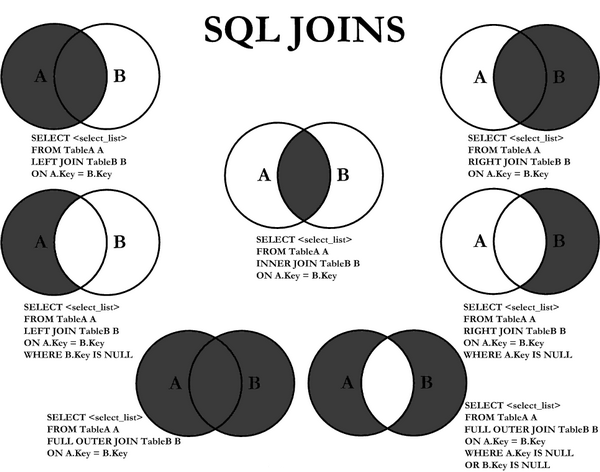
Autonomous cars are racing down the highway at speeds exceeding 100 MPH when suddenly a car a half-mile ahead blows out a tire sending dangerous debris across 3 lanes of ...
My nephew’s a very impressive young man. Five years ago, he received a PhD in Biochemistry/Molecular Biology from a prestigious university, earning numerous teachin...
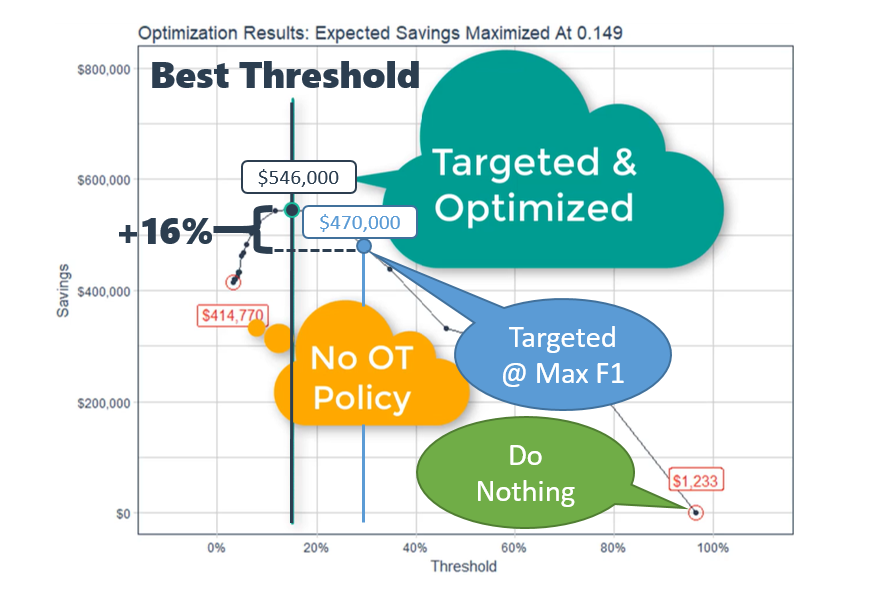
One of the most difficult and most critical parts of implementing data science in business is quantifying the return-on-investment or ROI. In this article, we highligh...
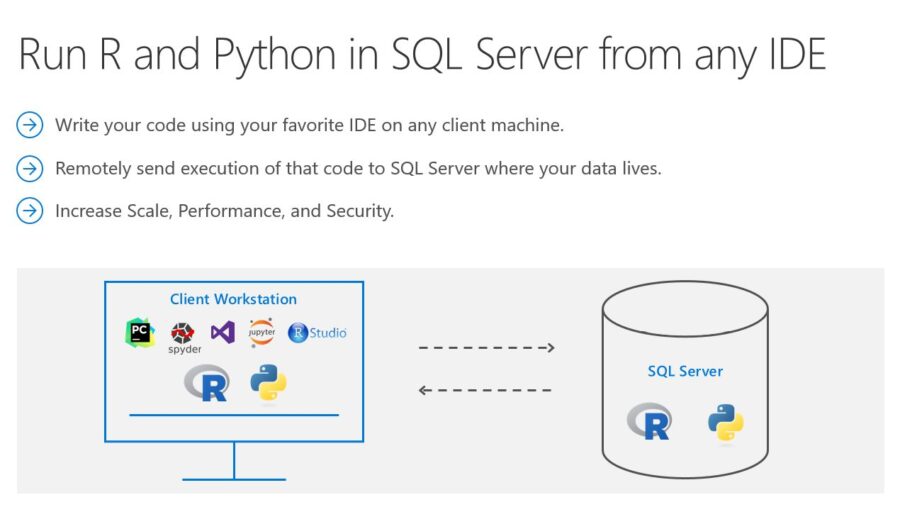
Introduction Did you know that you can execute R and Python code remotely in SQL Server from Jupyter Notebooks or any IDE? Machine Learning Services in SQL Server elimina...
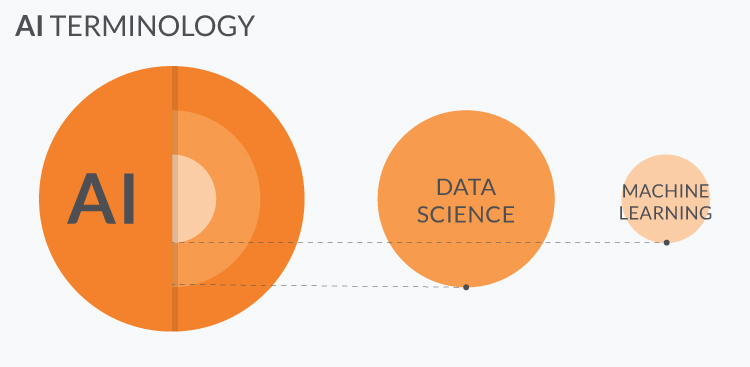
In 2018, Fast Company declared ‘Data Scientist’ as the best job in America for the third year in a row! How many of you have noticed people suddenly calling them...
Machine learning in finance may work magic, even though there is no magic behind it (well, maybe just a little bit). Still, the success of machine learning project depend...
The rise in Machine Learning, Deep Learning and Artificial Intelligence technologies seems to breaking all barriers. All these technologies have the potential to spur inn...
What is the mixed reality? We have heard about virtual reality and augmented reality. As the name suggests, the mixed reality is something that has features of both augme...
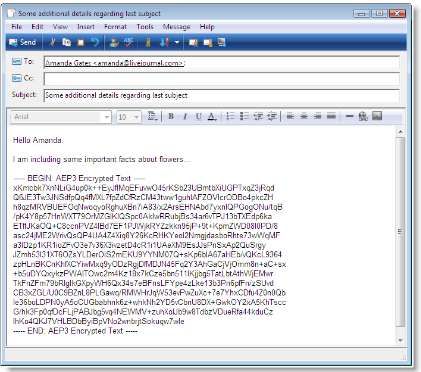
Updated on August 12. See new section entitled “Future research on the topic.” Here I propose an alternative to traditional cryptography. Traditional cryptogr...
Summary: Our recent series of articles on AI strategies shows the options available for the strategic direction of your AI-first company. Here are some thoughts on mo...