

Every organization has to prepare for the abandonment of everything it does.
Peter Drucker
In this series, Ive been describing a data democracy thats just a dream now. That dream is comparable to what Thomas Hobbes and John Locke wrote about when it came to a nation’s people and individual identity to more than 330 years ago. A number of Locke’s concepts (such as individual rights including “life, liberty and the pursuit of happiness”) later ended up in the US Declaration of Independence, and also informed the French Revolution closely afterwards.
Data democracy, similarly, grants individual rights to users such as the right to personal data control and protection and the right to store,share, protect and preserve your data as you deem fit, e.g., using the InterPlanetary File System (IPFS) or another comparable peer-to-peer (P2P) data network and the layers of services on top of these.
Data democracy will become increasingly critical once we reach the era of personal digital twins that could represent users individually and allow individual users and other things to interact.Online interaction itself generates an intermittent flow of data that implies a need to protect the ownership rights of individual users beyond data in place.(See https://www.datasciencecentral.com/profiles/blogs/why-we-shouldn-t-… for a take on why a digital twin-based metaverse will take 25 years or more.)
Spending less time at feudal data manors and more on the dweb
Are some of the more innovative companies and users incrementally deepening their commitment to P2P data networks and other less centralized platforms and tooling? (Some are calling this environment the decentralized web, or dweb.) It seems so. At the same time, a renewed community of startups is already well along toward developing a more functional, more decentralized environment overall.
Below was the 2020 status and 2021 next steps that Steven McKie of Aventum Capital noted and anticipated last year. He considered IPFS already mature, and the progression in overall functionality since 2015 has been undeniable:
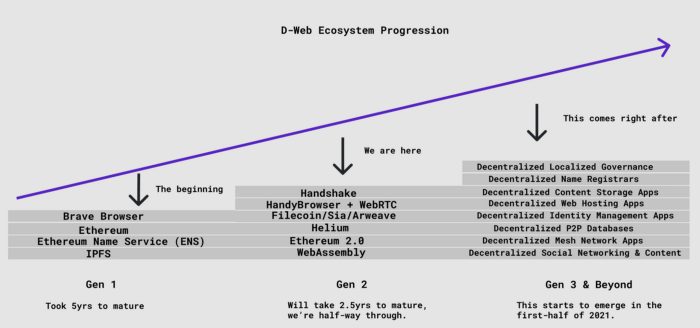
Steven McKie, “The Decentralized Web:Explaining the Impending DWeb Explosion,” Medium, August 13, 2020,
https://medium.com/blockchannel/the-decentralized-web-a87b2b9d100,
What others can do now
The window of opportunity is already opening. Keep in mind: Data democracy at scale will be near-on impossible given current centralized IT architectures and the occupied data territory that’s already staked out. Currently, when it comes to most data that’s generated online, social media, cloud services and ecommerce companies claim possession, and that data is too valuable for them to relinquish the unfettered use of.
As a result, the data inequalities between the Haves and the Have Nots will only grow wider, Such inequality has already led to an urgent desire to escape the confinement of centralized social media and other cloud services,stake out new data territory as well as make use of more decentralized platforms and services.
I pointed out in Parts I and II that data democracy could start small, allowing at least the most vulnerable correlatable identifiers of users (such as passport and social security numbers) to stay on the devices of those users, using on-device matching and encryption to ensure those identifiers arent duplicated in thousands of different corporate and government repositories that are vulnerable to data breaches.
Data villages and towns are already springing up, and less centralized ledgers that have distributed hash table addressing compatible with IPFS have already existed for a dozen years or more.
The best chance data democracy has would be to embrace new peer-to-peer data networks such as IPFS, along with the personal data protection IPFS offers by default. Older web and app-centric mobile architecture at this point encourages the farming and harvesting of more and more personal data by social media and search companies. In the process, we could give control of the most sensitive personal data back to users.
Using tech in old, feudal ways just doesnt make sense any more. Improvements in technology should ensure independence. Quite a few people already realize that and are already starting to use P2P data networks and, along with it, a different, more rationalized development stack.
Lifes persistent information problems that remain unsolvedand why
If we have nations that claim to operate more or less democratically, why dont we have data democracy? Part I pointed out that, surprisingly enough, as weve moved at least of portion of societal interaction online, weve reverted to a form of data feudalism in the process.
How did we regress to feudalism in the 2000s, considering that many of us have been used to living under a democratic (with a small d) system? Because democracy is fragile, governments move slowly, and the public at large doesnt understand the consequences of very large companies capturing and harvesting their data, making individual users data serfs in process.
We’ll be able to escape this data feudalism if were smart about it and work together in the most innovative and deeply collaborative ways we can, in part by harnessing an environment with far fewer boundaries to negotiate. Nearly 80 years after the first IBM mainframe, 45 years after the introduction of the Apple Computer and 40 years after the introduction of the IBM PC, were able to do much more with digitized information than we think:
- We have the compute, networking and storage to automate supply chains, collaborate, optimize and scale processes in a single unified, dynamic environment much more than we actually have.
- We have the technology to build interactive digital twins that represent entities in a supply network and run simulations with the help of those digital twins.
- Were figuring out how encryption, immutability, smart contracts and related agents together can build a base layer of self-executing agreements, governance and autonomy.
Dont believe me? Then Im guessing you may have not turned over as many rocks as I have, confirming over and over for 25 years of studying emerging enterprise technology that, as William Gibson said, The future is here; its just less evenly distributed.
So why dont we do more than were doing? People working together less effectively than they can are the gating factor. We cant seem to optimize how people work together in a practical, problem solving context to solve big problems.
For example, in software and systems, were creating too much duplication and too many dependencies, resulting in complexity spiraling out of control that we have to fight with constantly just to keep systems stable. (The book Software Wasteland by Dave McComb makes the complexity case compellingly, and prescribes a data-centric architecture solution.)
Granted, some of us are doing much better at solving big problems than others. (See, for example, The Blue Brain project, focused on reverse engineering the brain, and the Blue Brain Nexus knowledge graph, used by academics globally to share information and collaborate with the help of that information.)
Whats an example of a big problem we cant seem to solve at all? Adapting to the increasing rate of change. Peter Drucker said years ago, Every organization has to prepare for the abandonment of everything it does. In our case, we need to abandon application-centric architecture, as well as centralized data security and archaic (=25 years old) forms of web identity that just get in the way.
How to stop being a part of the problem and contribute to the momentum of data democracy
Data can represent anything. Logic, for example, can be represented as data and shared via knowledge graphs, and its clear that a lot of logic would be better served if it werent trapped in applications, and if it were more accessible as data.
So ultimately we’re not just talking about traditional data here. Were talking about the data cognoscenti being responsible for more than just data as traditionally defined, for more than extracting the immediately acceptable value from data with a small d for one project.
Data is a means of representation, a means of representing all things real and imagined online so that we can bring humans and machines together into the same feedback and continuous improvement loops. Digital twins are representations described in data and governed by logic that can also be described in data.
Were talking about assuming responsibility for iteratively building a world of interactive digital twins that have to meet all sorts of requirements, without applications and all their substandard integration methods and other obsolete baggage getting in the way.
In a data-centric world, wed be talking about Data (the superset with the big D that includes represented knowledge, which includes logic) eating software (the subset, which can all be represented as data), and capable humans building data-centric systems so that we can finally abandon ancient architecture designed for times when we didnt have the compute, networking and storage we do now.
How do we start?
We start by getting preconceptions out of our heads that might have made some sense at an earlier point, given the limitations. Working with P2P data networks and the nascent layers on top of those networks suggests new understanding of fundamental concepts.
With the right data representations we can stand back, study and manipulate the concepts or objects represented to see what happens when you do things this way, or that way.
So many diverse talents can help open these opportunities up. We don’t just need data scientists, engineers and analysts. We need synthesists (the obverse of analysts, bringing more sources together and envisioning how systems can evolve), abstractionists (to capture the essence of meaning at higher, more abstract levels), etc. To bridge the gap between tech and business, we need people who can envision how systems will come together. We need a new conceptualization of rolesa clean slate that articulates how humans and machines can work together more closely to create digital twins and the data interoperability that can enable them.
Most of all, we need to acknowledge and raise awareness: Knowing whats most important about technology and especially online data and how to protect whats yours isn’t just helpfulit’s essential for self-defense.
){kind=link}