
This document comes from Github.
Introduction
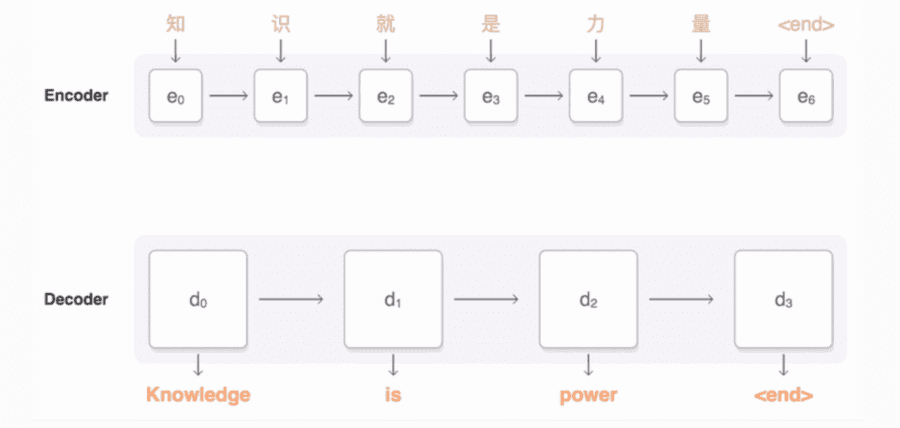
tf-seq2seq is a general-purpose encoder-decoder framework for Tensorflow that can be used for Machine Translation, Text Summarization, Conversational Modeling, Image Captioning, and more.
Design Goals
We built tf-seq2seq with the following goals in mind:
- General Purpose: We initially built this framework for Machine Translation, but have since used it for a variety of other tasks, including Summarization, Conversational Modeling, and Image Captioning. As long as your problem can be phrased as encoding input data in one format and decoding it into another format, you should be able to use or extend this framework.
- Usability: You can train a model with a single command. Several types of input data are supported, including standard raw text.
- Reproducibility: Training pipelines and models are configured using YAML files. This allows other to run your exact same model configurations.
- Extensibility: Code is structured in a modular way and that easy to build upon. For example, adding a new type of attention mechanism or encoder architecture requires only minimal code changes.
- Documentation: All code is documented using standard Python docstrings, and we have written guides to help you get started with common tasks.
- Good Performance: For the sake of code simplicity, we did not try to squeeze out every last bit of performance, but the implementation is fast enough to cover almost all production and research use cases. tf-seq2seq also supports distributed training to trade off computational power and training time.
What you will find in this paper:
- Getting Started
- Concepts
- Tutorial: Neural Machine Translation
- Tutorial: Summarization
- Tutorial: Image Captioning
- Data
- Training
- Inference
- Tools
- Results
- Getting Help
- Contributing
- License
- Reference: Models
- Reference: Encoders
- Reference: Decoders
To check out all this information, click here.
DSC Resources
- Services: Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Contributors: Post a Blog | Ask a Question
- Follow us: @DataScienceCtrl | @AnalyticBridge
Popular Articles
- Difference between Machine Learning, Data Science, AI, Deep Learnin…
- What is Data Science? 24 Fundamental Articles Answering This Question
- Hitchhiker’s Guide to Data Science, Machine Learning, R, Python
- Advanced Machine Learning with Basic Excel
Follow us on Twitter: @DataScienceCtrl | @AnalyticBridge
{kind=link}