
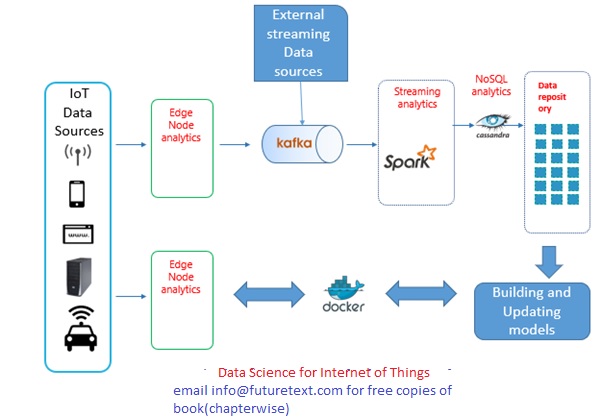
This big picture view lays the foundation of our book Data Science for the Internet of Things. (Co-authored by Ajit Jaokar, Jean Jacques Bernard and Sukanya Mandal)
We address the question: at what points can we add analytics to the data after it leaves the sensor and what are the implications of doing so at various stages.
In this diagram, we present the big picture through two process flows:
- Technology flow: Edge to Stream to Store
- Deployment flow: Model build, deploy and refresh in production including at the edge
Data Science for IoT implementation differs from traditional Data Science in four key aspects
- Edge Computing
- Feature Engineering for IoT
- Complex event processing
- Embedded AI
The last three are not shown in the diagram to make it more readable.
Notes:
- From an IoT analytics perspective, Mobile devices could also function as Edge devices.
- AI when deployed at the edge works primarily for inference(currently)
- Most Data Science for IoT problems are time series problems. In practise, this means the use of LSTMs in many cases. We could also work with images, sound etc (using convolutional neural networks etc)
- The diagram does not show batch mode of processing which exists in many applications
In terms of deployment models, we consider three options:
- Digital signals: for example, in insurance where IoT provides a signal to enhance existing business processes
- Digital twin: Mainly in industrial iot
- Digital wand: A ‘pervasive’ deployment of AI / ubiquitous computing. Currently, seen in some smart city applications in China
We welcome comments
To sign up for the book chapters and ongoing emails https://my.sendinblue.com/users/subscribe/js_id/31hme/id/1%20future…
To learn about my course on AI please see #AI/ #Deep Learning applications course
{kind=link}