The Zipf distribution is used to model situations in which a few observations have a very high value (or impact) and account for a large part of the total, while a very l...
In this blog I will go a bit more in detail about the K-means method and explain how we can calculate the distance between centroid and data points to form a cluster. Con...
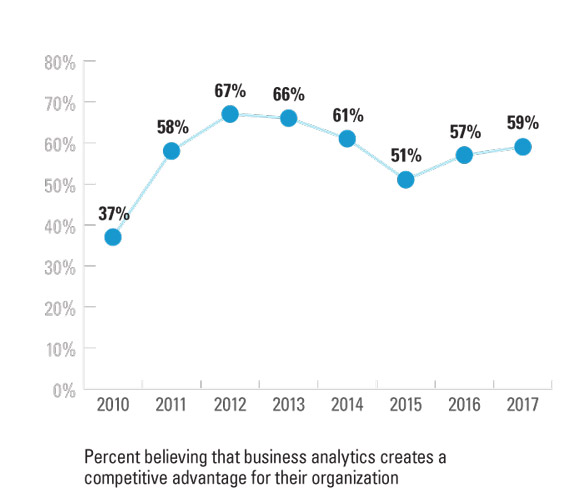
Here is a guest blog from MIT SMR by Sam Ransbotham. Organizations that turn data into insights are gaining competitive advantage through improved connections with consu...
From advertising and promotion to selling and feedback, marketing chatbots are reducing the cost for companies, saving time, increasing efficiency and creating larger awa...
Premise: How will the traditional car industry create and extract customer value in the future when the source of that value is no longer the vehicle itself? An increasin...
In my previous article, I wrote about the impact of Robotic Process Automation which drives Enterprise AI. In that article, I said: The first group of workers to feel the...
Hello All, Gives me immense pleasure to announce the release of our book “Practical Enterprise Data Lake Insights” with Apress. The book takes an end-to-end solution...
To be actionable, Big Data and Data Science must get down to the level of the individual – whether the individual is a customer, physician, patient, teacher, studen...
In an attempt to put the patient first in healthcare, Congress and President Obama in 2015 approved a bipartisan bill for United States healthcare reform. The bill is kn...
The purpose of a variance-covariance matrix is to illustrate the variance of a particular variable (diagonals) while covariance illustrates the covariances between the ex...