
Summary: As the Automated Machine Learning (AML) movement got underway a few years back there was an early branch between proprietary platforms and open source platforms. In this article we’ll update you on leading open source AML tools. Since they continue to require fluency in Python or R we label them “professional”.
 As the Automated Machine Learning (AML) movement got underway a few years back there was an early branch between proprietary platforms and open source platforms. Today, the primary difference between these is that the proprietary entries are largely code-free so that citizen data scientists / business analysts can use them in addition to data scientists. The open source versions are still reliant on your ability to code, or at least to copy code. And oh yes, open source is free.
As the Automated Machine Learning (AML) movement got underway a few years back there was an early branch between proprietary platforms and open source platforms. Today, the primary difference between these is that the proprietary entries are largely code-free so that citizen data scientists / business analysts can use them in addition to data scientists. The open source versions are still reliant on your ability to code, or at least to copy code. And oh yes, open source is free.
There is a kind of philosophical disharmony with AML that relies on code. AML after all was intended to make things simple and uniform. All the same there remains a solid core of data scientists who continue to prefer to hand code in Python or R and these open source apps will appeal mostly to them. Hence the appellation “professional” since it’s pretty unlikely that any of your business analysts or other citizen data scientists are going to try to compete based on their competence with code.
So although the user interface is not as ‘slick’, if your organization is an R or Python shop then these packages offer the consistency, speed, and economy while eliminating much of repetitive work entailed in model building. There are even a few of these packages that bridge over into Automated Deep Learning (ADL) if your needs are that complex.
A fully featured proprietary app can generally provide all of the following features.
- Data Blending
- Data Prep and Cleansing
- Feature Engineering
- Feature Selection and Modeling
- Model Deployment
- Model Management and Refresh
Advanced features might also include programmatic automation of the entire process for model refresh and update. They may also accommodate unstructured and semi-structured data. To see more about who’s leading among the proprietary platforms try our previous article here.
It’s unlikely you’ll find all these capabilities in an open source app but possible that you can string several together to come close. Most focus on model selection and hyperparameter tuning and not (yet) the earlier and later tasks in the process. Here are a few of the leaders as mentioned by positive reviews among ‘professional’ users.
Most Complete Solutions
MLBox (Machine Learning Box)
MLBox is a powerful Python library that performs data cleaning, model selection, and hyperparameter tuning. Some users have done quite well in Kaggle competition scoring in the top 5%. It’s reported to work best with Linux and somewhat less so with Mac and PC.
Auto-SKlearn
Auto-SKlearn is built around the well-known scikit-learn Python library and is a relatively complete solution for supervised machine learning. It has placed well in a variety of recent AML contests and is a replacement for scikit-learn estimator.
It will handle missing values, categoricals, sparse data, and rescaling with 14 preprocessing methods. It passes off from the preprocessing module to the classifier / regressor including 15 ML algorithms and Bayesian hyperparameter tuning for a total of 110 hyperparameters. It will also automatically construct ensembles.
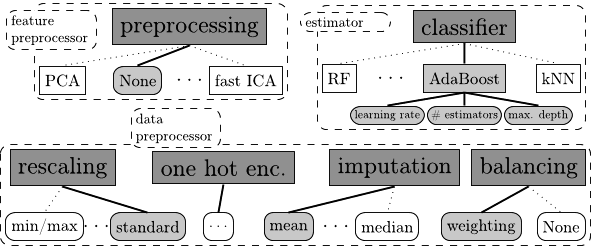
Interestingly Auto-sklearn has been expanded to handle deep neural nets with an add-in package Auto-Net adding this as a 16th ML algorithm.
TPOT (Tree-based Pipeline Optimization Tool)
TPOT is an open source extension of the scikit-learn Python library. It’s billed as “your Data Science Assistant” to automate the most tedious portions of model development. As its name specifies this is a tree-based classifier only with automation starting after cleaning but through the delivery of production ready python code.
Perhaps TPOT’s most interesting feature is that hyperparameter optimization is based on genetic programming. For the expert user all the assumptions are fully exposed so that you can continue to work the hyperparameters to test the optimization. In preprocessing TPOT can’t yet handle categoricals which must be preprocessed into integer strings.
The Component Supermarket
If you want to extend the capability of these packages or try to piece together your own open-source platform, there are a variety to pick from.
In Feature Selection and Engineering you might try:
- Boruta.py
- Categorical-Encoding
- Featuretools
- FeatureHub
For Hyperparameter Optimization you might try:
- ENAS
- FAR-HO
- GPFlowOpt
- HORD
- Hyperopt
- Ray.tune
- Skopt
Open Source ADL (Automated Deep Learning)
Yes, even deep learning now has a few open source packages to make your exploration even easier.
Auto-Keras
Auto-Keras provides functions to automatically search for architecture and hyperparameters of deep learning models. Keras is designed to simplify access to deep learning models by reducing code and will run on top of TensorFlow, CNTK, or Theano.
Uber Ludwig
Ludwig is a TensorFlow based tool designed to let non-experts create DL models providing only two files, a CSV with the training data, and a YAML file defining inputs and outputs. In theory no code is required.
Ludwig automatically runs a series of DL models which are compared in order to rapidly achieve a suitable final architecture, usually a task that is both time consuming and requires a highly skilled data scientist.
According to the Uber development team, Ludwig is equally valuable for experienced users who have access to all the under-the-hood controls and provides visualizations to provide easy understanding of model performance and prediction.
For both these ADL packages, feature engineering and selection remains a manual process.
Additional articles on Automated Machine Learning, Automated Deep Learning, and Other No-Code Solutions
Thinking about Moving Up to Automated Machine Learning (AML) (July 2019)
Automated Machine Learning (AML) Comes of Age – Almost (July 2019)
Practicing ‘No Code’ Data Science (October 2018)
What’s New in Data Prep (September 2018)
Democratizing Deep Learning – The Stanford Dawn Project (September 2018)
Transfer Learning –Deep Learning for Everyone (April 2018)
Automated Deep Learning – So Simple Anyone Can Do It (April 2018)
Next Generation Automated Machine Learning (AML) (April 2018)
More on Fully Automated Machine Learning (August 2017)
Automated Machine Learning for Professionals (July 2017)
Data Scientists Automated and Unemployed by 2025 – Update! (July 2017)
Data Scientists Automated and Unemployed by 2025! (April 2016)
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2 million times.
He can be reached at:
{kind=link}