
Until very recently, most organizations have seen two distinct, non-overlapping work streams when building an AI enabled application: a development path and a data science path.
Often, both groups are actually building similarly scripted functional solutions using something like python or C/F#. Further, once a data scientist finishes the evaluation and model selection step of the data science process , I’ve found there to be a “confusion vacuum” when it comes to best practices around integrating into existing or augmenting new business processes, each side not fully understanding how to support the other / when to engage. Much of the convergence, in my opinion, has been fueled by the growing popularity and usage of container services like Docker and Kubernetes especially in the DevOps world.
So, how do these swimlanes converge, you ask? I’m glad you did!
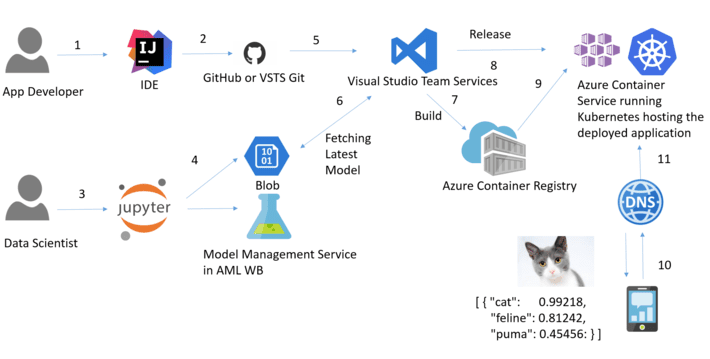
You can plan for and build a continous integration pipeline for an AI application, for starters. The pipeline kicks off for each new commit that the data scientist makes, triggering the test suite run(s). If the test passes, it takes the latest build, packages it into a Docker container along with all necessary packages and package dependencies / versions to run to model successfully.
The container is then deployed using a container service hosted in the cloud, like @Azure Container Service (#ACS) and the subsequent images are securely stored in the associated container registry (#ACR). This is good for small scale or development purposes but when you need to operationalize or deploy to production grade, you would then look towards a service like Kubernetes for managing / orchestrating the container clusters ( other service alternatives are #Docker-Swarm / #Mesos).
The application securely pulls the latest pretrained #ML model from a cloud-based blob storage account and packages that as part of the application. The deployed application has the app code and ML model packaged as single container and the assets and outputs become part of the checked in code that gets pushed back into your enterprise code repository for version control et al.
This decouples the app developers and data scientists, to make sure that their production app is always running the latest code with latest ML model. Here is a reference architecture diagram to elucidate the concept ( cloud providers and subsequent service offerings herewithin represent an example but are not required):
){kind=link}