
Summary: The drive toward transparency and explainability in our modeling seems unstoppable. Up to now that meant sacrificing accuracy for interpretability. However, the ensemble method known as RuleFit may be the answer with both explainability and accuracy meeting or exceeding Random Forest.
If you’re like me and not doing modeling in a highly regulated industry like mortgage finance or insurance then when you produce a model, you are concerned about only one thing, building the most accurate model that generalizes well.
On the other hand if you’re in one of those highly regulated industries then you are constrained by what has come be called ‘transparency’ or more accurately ‘explainability’. That’s the requirement to use algorithms that yield clear explanations about why Joe customer got such-and-such a rate or price. The same applies to medical research studies. Essentially this has limited those industries to GLM and simple decision trees.
Regulated Transparency and Coming Limits on Your Algorithms
 In the tradeoff between accuracy and regulated explainability we’d all vote for accuracy. Imagine having to tell a regulator, “well my model will explain exactly why we offered that rate to Sally, but oh, did I mention it was wrong 30% of the time!” Or your boss, “oh we could build models to make millions of dollars more but we’re not allowed”. There didn’t seem to be any middle ground.
In the tradeoff between accuracy and regulated explainability we’d all vote for accuracy. Imagine having to tell a regulator, “well my model will explain exactly why we offered that rate to Sally, but oh, did I mention it was wrong 30% of the time!” Or your boss, “oh we could build models to make millions of dollars more but we’re not allowed”. There didn’t seem to be any middle ground.
As recently as last fall, the previous administration had floated a serious effort to put explainability ahead of accuracy in all uses of predictive analytics that impacted individuals. And now the EU has passed the General Data Protection Regulation (GDPR) that goes into effect in May 2018. While GDPR looks like it’s about data privacy it actually contains similar explainability requirements that will now apply to all uses of predictive analytics that impact individual EU citizens.
In truth this pressure toward explainability and transparency has been building for a while, even more so now that the public is increasingly aware of how AI is and will impact their lives. And we all know that deep neural nets put new meaning in ‘black’ as in ‘black box’.
With this on my mind, I had the pleasure of hosting a webinar with Greg Michaelson, Director of DataRobot Labs last week and in his presentation he shared a chart that really caught my attention.
Accuracy, Ensembles, and Non-Interpretable Results
DataRobot is a one-click-to-model platform that seeks to fully automate the creation of predictive models by running a dozen or so algorithms on a data set simultaneously all the while performing some neat optimization tricks with feature selection, feature engineering, and hyper parameter tuning. Greg claims they’ve run over 160 Million models on the platform and one of their quality control steps is periodically to evaluate how the top 11 algorithms rank in terms of accuracy. Here’s their result:
- XG Boost 3.50
- RuleFit 3.68
- RandomForest 5.06
- GLM 5.11
- SVM 5.44
- ExtraTrees 6.39
- GBM 6.40
- KNN 8.87
- Vowpal Wabit 8.93
- Tensorflow 9.71
- Decision Tree 10.15
The numerical score is the average of each algorithm’s ranking out of 11 on all the tests run so far. So it’s probably no surprise that XG Boost is in first place but frankly I was unfamiliar with the number 2 winner, RuleFit that comes in ahead of even RandomForest.
I’m very familiar with the various ensemble routines including Bagging (Random Forests are in this group), Boosting, and Stacking. Having dozens or hundreds of decision trees (or multiple algorithms) in your ensemble is well known to increase accuracy. It does exactly the opposite for explainability. Not only would you have to peel apart how each model voted but there’s no way to understand the cross correlations among what could be dozens or hundreds of similar variables.
RuleFit – The Perfect Blend of Explainability and Accuracy
At Greg’s suggestion I looked more deeply into RuleFit which promises the perfect blend of explainability and accuracy.
 RuleFit is not new. It seems to have first appeared in a paper by Jerome Friedman and Bogdan Popescu of Stanford in October 2005 titled “Predictive Learning Via Rule Ensembles”. In their lengthy paper they go on to show that RuleFit is in fact more accurate than competing ensemble methods, consist with the chart Mr. Michaelson shared.
RuleFit is not new. It seems to have first appeared in a paper by Jerome Friedman and Bogdan Popescu of Stanford in October 2005 titled “Predictive Learning Via Rule Ensembles”. In their lengthy paper they go on to show that RuleFit is in fact more accurate than competing ensemble methods, consist with the chart Mr. Michaelson shared.
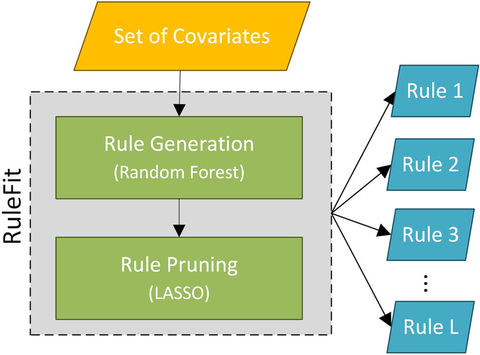
RuleFit, for classification or regression can be accessed with either R or Python. It’s best understood as Random Forests Meets LASSO (least absolute shrinkage and selection operator). It’s an integrated two-step method. First a rules generation phase (Random Forests) and then a rules pruning phase (LASSO).
It works well on high dimensional problems and because the modeling is based on decision trees, there’s no need to worry about standardizing or normalizing distributions, covariates, sparsity, or converting non-numeric to numeric. Decision trees are also the perfect rules generator, waiting only to be logically pruned.
Random Forest only works if we generate a large number of substantially dissimilar trees. This is accomplished by bootstrapping which randomly reweights subsets of the original dataset for training. This has an additional advantage of making it more likely that we will discover rules unique to specific sub-populations.
However, after rules generation we now have a very large population of potential rules from which we must select the most important. LASSO which is a sparse linear regression model is particularly suited for selecting a subset of relevant variables from the very large list of candidates. The formula as applied contains a user controlled variable that seeks to balance fitness with complexity. This allows you to evaluate the cutoff for most important variables and likewise the number of rules used for explanation.
Benefits and Limitations
- The most obvious benefit of RuleFit is that it meets or exceeds the accuracy of Random Forests but retains the explainability of decision trees. This should meet all the new regulatory requirements.
- Compared to GLM or decision trees which describe an average ‘best’ solution for the entire dataset, RuleFit has the potential to identify rules unique to important subgroups. It would still be wise to cluster and segment your dataset ahead of time to model on the most homogenous data.
- Particularly in the modeling of medical outcomes, where a single GLM or decision tree requires that each participant be characterized by a single rule, RuleFit allows for the possibility that a participant may have multiple patterns characterized by different variables or different interactions among variables.
- Although this rules based approach appears to encourage a kind of kitchen sink approach in which any independent variables might be thrown into the mix to let the algorithm sort it out, the literature and researchers suggest some caution in this area. Good domain knowledge and a reasonable hypothesis relating the independent variable to the outcome should be considered in selecting variables for inclusion.
- As always there is sampling risk, especially in light of the bootstrapping technique. There is a strong assumption that subgroups may exist but bootstrapping may not accurately or proportionately represent them in the training data. Consider feature engineering with clustering and segmentation.
So for me RuleFit is a surprise and an eye opener. As explainability and transparency become more important, so will RuleFit ensembles become an extremely critical tool in your tool box.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}