
Many of the following statistical tests are rarely discussed in textbooks or in college classes, much less in data camps. Yet they help answer a lot of different and interesting questions. I used most of them without even computing the underlying distribution under the null hypothesis, but instead, using simulations to check whether my assumptions were plausible or not. In short, my approach to statistical testing is model-free, data-driven. Some are easy to implement even in Excel. Some of them are illustrated here, with examples that do not require statistical knowledge for understanding or implementation.
This material should appeal to managers, executives, industrial engineers, software engineers, operations research professionals, economists, and to anyone dealing with data, such as biometricians, analytical chemists, astronomers, epidemiologists, journalists, or physicists. Statisticians with a different perspective are invited to discuss my methodology and the tests described here, in the comment section at the bottom of this article. In my case, I used these tests mostly in the context of experimental mathematics, which is a branch of data science that few people talk about. In that context, the theoretical answer to a statistical test is sometimes known, making it a great benchmarking tool to assess the power of these tests, and determine the minimum sample size to make them valid.
I provide here a general overview, as well as my simple approach to statistical testing, accessible to professionals with little or no formal statistical training. Detailed applications of these tests are found in my recent book and in this article. Precise references to these documents are provided as needed, in this article.
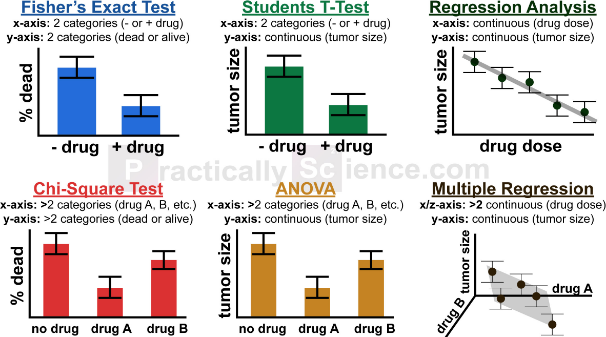
Examples of traditional tests (source: PracticallyScience.com)
1. General Methodology
Despite my strong background in statistical science, over the years, I moved away from relying too much on traditional statistical tests and statistical inference. I am not the only one: these tests have been abused and misused, see for instance this article on p-hacking. Instead, I favored a methodology of my own, mostly empirical, based on simulations, data- rather than model-driven. It is essentially a non-parametric approach. It has the advantage of being far easier to use, implement, understand, and interpret, especially to the non-initiated. It was initially designed to be integrated in black-box, automated decision systems. Here I share some of these tests, and many can be implemented easily in Excel. Also keep in mind that the methodology presented here works with data sets that have at least a few thousand observations. The bigger the better.
The concept
I illustrate the concept on a simple problem, but it generalizes easily to any test. Here you want to test whether a univariate data set consists of numerical values (observations) that follow a normal distribution, or not. In order to do so, in a nutshell, you can proceed as follows:
- Normalize your data, so that the mean is zero and variance is equal to one.
- Simulate 10 samples (of same size as your data set) from a normal distribution of mean zero and variance one. The easiest way to do this, in Excel, might be to simulate 25 uniform deviates with the function RAND, then average and normalize, for each normal deviate being created. There are more efficient ways to do it though, see here.
- Compute the percentile distribution for your normalized data, as well as for the 10 simulated samples that you created. Easy to do in Excel, see section 2.4.
- Look at how much variance there is between the percentile distributions computed on the 10 simulated data sets. This will give you an idea of what the natural or internal variance is.
- Compare the percentile distribution computed on your real data, with those from the simulated data. Does it look like the curve is similar to those produced with the simulated data? Or is there some kind of departure? Maybe it clearly grows more slowly initially, then catch up later, compared to the 10 curves resulting from simulation?
Ideally, you would want to have more than one real data set, to compare variations between real samples, with variations between simulated samples, and then cross-differences between real data and simulated samples. If your data set is large enough (say 3,000 observations) one way to achieve this is to split your data set into three subsets.
Now that you have an idea of the principles, we can dive in the details. The above test is one of those described in more detail in the next section, with Excel spreadsheets to illustrate the computations.
2. Off-the-beaten-path Statistical Tests
Below is our selection of unusual statistical tests, as well as some well known tests presented in an non-standard (yet simpler) way.
2.1. Testing for symmetry
This tests is used to check if the underlying distribution of your data has the same shape (mirrored) both on the left side and the right side of the median. It can be performed as follows.
One can compare R(x) = | 2 * Median – P.x – P.(1-x) | with that of a symmetric distribution, for various values of x between 0 and 0.5, to check if a distribution is symmetric around the median. The theoretical value of R(x) is zero regardless of x, if your empirical distribution is symmetric. Here P.x represents the x-th percentile. Other tests for symmetry can be found here. See illustration in this article.
2.2. Testing for unimodality and other peculiarities
To test if a distribution is unimodal, several tests have been devised: the bandwidth test, the dip test, the excess mass test, the MAP test, the mode existence test, the run test, the span test, and the saddle test. The dip test is available in R. Read more here. Some of these tests, in case of multimodality, can tell you how many modes (or clusters) are in your data sets.
Other potential tests could be used, for instance to check if your data
- has an an unbounded support domain (values can be arbitrarily large in absolute value given a large enough sample size),
- if its support domain has some gaps (no value can exist in some particular sub-interval),
- if its empirical density function (histogram) is bounded (an example of unbounded density is f(x) = 0.25 / SQRT(|x|) with x in [-1, 1])
- Or test for infinite mean or infinite variance
2.3. Testing whether or not there is some structure in your data
I investigated a metric that measures the presence or absence of a structure or pattern in a data set. The purpose is to measure the strength of the association between two variables, and generalizes the correlation coefficient in a few ways. In particular, it applies to non numeric data, for instance a list of pairs of keywords, with a number attached to each pair, measuring how close to each other the two keywords are. You would assume that if there is no pattern, these distance distributions (for successive values of the sample size) would have some kind of behavior uniquely characterizing the absence of structure, behavior that can be identified via simulations. Any deviation from this behavior would indicate the presence of a structure. See here for more details.
2.4. Testing for normality, with Excel
Traditional tests exist, for instance Chi-square or Kolmogorov-Smirnov. This also works for any distribution, not just the normal (Gaussian) one. And you can use it to compare too sets of data, or two-subsets corresponding to two different time periods, to check whether they have the same distribution or not, regardless of what that distribution is. Instead of comparing empirical PDF’s (probability distribution function) as in Kolmogorov-Smirnow, I use empirical percentiles (the inverse of the PDF), which are very easy to compute in Excel. See illustration (with Excel spreadsheet) in this article. I call it the percentile test. I typically use it after normalizing the data, so that the median value is zero.
Among other things, I have used the percentile test to solve stochastic integral equations, that is, to find the exact equilibrium distribution attached to some chaotic dynamical systems. See my book, page 18 (download the spreadsheet listed below the chart on page 18) and page 74.
Note: A curious normality test consists in splitting your data Z in two subsets X and Y of same size, and testing whether (X + Y) / SQRT(2) has the same distribution as Z. Explanations are provided here, and it works as long as the underlying theoretical variance is not infinite.
2.5. Tests for time series
Many assumptions could be tested, when dealing with time series observations. Sometimes, it is useful to first normalize the data by removing the trend, periodicity, outliers, and some noise. You could test if the data exhibits change points, that is, a sudden and long-term increase or decrease in observed values, usually the result of some event that took place at some point in time; see here for illustration. Or whether the change is more subtle, for instance there is no discontinuity, but the slope (trend) suddenly changes at one point. Or test whether some auto-correlations (lag-1, lag-2, and so on) are present. You can even compare the whole correlation structures of two paired time series, to check if they come from the same statistical model. Or you can perform model fitting: for instance, you suspect that your data follows an ARIMA time series model; then
- you estimate the coefficients of that tentative model,
- then simulate values from the exact same model with same coefficients (it is much better to simulate several instances of that model to get an idea of what natural variations between same-model time series should be),
- then test – by comparing the correlation structure in the observed and simulated data – whether the model is a good fit,
- then try again with a different model to see if you can get a better fit.
In my case, I used some home-made tests to check whether a time series exhibits some sort of periodicity, and, as a result, I found that pseudo-random generators available in some programming languages, have a very short period, making them unfit for industrial applications. See my book, page 33.
2.6 Gap test, with Excel
Along with the percentile test described in section 2.4, this is one of my favorite tests to detect patterns. It is best illustrated in this article. In essence, the gap test consists of measuring the largest gap with no observation, in a set of ordered values (observations). That is, the largest interval with no data point. It generalizes to higher dimensions, where the gap can be a square or circle with no data point in it. The exact distribution of the gap area or length, assuming data points are uniformly distributed, is known. If the data points take on integer values only, the distribution is a geometric one, readily available in Excel. More on this in my book, page 84. The test can also be used for outlier detection: a point too far away from its nearest neighbor could be an outlier.
2.7. Sparsity test
Is your data voluminous but sparse, a bit like the night sky where trillions of stars occupy a tiny portion of the sky? Or is it full of holes of moderate sizes, like Gruyere cheese? We tested this assumption in a setting that is similar to fractional factorial tables. You can check it out in my book, page 71.
Along the same topic, are apparent patterns real, or an illusion? For instance, in the night sky, many stars seem to be very close to each other despite the vast emptiness of the universe. Are there too many of them (called twin points) to just be a coincidence? An answer to this question, based on a statistical test, is provided here. See also a related problem about Mars craters, here.
2.8. Elbow test
The elbow test is traditionally used as a rule-of-thumb to detect the number of clusters when implementing a clustering algorithm, see here for illustration. I also used it to determine how many digits are accurately computed, when using high precision libraries available in some programming language. The answer was far below what is advertised in the manuals, especially when working with a mathematically ill-conditioned problem that requires an unstable iterative algorithm for computations, as in some chaotic dynamical systems. See my book, page 48, and here.
2.9. Testing for accelerating growth
This could be used, for instance to check if glaciers are melting down at an accelerating pace. It is based on the distribution of records, and in particular, the arrival times of these records. Again simulations can be performed for this test. It is illustrated in my book (chapter 14), focusing on the distribution of arrival times of extreme events: the exact distribution, in the absence of growth, does not depend on the distribution of the observations (neither observed nor extreme values) making it a pretty generic non parametric test.
2.10. Run test
I used the run test in the context of stock trading, to assess how likely a run (say, 6 successive days with stock prices going up) is followed by a reversal, trying to find patterns to increase gains. The same can apply to sport bets. In general, run tests can be used in situations in which the underlying process behaves like a Markov chain. It helps you assess the probability of getting a + or – after any sequence of ups and downs, such as ++-+—+-+++. This test has also been used (among many other tests) to check if the distribution of the digits of some number (say Pi in base 2) appears to be uniform and without auto-correlations. Note that in the case of a random walk, for instance when throwing a dice, even after an extremely unprobable run of 1,000 heads, the chance of obtaining an head next time is still 50%. The same seems to be true with the digits of Pi in base 2: after any sequence of 1,000 consecutive digits all equal to 1, the chance that the next digit is 1, is also 50%. This is indeed true regardless of the combination of 0’s and 1’s in the previous 1,000 digits. So the run test can be used to measure departures from randomness.
For a list of standard tests, visit this page.
To not miss this type of content in the future, subscribe to our newsletter. For related articles from the same author, click here or visit www.VincentGranville.com. Follow me on on LinkedIn, or visit my old web page here.
DSC Resources
{kind=link}