
Guest blog post by Tony Abraham, Nikhita Koul, Joe Morales. A data science exploration of rap lyrics and what it takes to make it onto the billboard charts. Originally posted here. The original version offers full-size, complete interactive Tableau graphics, as well as the hit prediction algorithm box, available as an API.
Introduction
As a capstone project for the MIDS program at the University of California, Berkeley, our team applied machine learning techniques and data science principles to a database of rap lyrics from 1980 to 2015. After an active exploration of the data, we chose to focus our efforts on ‘hit prediction’, particularly on what it takes to make it onto the weekly Billboard Top 100 charts. Through a combination of lyric features and the support vector machine (SVM) model, we were able to obtain over 70% accuracy in the prediction of past songs on the Billboard Top 100 chart.
The sections on this page will give you insight into how we built the prediction system, the features used to power our model, and an opportunity to use the system to classify contemporary rap lyrics that you provide.
Rap Music Visualized
Our path to predicting successful songs began with feature creation for our supervised learning model. We initially used bag of words models to predict success, but we found very little improvement over the baseline. These attempts evolved into features created by the content of the lyrics themselves: topics, places, brands, and vulgarity. While some of these features provided little improvment for our hit protection, all of the features provided a fascinating look at the content of rap music.
I’ll take some hip hop please.
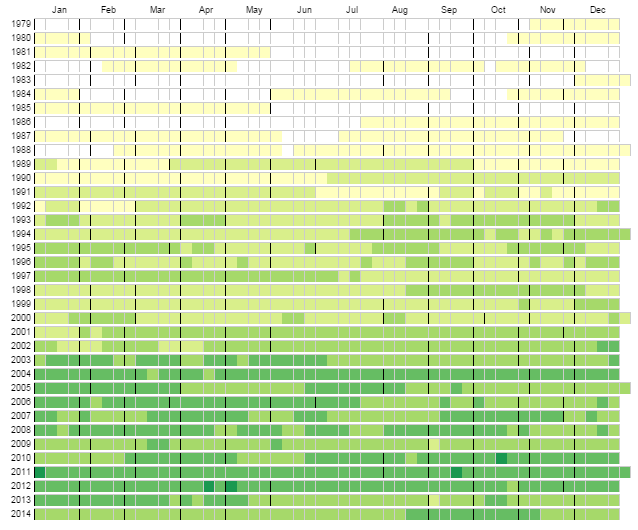
The time of a song’s release proved to be a valuable feature in our model. Rap music has clearly evolved over the past 30 years, and so a hit in the 2000s has different characterstics than a hit in the 1980s. The visualization below represents the emergence of rap music onto the weekly Billboard Top 100 charts, with the darker green squares representing a higher percentage of rap music in the top 100.
Rap, on a map.
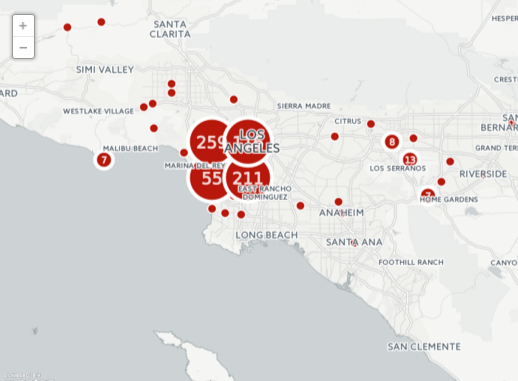
Using the Alchemy API, we were able to extract places that were referenced in each song in our dataset. The interactive map below illustrates the concentrations of geographic references in rap songs for the past 30 years.
Where them guns at?
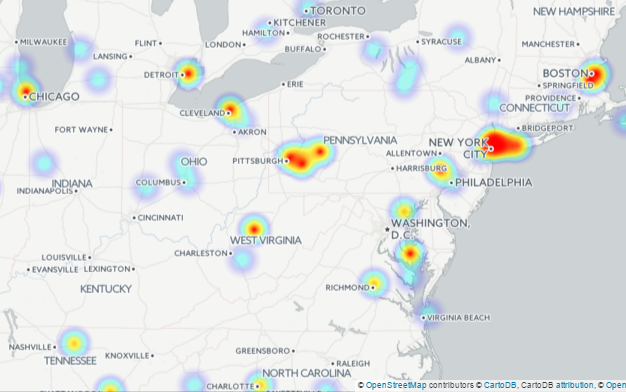
The Alchemy API was flexible enough to allow us to create the following heatmap which visualizes songs that reference geographic locations as well as crimes.Interestingly, many places that experience high crime rates in real life, are often mentioned in songs describing criminal activity.
Will the real ‘Theme’ Shady please stand up?
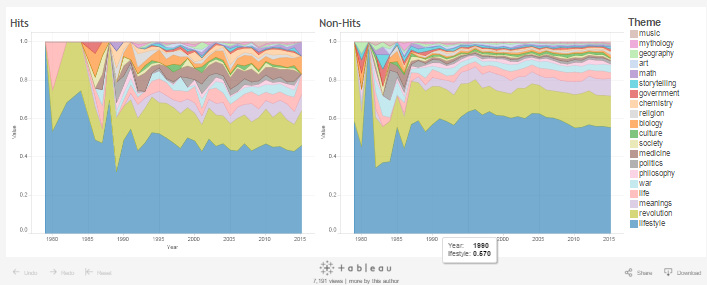
We used Mallet to determine the themes present in each song in our dataset. We first primed Mallet on a wikipedia dataset, and then applied it to our songs to better ensure clean output. In the visualizations below, you can view the top 20 most popular themes from 1980 to today.
There are some things money can’t buy. For everything else…
There are a lot of references to brand names in rap music. The word cloud below visualizes the frequency of the different brands that were namechecked in the songs in our dataset.

What the flip are you looking at?
Vulgarity in rap music is ubiquitous, and surprisingly, it’s one of our most important features in our model. The use of the different swear words are visualized over time below. We’ve censored the chart, but it doesn’t take too much of a leap to figure out what words we’re referencing.
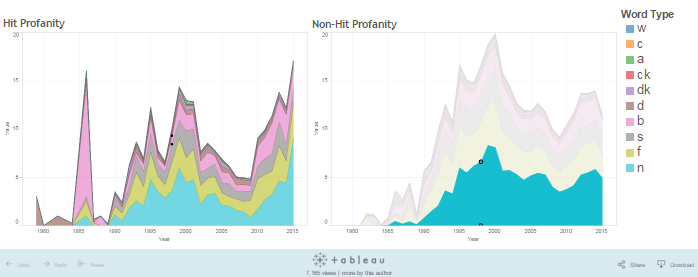
How did we do?
The goal of our system was to predict whether or not a rap song would appear on the Billboard Top 100 Charts. We treated this as a supervised machine learning problem, and we narrowed down our dataset of songs 24,175 entries. This dataset contained 1,491 rap songs that had successfully made it onto the top 100 charts, and the remaining songs from those artists that did not make it onto the charts. With such a large offset between the number of successful and unsuccessful songs, we used randomized sampling to better balance the data.
We used combinations of the features we described above and various machine learning algorithms to better hone our predictive score. In the end, we found that the most accurate combination was from training an support vector machine (SVM) on the features of song topic, vulgarity, and release date. After training the SVM, we ran our classifier on a test dataset of 600 songs (300 successful and 300 unsuccessful) that we had kept separate from our training data. On the test data, we achieved over 71% accuracy for classifing the success of songs. The outcome of this run is visible in the chart below.
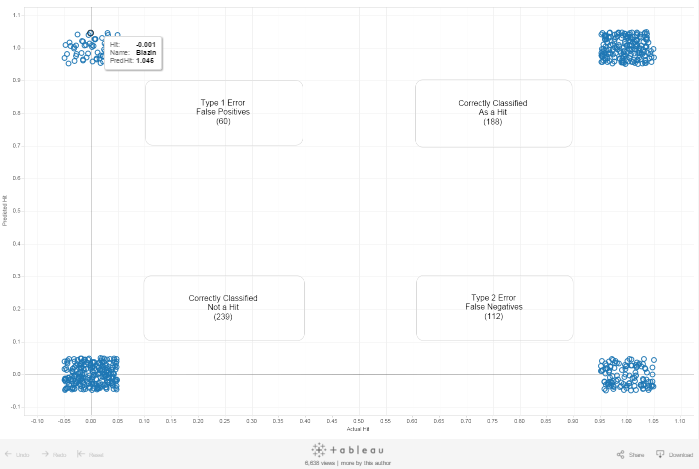
Hit Prediction
Now is your chance to try out our hit prediction algorithm. Enter the lyrics and the release date from a rap song below, and we’ll explain what our system determines about that song.
Notes & Credits
Project Notes
This project was created by Tony Abraham (gmail at tonyabra), Nikhita Koul (gmail at nikhita dot koul), and Joe Morales (yahoo at jmorales4) as a project for the W210 – Capstone class, which is a part of the Master of Information and Data Science program atUC Berkeley.
Credits
The data was sourced from rapgenius. The background photo has been captured by Steven Pisano. The website was designed using the Transit template from templated.co. The visualizations were designed using CartoDB, d3, and Tableau. AlchemyAPI was used as a part of entity extraction. Mallet was used for topic modeling.
{kind=link}