
In April, Gil Press posted a list of top 10 hot big data technologies in Forbes Magazine. The technologies being featured as hot were:
- Predictive analytics
- NoSQL databases
- Search and knowledge discovery
- Stream analytics
- In-memory data fabric
- Distributed file stores
- Data virtualization
- Data integration
- Data preparation (automation)
- Data quality
The article came with a cool chart (produced by Forrester Research, and similar to other charts produced by Gartner) :
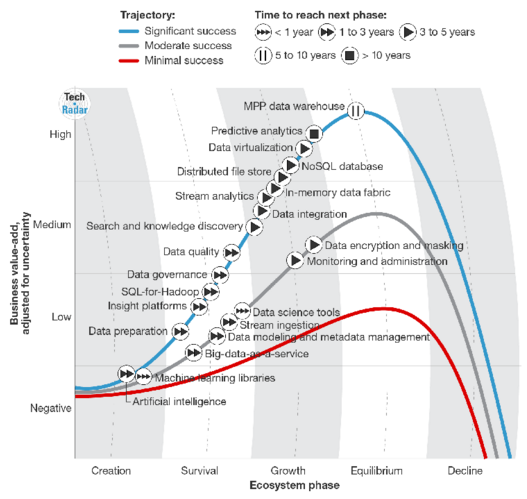
What do you think are the hottest technologies now? Do you agree with Gil’s list?
Personnally, I think that the hottest technologies (related to data science) are:
- Adapting modern predictive algorithms to a distributed architecture
- AI (pattern recognition)
- Deep learning (the interection of AI and machine learning)
- Data science automation
- Leveraging data from sensors (IoT)
- Turning unstructured data into structured data, and data standardization
- Blending multiple predictive models together
- Intensive data and model simulation (Monte-Carlo or Bayesian methods), to study complex systems such as weather, using HPC (high performance computing)
Related articles: click here to read more than 10 articles (featured in the picture below) about predictions that will impact our profession. It would be interesting to see how many still make sense today. For older predictions (2015) and see which ones turned out to be correct, click here.
DSC Resources
- Career: Training | Books | Cheat Sheet | Apprenticeship | Certification | Salary Surveys | Jobs
- Knowledge: Research | Competitions | Webinars | Our Book | Members Only | Search DSC
- Buzz: Business News | Announcements | Events | RSS Feeds
- Misc: Top Links | Code Snippets | External Resources | Best Blogs | Subscribe | For Bloggers
Additional Reading
- What statisticians think about data scientists
- Data Science Compared to 16 Analytic Disciplines
- 10 types of data scientists
- 91 job interview questions for data scientists
- 50 Questions to Test True Data Science Knowledge
- 24 Uses of Statistical Modeling
- 21 data science systems used by Amazon to operate its business
- Top 20 Big Data Experts to Follow (Includes Scoring Algorithm)
- 5 Data Science Leaders Share their Predictions for 2016 and Beyond
- 50 Articles about Hadoop and Related Topics
- 10 Modern Statistical Concepts Discovered by Data Scientists
- Top data science keywords on DSC
- 4 easy steps to becoming a data scientist
- 22 tips for better data science
- How to detect spurious correlations, and how to find the real ones
- 17 short tutorials all data scientists should read (and practice)
- High versus low-level data science
Follow us on Twitter: @DataScienceCtrl | @AnalyticBridge
{kind=link}