
Summary: Want to win a Kaggle competition or at least get a respectable place on the leaderboard? These days it’s all about ensembles and for a lot of practitioners that means reaching for random forests. Random forests have indeed been very successful but it’s worth remembering that there are three different categories of ensembles and some important hyper parameters tuning issues within each Here’s a brief review.
 The Kaggle competitions are like formula racing for data science. Winners edge out competitors at the fourth decimal place and like Formula 1 race cars, not many of us would mistake them for daily drivers. The amount of time devoted and the sometimes extreme techniques wouldn’t be appropriate in a data science production environment, but like paddle shifters and exotic suspensions, some of those improvement find their way into day-to-day life. Ensembles, or teams of predictive models working together, have been the core strategy for winning at Kaggle. They’ve been around for a long time but they are getting better. When we say ensemble, many of us immediately think of tree ensembles like random forest but there are three distinct groups each with their own strengths and weaknesses.
The Kaggle competitions are like formula racing for data science. Winners edge out competitors at the fourth decimal place and like Formula 1 race cars, not many of us would mistake them for daily drivers. The amount of time devoted and the sometimes extreme techniques wouldn’t be appropriate in a data science production environment, but like paddle shifters and exotic suspensions, some of those improvement find their way into day-to-day life. Ensembles, or teams of predictive models working together, have been the core strategy for winning at Kaggle. They’ve been around for a long time but they are getting better. When we say ensemble, many of us immediately think of tree ensembles like random forest but there are three distinct groups each with their own strengths and weaknesses.
Ensembles in General
There are three broad classes of ensemble algorithms:
- Bagging– Random Forests are in this group
- Boosting
- Stacking
The idea behind ensembles is straightforward. Using multiple models and combining their results generally increases the performance of a model or at least reduces the probability of selecting a poor one. One of the most interesting implications of this is that the ensemble model may in fact not be better than the most accurate single member of the ensemble, but it does reduce the overall risk.
There are a number of strategies for combining single predictors into ensembles represented by the three major groups above and lots of detailed variation among implementations even within these groups. Despite the warning that ensembles can actually only guarantee to reduce risk, most of us have experienced that our most accurate models are in fact ensembles.
The Diversity Requirement
In order for this group strategy to be effective it’s should be obvious that they must be different in some way so the individual models don’t all create the same error. This is the requirement for diversity in ensembles and can be achieved in a variety of different ways.
One common way is to expose each classifier to different training data, most often through the use of bootstrap or jackknife resampling. Another strategy used separately or in combination with resampling is to expose the learners to different combinations of features.
The diagram below (Robi Polikar (2009), Scholarpedia, 4(1):2776) illustrates how the slightly different errors from each individual predictor are combined to create the best decision boundary.
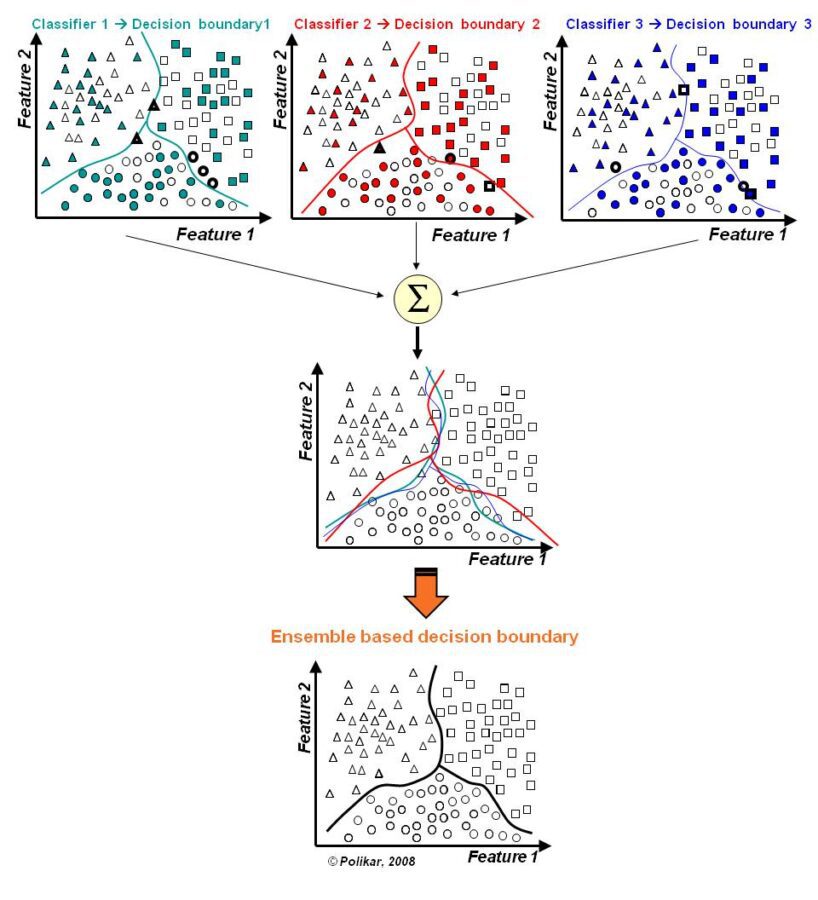 Guaranteeing Diversity
Guaranteeing Diversity
There are many different strategies for ensuring diversity including combining different types of modeling algorithms (e.g. decision trees with neural nets with SVMs and others) and also how the results of each independent model are combined. Ensembes may be categorized as either ‘selected’ or ‘fused’.
In the ‘selected’ strategy the model which most accurately portrays a specific region of data is selected as the single predictor for that region and then combined with other similarly successful models that most accurately portray other specific areas of the data making up a patchwork of individual predictors.
The ‘fused’ strategy is more common and defines the dominant approach in bagging. The results of the individual models are combined through a variety of rules that range from simple majority voting to algebraic techniques including averaging, sum, or versions of min and max.
These two elements of diversity, 1.) the specific procedures used in generating the individual classifiers, and 2.) the method used for combining their results are the foundational elements of the three major categories of ensembles.
Bagging (Bootstrap Aggregating)
Popular Tool: Random Forest
Concept: Bagging is perhaps the earliest ensemble technique being credited to Leo Brieman at Berkeley in 1996. It trains and selects a group of strong learners on bootstapped subsets of data and yields its result by simple plurality of voting.
Originally it was designed for decision trees but it works equally well with other unstable classifier types such as neural nets.
Strengths:
- Robust against outliers and noise.
- Reduces variance and typically avoids overfitting.
- Easy to use with limited well established default parameters. Works well off the shelf requiring little additional tuning.
- Fast run time.
- Since it is tree based it confers most of the advantages of trees like handling missing values, automatic selection of variable importance, and accomodating highly non-linear interactions.
Weakness:
- Can be slow to score as complexity increases.
- Lack of transparancy due to the complexity of multiple trees.
Boosting
Popular Tools: Adaboost, Gradient Boosted Models (GBM).
Concept: Similar to Bagging but with an emphasis on improving weak learners. Each iteration of boosting creates three weak classifiers. The first classifier is trained normally on a subset of the data. The second classifier is trained on data in which the first classifier achieved only 50% correct identification. The third classifier is trained on data for which the first and second classifier disagree. The three classifiers are combined through a simple majority vote.
Adaboost and GBM are quite similar except in the way they deal with their loss functions.
Strengths:
- Often the best possible model.
- Directly optimizes the cost function.
Weaknesses
- Not robust against outliers and noise.
- Can overfit.
- Need to find proper stopping point.
- Several hyper-parameters.
- Lack of transparancy due to the complexity of multiple trees.
Comparing Bagging and Boosted Methods
Model error arises from noise, bias, and variance.
- Noise is error by the target function.
- Bias is where the algorithm cannot learn the target.
- Variance comes from sampling.
Bagging is not recommended on models that have a high bias. Boosting is recommended for high bias.
Conversely Boosting is not recommended for cases of high variance. Bagging is recommended for high variance.
Both techniques can effectively deal with noise.
Stacking
Stacking (aka Stacked Generalization or Super Learner) may be the optimum ensemble technique but is also least understood (and most difficult to explain). Stacking creates an ensemble from a diverse group of strong learners. In the process it interjects a metadata step called ‘super learners’. These intermediate meta-classifiers are forecasting how accurately the primary classifiers have become and are used as the basis for adjustment.
Yes this is tough to follow. Here is the explanation directly from Dr. Polikar on Scholarpedia:
“In Wolpert’s stacked generalization (or stacking), an ensemble of classifiers is first trained using bootstrapped samples of the training data, creating Tier 1 classifiers, whose outputs are then used to train a Tier 2 classifier (meta-classifier) (Wolpert 1992). The underlying idea is to learn whether training data have been properly learned. For example, if a particular classifier incorrectly learned a certain region of the feature space, and hence consistently misclassifies instances coming from that region, then the Tier 2 classifier may be able to learn this behavior, and along with the learned behaviors of other classifiers, it can correct such improper training. Cross validation type selection is typically used for training the Tier 1 classifiers: the entire training dataset is divided into Tblocks, and each Tier-1 classifier is first trained on (a different set of) T-1 blocks of the training data. Each classifier is then evaluated on the Tth (pseudo-test) block, not seen during training. The outputs of these classifiers on their pseudo-training blocks, along with the actual correct labels for those blocks constitute the training dataset for the Tier 2 classifier (see Figure below)”.
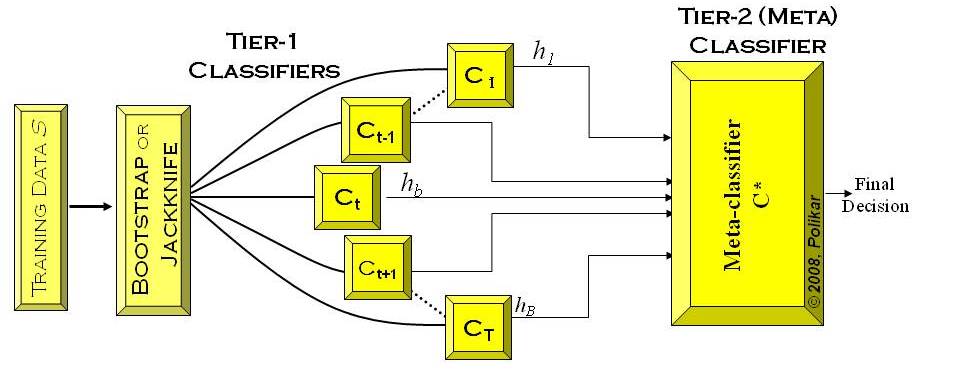
Accuracy Beyond Ensembles – XGBoost
So far we’ve been focusing on various ensemble techniques to improve accuracy but if you’re really focused on winning at Kaggle then you’ll need to pay attention to a new algorithm just emerging from academia, XGBoost, Extreme Gradient Boosted Trees. It’s open source and readily available.
This is a massively scalable, out of core algorithm developed by Tianqi Chen at the University of Washington. See the full paper here. Here’s his claim:
- Among the 29 challenge winning solutions published at Kaggle’s blog during 2015, 17 solutions used XGBoost.
- Among these solutions, eight solely used XGBoost to train the model, while most others combined XGBoost with neural nets in ensembles.
- For comparison, the second most popular method, deep neural nets, was used in 11 solutions.
- The success of the system was also witnessed in KDDCup 2015, where XGBoost was used by every winning team in the top-10.
- Moreover, the winning teams reported that ensemble methods outperform a well-configured XGBoost by only a small amount.
Remarkable. This is why its fun to be a data scientist. Just when you thought the last little bit has already been wrung out of the math, along comes an innovative new approach.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}