
Sometimes I write a blog just to formulate and organize a point of view, and I think it’s time that I pull together the bounty of excellent information about Machine Learning. This is a topic with which business leaders must become comfortable, especially tomorrow’s business leaders (tip for my next semester University of San Francisco business students!). Machine learning is a key capability that will help organizations drive optimization and monetization opportunities, and there have been some recent developments that will place basic machine learning capabilities into the hands of the lines of business.
By the way, there is an absolute wealth of freely-available material on machine learning, so I’ve included a sources section at the end of this blog for folks who want more details on machine learning.
So strap’em on! Time to dive into the world of machine learning!
Machine Learning Basics
Much of what comprises “Machine Learning” is really not all new. Many of the algorithms that fall into the Machine Learning category are analytic algorithms that have been around for decades such as clustering, association rules and decisions trees. However, the detailed, granularity of the data, the wide variety of data sources and massive increase in computing power has re-invigorated many of these mature algorithms. Today, machine learning is being used for a variety of uses including:
- Text translation, voice recognition and natural language processing (NLP). Machine Learning is the brains behind the continuously improving “conversations” with Apple Siri, Google Assistant, Microsoft Cortana and Amazon Alexa.
Facial, photo and image recognition. For example, the all-important question of “What is a Chihuahua puppy and what is a blueberry muffin?” can be addressed with a well-trained machine learning algorithm (see Figure 1).

Figure 1: Puppy versus blueberry muffin exercise
- Machine learning is also at the heart of Google’s ultra-successful, money printing search business
More applications of machine learning will be coming soon, including:
- Cyber security
- Insider trading
- Money laundering
- Personalized medicine
- Personalized marketing
- Fraud detection
- Autonomous vehicles
So exactly what is machine learning? Let’s start with a definition of machine learning:
Machine learning is a type of applied artificial intelligence (AI) that provides computers with the ability to gain knowledge without being explicitly programmed. Machine learning focuses on the development of computer programs that can change when exposed to new data.
Fundamentally, there are only two things that Machine Learning does:
- Quantify existing relationships (quantify relationships from historical data and apply those relationships to new data sets).
- Discover latent relationships (draw inferences buried in the data).
Machine Learning accomplishes these two tasks using either supervised or unsupervised learning algorithms. What’s the difference? Supervised learning includes the classification or categorization of the outcomes (e.g., fraudulent transaction, customer attrition, part failure, patient illness, purchase transaction, web click) in the observations. Unsupervised learning does not have the outcomes in the observations.
Supervised Learning
Supervised learning algorithms make predictions based on a set of examples. For example, historical sales can be used to estimate the future prices. With supervised learning, you have an input variable that consists of labeled training data and a desired output variable. You use an algorithm to analyze the training data to learn the function that maps the input to the output. This inferred function maps new, unknown examples by generalizing from the training data to anticipate results in unseen situations.
- Classification: when the objective field is categorical. For these problems, a Machine Learning algorithm is used to build a model that predicts a category (label or class) for a new example (instance). That is, it “classifies” new instances into a given set of categories (or discrete values). For example, “true or false”, “fraud or not fraud”, “high risk, low risk or medium risk”, etc. There can be hundreds of different categories.
- Regression: when the objective field is numeric. For these problems, a Machine Learning algorithm is used to build a model that predicts a continuous value. That is, given the fields that define a new instance the model predicts a real number. For example, “the price of a house”, “the number of units sold for a product”, “the potential revenue of a lead”, “the number of hours until next system failure”, etc.
Both classification and regression problems can be solved using supervised Machine Learning techniques. They are called supervised in the sense that the values of the output variable have either been provided by a human expert (e.g., the patient had been diagnosed with diabetes or not) or by a deterministic automated process (e.g., customers who did not pay their fees in the last three months are labeled as “delinquent”). The objective field values along with the input fields need to be collected for each instance in a structured dataset that is used to train the model. The algorithms learn a predictive model that maps your input data to a predicted objective field value.
Unsupervised Learning
When performing unsupervised learning, the machine is presented with totally unlabeled data. It is asked to discover the intrinsic patterns that underlie the data, such as a clustering structure, a low-dimensional manifold, or a sparse tree and graph.
Clustering: Grouping a set of data examples so that examples in one group (or one cluster) are more similar (according to some criteria) than those in other groups. This is often used to segment the whole dataset into several groups. Analysis can be performed in each group to help users to find intrinsic patterns.
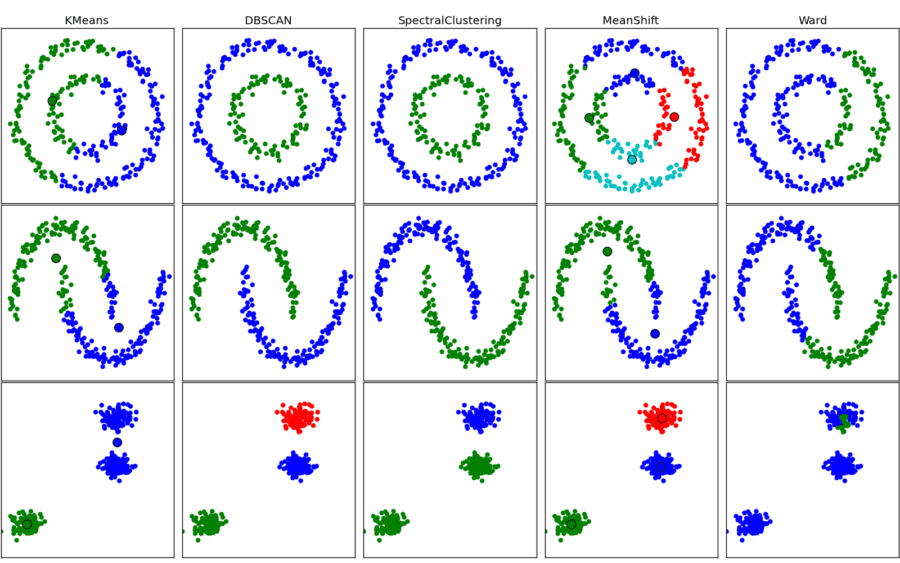
- Association: If-then statements that uncover relationships within the data. An example of an association rule would be “If a customer buys a dozen eggs, he is 80% likely to also purchase milk.”

- Neural Networks: Modeled after the human brain, a neural network consists of a large number of processors operating in parallel and arranged in tiers (feedforward). The first tier receives the raw input information and each successive tier receives the output from the preceding tier and performs further analysis. The last tier produces the output of the system. Neural networks are adaptive, which means they modify themselves as they learn from initial training and subsequent runs provide more information about the world.

- Recurrent neural network (RNN) is a class of artificial neural network where connections between units form a directed cycle. This creates an internal state of the network that allows it to exhibit dynamic temporal behavior. Unlike feedforward neural networks, RNNs can use their internal memory to process arbitrary sequences of inputs. This makes them applicable to tasks such as unsegmented connected handwriting recognition or speech recognition.
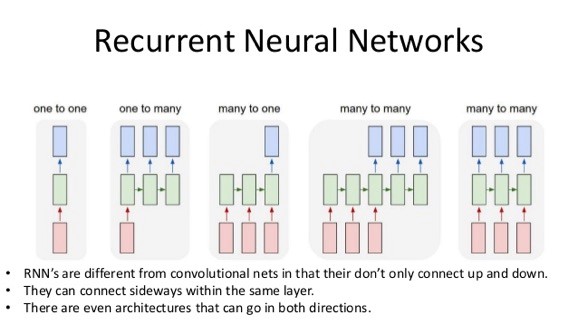
Figure 2 provides a more detailed inventory of the different types of supervised and unsupervised machine learning algorithms.
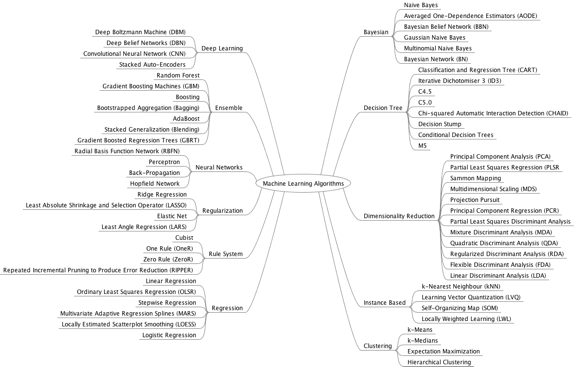
Figure 2: Types of Machine Learning Algorithms
Putting Machine Learning To Work
In a recent University of San Francisco project that we conducted with a local data science company, I was introduced to a product called BigML I was truly blown away by the relative simplicity of the tools (think “Tableau for Machine Learning”). I have no financial interest in BigML and suspect that as soon as this blog gets published, I will hear from other startups that are building something similar. But until I get those calls, I’m going to use BigML to showcase some Machine Learning basics.
BigML is free for the first 16MB (not 16GB as I had originally stated) of data and comes with some pre-loaded data sets and an extensive library of documentation, some of which I used for this blog. For this exercise, we’re going to use a data set that comes bundled with the BigML product: Titanic Survivors Data Set (see Figure 3).
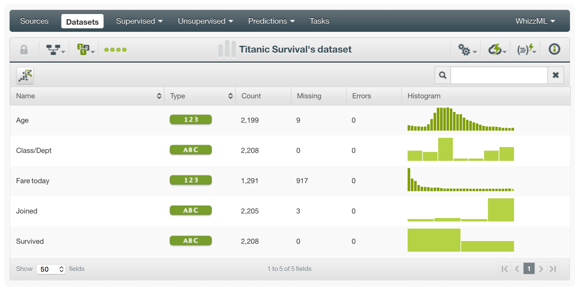
Figure 3: Titanic Survivors Data Set
BigML provides a nice feature to allow the data scientist to explore and understand the data sets, and provides some basic statistical information (minimum, median, mean, maximum, standard deviation, kurtosis, skewness) about each of the variables in the data set.
BigML allows you to select from a variety of supervised and unsupervised models. I selected the supervised option (because I knew the classification of the passenger as survived or not survived) and got the decision tree in Figure 4 that predicts the likelihood of a Titanic passenger surviving given a wide variety of different variables (e.g., passenger age, class of travel, fare paid, in what city the passenger boarded).
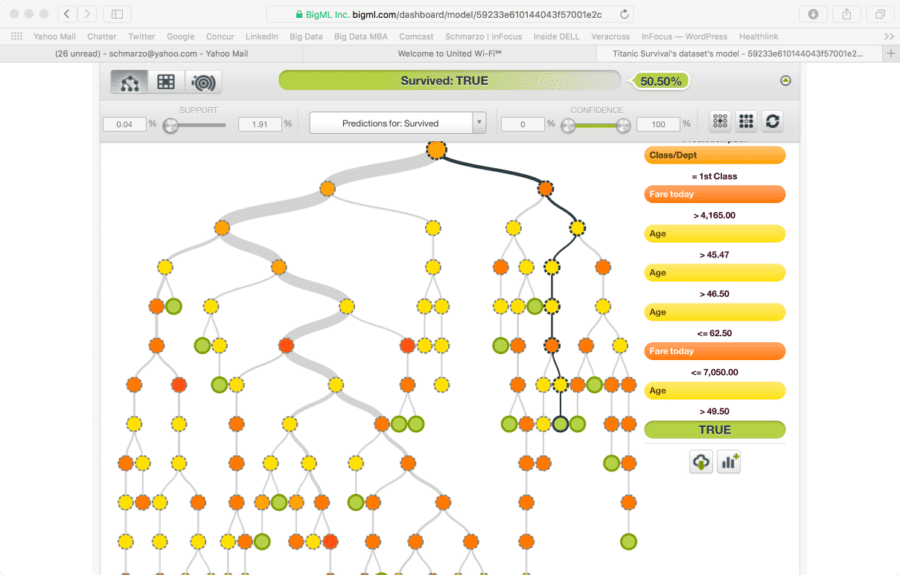
Figure 4: Titanic Survivors Decision Tree
The resulting Decision Tree provides a series of “If-then” statements; each branch “yields a story” about the chances of survival.
Hint: you want to be young and you want to be rich to improve your odds of surviving the Titanic. That’s something that might be very useful if you ever find yourself on the Titanic.
BigML provides a wide variety of machine learning algorithms with which one can play. Plus their documentation on each of the different machine learning algorithms is very impressive. I think these folks would make a fortune if they created an accompanying text book (and I sent them a note telling them such).
Machine Learning Summary
Both Supervised and Unsupervised learning algorithms will find relationships and occurrences in the data that might be relevant. The data scientist and the business stakeholder still must apply common sense to the findings; they must apply domain knowledge to ensure that not only are the uncovered relationships and insights “Strategic, Actionable and Material,” but they simply must apply common sense in order to prevent making statements of fact that just don’t make sense.
No amount of machine learning is going to replace good old common sense.
Appendix: Additional Machine Learning Sources
- Machine Learning, Deep Learning, and AI: What’s the Difference?
- Machine learning and data mining
- Data Science of Variable Selection: A Review
- Recurrent neural network
- Which Machine Learning Algorithm Should I Use (SAS)?
- Machine Learning
- The Data Science Behind AI
- Top 10 AI And Machine Learning Use Cases Everyone Should Know About
- BigML Tutorials and webinars
{kind=link}