
Best practices that break data platforms
Every data engineering team operates on a set of accepted principles, a playbook of “best practices” intentionally designed to ensure scalability, governance, and performance.

Every data engineering team operates on a set of accepted principles, a playbook of “best practices” intentionally designed to ensure scalability, governance, and performance.


Across the tech sector, the term ‘AI agent’ has become Silicon Valley’s latest Rorschach test—revealing more about the speaker’s worldview than any shared technical definition.… Read More »The rise of accountable AI agents: How knowledge graphs solve the autonomy problem


Advancements in statistical AI applications for understanding and generating text have been nothing short of staggering over the past few years. Many believe it’s only… Read More »The key to conversational speech recognition

Writing software for research isn’t like making a shopping app. It often controls lab instruments, runs detailed simulations, or works through huge sets of experimental… Read More »Code audits in R&D-driven applications


Master the art of freezing layers in AI models to optimize transfer learning, save computational resources, and achieve faster training with better results.
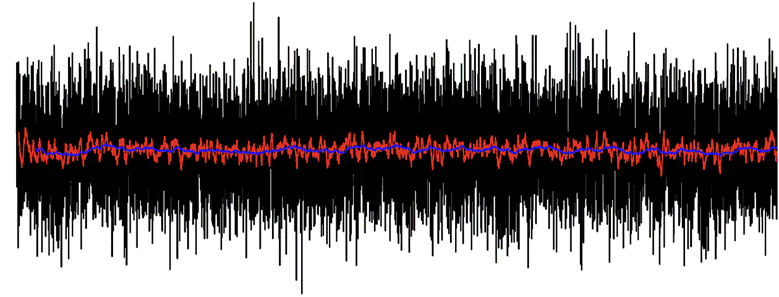

Welcome to the series of articles on the secrets of time series modeling. Today’s edition features the nested cross-validation — a lesser-known technique that mitigates some of… Read More »Secrets of time series modeling: Nested cross-validation
Intuition alone is no longer enough for effective leadership in the modern business world. Business leaders increasingly rely on data to guide strategic decisions. Research… Read More »How business leaders are using AI to make data-driven decisions


Discover how purpose-built AI factories are transforming on-premises GPU data centers for high-performance AI workloads, offering cost efficiency, security, and scalability for enterprises.

A radiologist looks at hundreds of CT images to find a tiny shadow that could be cancer. At these moments, every pixel matters. AI can… Read More »How diagnosis image annotation turns scans into insights
