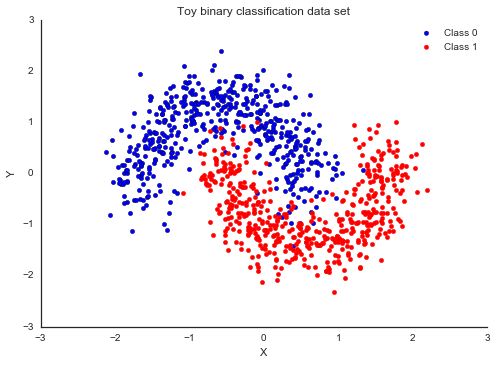
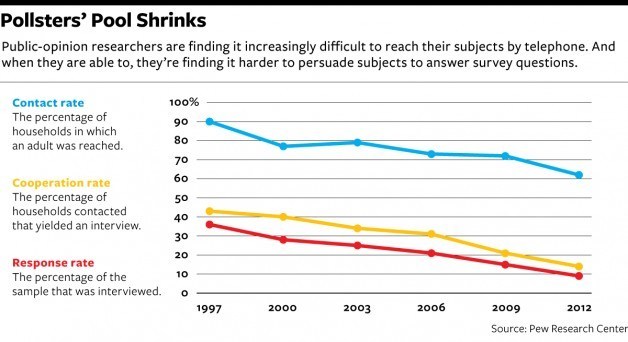
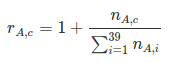Deep Learning, Neural Networks and AI The course is a new one by Andrew Ng, Co-founder, Coursera; Adjunct Professor, Stanford University; formerly head of Baidu AI Group...
This article was written by Koustubh. Unless you have been living under the rock, you must have heard of the revolution that deep learning and convolutional neural netw...
Great Saturday reading: our selection of articles and resources featured today: Learn Python in 3 days : Step by Step Guide Creating Your First Machine Learning Classif...
This article was written by Hardik Gohil, Sr Content Writer. Artificial Intelligence has effectively convinced its necessity to the entire world by performing excellen...
This article comes from GitHub. A curated list of resources dedicated to bayesian deep learning. 2013: Deep gaussian processes|Andreas C. Damianou,Neil D. Lawrence|2013 &...
Here is a fantastic book review by Ian White . Ian is an entrepreneurial product leader with 20 years experience spanning product management and business strategy at th...
Summary: The argument in the popular press about robots taking our jobs fails in the most fundamental way to differentiate between robots and AI. Here we try to ident...
This article was written by Tristan Handy. Tristan is the founder and president of Fishtown Analytics: helping startups implement advanced analytics. I’m very confident...
Apache Spark is generally known as a fast, general and open-source engine for big data processing, with built-in modules for streaming, SQL, machine learning and graph p...
In this blog post, I will discuss feature engineering using the Tidyverse collection of libraries. Feature engineering is crucial for a variety of reasons, and it requi...