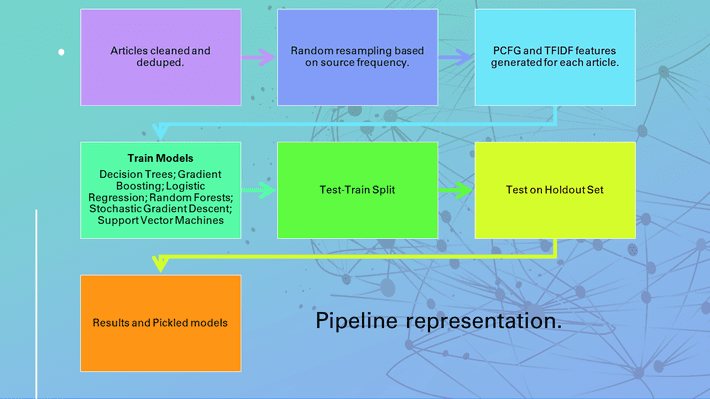
Results
The study showed that although machine learning shows promise in detecting fake news, none of the models performed especially well. The highest accuracy was achieved by the SVM with PCFG and TF-IDF bi-gram features, at 73.6%. The Stochastic Gradient Descent performed model performed the best overall, for example just with PCFG features or TF-IDF bi-gram features. The following image is a snapshot of the study results:
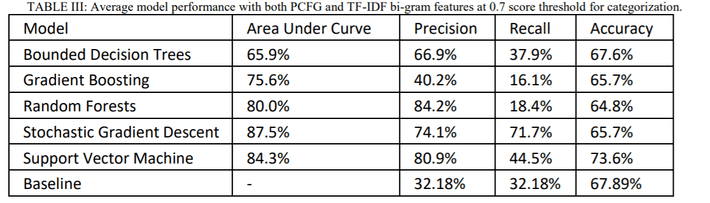
Going forward, the authors hope to make model improvements. Specifically, they hope to address issues like the oversensitivity of TF-IDFs to key topics, and technical challenges with their vectorized approach. Even so, the big picture is that it is highly unlikely we will ever be able to rely on AI to fully filter fake news. While AI can process a lot of information quickly, it simply doesn’t have the fact-checking skills of a journalist. It’s much more likely that AI will be able to filter out the bulk of fake news, leaving the ultimate task to human fact checkers.
References
Top image: Adobe Creative Cloud [Licensed]
Pipeline graphic by author (based on graphic from [2]).
[1] In Just 21 Days, Facebook Led New India User to Porn, Fake News
[2] Tell Me Who Your Friends Are: Using Content Sharing Behavior for Ne…
[3] Fake News Prediction in Machine Learning
[4] S. Feng, R. Banerjee, and Y. Choi, “Syntactic stylometry for deception detection,” in Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers-Volume 2, Association for Computational Linguistics, 2012, pp. 171–175
[5] N. J. Conroy, V. L. Rubin, and Y. Chen, “Automatic deception detection: Methods for finding fake news,” Proceedings of the Association for Information Science and Technology, vol. 52, no. 1, pp. 1–4, 2015.
{kind=link}