
So many fascinating and deep results have been written about the number (1 + SQRT(5)) / 2 and its related sequence – the Fibonacci numbers – that it would take years to read all of them. This number has been studied both for its applications (population growth, architecture) and its mathematical properties, for over 2,000 years. It is still a topic of active research.

Fibonacci numbers are used in stock market and population growth models
I show here how I used the golden ratio for a new number guessing game (to generate chaos and randomness in ergodic time series) as well as new intriguing results, in particular:
- Proof that the rabbit constant is not normal in any base; this might be the first instance of a non-artificial mathematical constant for which the normalcy status is formally established.
- Beatty sequences, pseudo-periodicity, and infinite-range auto-correlations for the digits of irrational numbers in the numeration system derived from perfect stochastic processes
- Properties of multivariate b-processes, including integer or non-integer bases.
- Weird behavior of auto-correlations for the digits of normal numbers (good seeds) in the numeration system derived from stochastic b-processes
- A strange recursion that generates all the digits of the rabbit constant
This article also features techniques to de-correlate time series.
 Table of Contents
Table of Contents
Some Definitions
Digits Distribution in b-processes
Strange Facts and Conjectures about the Rabbit Constant
Gaming Application
- De-correlating Time Series Using Mapping and Thinning Techniques
- Dissolving the Auto-correlation Structure Using Multivariate b-processes
Related Articles
1. Some Definitions
We use the following concepts in this article:
- A normal number is a number that has its digits uniformly distributed. If you pick up a number at random, its binary digits are uniformly distributed: the proportion of zero’s is 50% and the digits are not auto-correlated, among other things. No one knows if constants such as Pi, log 2, SQRT(2), or the Euler constant, are normal or not.
- Rather than normal numbers, we rely on the concept of good seeds, which is a generalization to numeration systems where the base b might not be an integer. In such systems, the vast majority of numbers (good seeds) have digits that are distributed according to some specific equilibrium distribution, usually not a uniform distribution. Also they have a specific auto-correlation structure. Any number with a different digit distribution or auto-correlation structure is called a bad seed. Typically, rational numbers are bad seeds. Examples of numeration systems, with their equilibrium distribution, are discussed here, also here, and in my book.
- The concept of numeration system can be extended to non-integer bases. Two systems have been studied in detail: perfect processes and b-processes, see here. The b-process generalizes traditional numeration systems. In that system, a sequence x(n+1) = { b x(n) } is attached to a seed x(1), where the brackets represent the fractional part function, and b is a real number larger than 1. The n-th digit of the seed x(1) is defined as INT(b x(n)). When b is an integer, it corresponds to the traditional base-b numeration system.
- The perfect process of base b is characterized by the recursion x(n+1) = { b + x(n) } and a seed x(1), where b is a positive irrational number. In that system, the n-th digit of the seed x(1) is defined as INT(2 x(n)). All seeds including x(1) = 0 are good seeds. Also, x(n+1) = { nb + x(1) }. A table comparing b-processes with perfect processes is provided in section 4.1.(b) in this article. Perfect processes are related to Beatty sequence (see also here.)
- By gentle chaos, we mean systems that behave completely chaotically, but that are ergodic. By ergodicity, we mean that these systems have equilibrium distributions, also called attractor distributions in the context of dynamical systems, or stable distributions in the context or probability theory. The equilibrium can be found using a very long sequence x(n) starting with any good seed, or using x(1) only and a large number of different (good) seeds.
2. Digits Distribution in b-processes
It is known that the digits are not correlated, and that the digit distribution is uniform if b is an integer. If the base b is not an integer, the digits take values 0, 1, 2, and so on, up to INT(b). Then, the digit distribution and auto-correlation (for good seeds) is know only for special bases, such as the golden ratio, the super-golden ratio, and the plastic number: see section 4.2. in this article for details. Also, the lag-k auto-correlation in base b is equal to the lag-1 auto-correlation in base b^k. The picture below shows the empirical lag-1 auto-correlation for b in ]1, 4]. The bumps are real and not caused by small sample sizes in our computations.
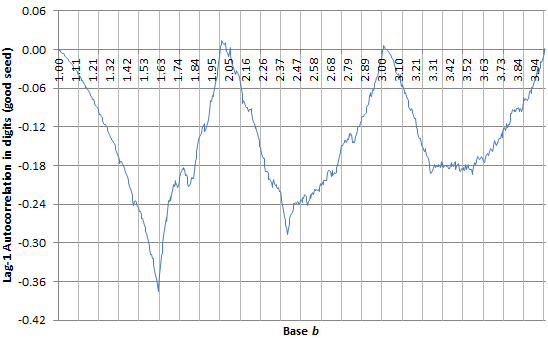
Figure 1: Lag-1 auto-correlation in digit distribution of good seeds, for b-processes
Figure 1 shows that the the lag-1 auto-correlation, for any good seed, is almost always negative. In particular, it is always negative if b is in ]1, 2[. It is minimum for the golden ratio b = (1 + SQRT(5)) / 2 and in that case, its value is (-3 + SQRT(5)) / 2. This fact can be proved using results published here (see section 3.2.(a) about the golden ratio process.)
Finally, unlike perfect processes that have long range (indeed, infinite range) auto-correlations just like periodic time series, for b-processes auto-correlations are decaying exponentially fast. See here for illustrations.
The digit distribution, for b in ]1, 2], is pictured in section 4.3.(b) in this article. If b is in ]1, 2[, the digits are binary and the proportion of zero’s is always less than 50%. .
3. Strange Facts and Conjectures about the Rabbit Constant
The rabbit constant R = 0.709803442861291 … is related to Fibonacci numbers (and thus to the golden ratio) used to model demographics in rabbit populations. It is typically defined by its sequence of binary digits in the ordinary binary numeration system (a special case of b-processes with b = 2) and it has an interesting continued fraction expansion, see here.
We use here a different approach to construct this number, leading to some interesting results. First, let us introduce a new constant. We call it the twin rabbit constant, and it is denoted as R*.
The twin rabbit constant R* is built as follows:
- x(n) = { n (-1 + SQRT(5)) / 2 } for n = 1, 2, and so on
- d(n) =INT(2 x(n)) is equal to 0 or 1
- R* = d(1)/2 + d(2)/4 + d(3)/8 + d(4)/16 + d(5)/32 + … = 0.6470592723139 …
The rabbit constant R is built as follows, using the same sequence x(n):
- x(n) = { n (-1 + SQRT(5)) / 2 } for n = 1, 2, and so on
- g(n) = INT(x(n))
- e(n) = g(n+1) – g(n) and is thus equal to 0 or 1
- R = e(1)/2 + e(2)/4 + e(3)/8 + e(4)/16 + e(5)/32 + … = 0.709803442861291 …
Note that x(n) is a perfect process with b = (-1 + SQRT(5)) / 2.We have the following properties:
Facts and Conjectures
Here are a few surprising facts:
- The digits d(n) and e(n), respectively of R* and R, are identical about 88% of the time. The exact figure is probably (4 – SQRT(5)) / 2.
- If d(n) and e(n) are different, d(m) and e(m) are different, with m > n, and for all values between n and m, the digits are identical, then m – n must be equal to 5, 8 or 13. This is still a conjecture; I haven’t proved it.
- The function g(n) satisfies the recurrence relation g(n) = n – g( g(n -1) ) with g(0) = 0. I published the proof in 1988, in Journal of Number Theory (download the proof).
- The lag-1 auto-correlation in the digit sequence e(n) is equal to (1 – SQRT(5)) / 2. You can try to prove this fact, as an exercise. This is lower than the lowest value that can be achieved with any good seed, in any b-process. We have the same issue with the sequence d(n). As a result, the binary digits e(n) and d(n) of the rabbit and twin rabbit numbers can not generate a good seed (or normal number) in any base.
- The proportion of digits equal to zero in the rabbit number, is (3 – SQRT(5)) / 2, also too low to be a good seed, regardless of the base. For the twin rabbit number, the proportion is 50%.
It would be interesting to study the more general case where b is any positive irrational number, constructing twin numbers using the same methodology, and analyze their properties. Some of the candidate numbers include those listed in the Beatty sequence. Here we only focused on b = (-1 + SQRT(5)) / 2. As a general result, the binary digits of the twin numbers generated this way, can never generate a good seed in any base, because they are too strongly auto-correlated.
4. Gaming Application
We use this technology in our generic number guessing game. Our gaming platform features pre-computable winning numbers, and payout based on the distance between guesses and winning numbers. This system is described here, and I will present it at the INFORMS annual meeting in Seattle in October 2019. It mimics a stock market or lottery game depending on the model parameters. At its core, among many sequences, we also use the golden ration b-process x(n) described in section 3.2 in my article on randomness theory. Here b = (1 + SQRT(5)) / 2. Of course, we start with a good seed.
In order to make the number guessing process more challenging, we de-correlate the digits. For this purpose, we consider two options.
De-correlating Using Mapping and Thinning Techniques
This option consists of de-correlating the sequence x(n). The first step is to map x(n) onto a new sequence y(n), so that the new equilibrium distribution becomes uniform on [0, 1]. This is achieved as follows:
If x(n) < b -1, then y(n) = x(n) / (b – 1) else y(n) = (x(n) – (b – 1)) / (2 – b).
Now the y(n) sequence has a uniform equilibrium distribution on [0, 1]. However, this new sequence has a major problem: high auto-correlations, and frequently, two or three successive values that are identical (this would not happen with a random b, but here b is the golden ratio — a very special value — and this is what is causing the problem.)
A workaround is to ignore all values of x(n) that are larger than b – 1, that is, discarding y(n) if x(n) is larger than b -1. This is really a magic trick. Now, not only the lag-1 auto-correlation in the remaining y(n) sequence is equal to 1/2, the same value as for the full x(n) sequence with b = 2, but the lag-1 auto-correlation in the remaining sequence of binary digits (digits are defined as INT(b y(n)) is also equal to zero, just like for ordinary digits in base 2.
Dissolving the Auto-correlation Structure Using Multivariate b-processes
An interesting property of b-processes is the fact that auto-correlations in x(n) are decaying exponentially fast. In fact, for any good seed, the lag-k auto-correlation in base b is equal to the lag-1 auto-correlation in base b^k. Note that if b is an integer, the lag-1 auto-correlation is equal to 1 / b.
Another interesting property is the fact that two sequences x(n) and y(n) using different (good) seeds x(1) and y(1), and the same base b, are independent if the seeds are independent in base b. The concept of independent seeds will be formally defined in a future article, but it is rather intuitive. For instance, the seeds x(1) and y(1) = x(3) are not independent, regardless of the base.
Thus, in order to dilute the auto-correlations by a factor b^k, one has to interlace k sequences using the same base b for each sequence, but using k independent good seeds, one for each sequence. Doing so, we are actually working with multivariate b-processes that are not cross-correlated. The same mechanism can be applied recursively to each of the k sequences, eventually resulting in multiple layers of nested sequences (a tree structure) to further reduce auto-correlations. Finally, re-mapping the resulting process may be be necessary to obtain a uniform equilibrium distribution.
Note that if b is an integer, there is no need to de-correlate as the sequence of digits is automatically free of auto-correlations. Also, in that case, no re-mapping is needed as the equilibrium distribution is uniform to begin with.
Related Articles
- Long-range Correlations in Time Series: Modeling, Testing, Case Study
- Stable and Attractor Distributions
- Free Book: Applied Stochastic Processes
- New Stock Trading and Lottery Game Rooted in Deep Math
- Fascinating New Results in the Theory of Randomness
- Number Representation Systems Explained in One Picture
To not miss this type of content in the future, subscribe to our newsletter. For related articles from the same author, click here or visit www.VincentGranville.com. Follow me on on LinkedIn, or visit my old web page here.
{kind=link}