
 publicdomainpictures.net
publicdomainpictures.net
Part I of this series described the data feudalism we currently have, why we have it, and how it might be possible for at least some of us to escape it. The inspiration for this series has been the evident, but narrow window of opportunity thats now opening with the help of Peer-to-Peer (P2P) Data Networks to create new data democracy communities from scratch.
Keep in mind that in this series of posts, Im not promoting some overblown, grandiose scheme to build global online governments. Instead, Im just saying small, humble refuges in the decentralized Wild West could be built (and are already being built) town by town. Some of the better towns could offer distinct advantages to those who find the commonly used, feudalized online web + mobile app environment too restrictive, dysfunctional, inefficient or oppressive.
These towns could only establish a form of data democracy with a well-conceived and designed data and logic architecture, one that puts data and users first. They could also conceivably create much more effective governance at small scale, with the right leadership and vision.
Data pioneers living in the online Wild West
Not everyone needs to live in these towns for an online version of pioneers moving west to succeed. Like the US during the 19th century, the bulk of the population could remain, more or less complacent, living in the data equivalent of the established East and behaving much as they have since the advent of the Open Systems Interconnection (OSI) model in the 1970si.e., as passive, apathetic users of an increasingly complex and unmanageable, centrally controlled system.
The pioneers (among whom would be some mere speculators, the criminally inclined, and other sorts of neer do wells) would be the ones to stake claims in this new digital territory. Those who are principled, as always, would have to defend themselves from those who arent. Much would depend on proactive, informed strategy and execution that users and many independent developers havent been previously known for.
Within each new online town, townspeople with shared goals and values could band together and learn how to survive and then thrive in the new environment. They could harness the resources of P2P data networks born decades ago in the most chaotic, single purpose, early phases of the online Wild West.
With recent refinement to those networks, they could build a new data and logic foundation, one that could be far less wasteful, designed from scratch to protect data, with a far less complex stack to manage.
If such a data-centric and reusable logic foundation succeeds, people and organizations might flock to it. Stranger things have happened.
This kind of data and logic foundation could be the best hope for true personal data protection and an effective data ownership or custody model. Otherwise, users will continue to struggle against data oligarchs and data cartels fostered by feudalistic architecture assumptions.
Next, Part II outlines some of the key a advantages inherent in current generation of P2P data networks such as the InterPlanetary File System (IPFS), and how it could be possible today to create starter democratic (with a small d) data communities with the help of IPFS and the other software that facilitates the broader use of IPFS.
Why use a graph-based P2P file system as a data network?
Much has been made of the decentralized, self service nature of P2P networks. BitTorrent for large file transfers comes to mind. BitTorrent has been around for 20 years.
But P2P networks have evolved substantially. In the process, theyve become more diverse, and the file systems they use are designed to be more capable. Some of the other benefits include these:
- A unified information space. InterPlanetary LInked Data (IPLD) makes a single unified IPFS information space possible, which can connect with other networks and ledgers that have hash linking.
- Development stack simplification. A whole development stack emerged for IPFS, one that reduces the number of layers that application developers have to manage.
- Content addressing sophistication. IPFSs use of a cryptographic distributed hash table (DHT) addressing scheme decouples the content identifier (CID) from the source node location. The data itself can be retrieved from other nodes than the original source node. Consultant Andrew Padilla points out that data discovery via IPFS is comparable to service discovery in the cloud. Like service discovery, he says,
“CIDs represent a named resource that can be addressed independent of where the resource resides. In fact, IPFS will attempt to find the nearest neighbor that has a copy of the data that underlies the CID. This capability is the data equivalent to the K8s scheduler routing your service request to the least busy pod¦.
What this means is that if I have a CID in hand, I can retrieve its underlying data resource from any node on the IPFS network in possession of it without caring where or by whom I received my copy because its verifiable.”
Andrew Padilla, IPFS Content Addressing: IPFS Content Addressing: The key to data discovery through data addressibility, Medium, October 1, 2021, https://medium.datadriveninvestor.com/ipfs-content-addressing-the-k…
Virtual file system. IPFS has a virtual file system, version control and immutable data storage/file sharing/use for data thats in some ways comparable to Gits code version control scheme and associated immutable storage. Some features include these:
- The default is public sharing, but private networks are also easily set up.
- Anyone can put data out on the network securely, and anyone can retrieve it securely.
- Immutability, versioning and hash table-enabled verification give users assurance that a version has not been tampered with.
- The associated IPLD data model plays well with other P2P/DHT content addressing-enabled systems, implying that IPFS can complement and interact with distributed ledger technology (DLTs) or public blockchains such as Bitcoin or Ethereum.
The key transformation of files that are moved into IPFS as graph objects involves the following process:
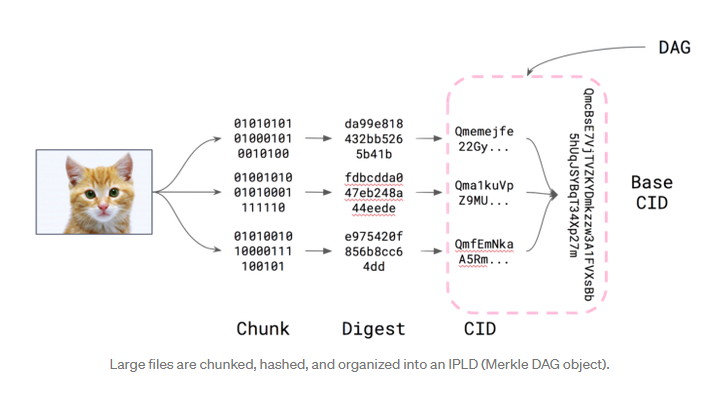 https://medium.com/textileio/whats-really-happening-when-you-add-a-…
https://medium.com/textileio/whats-really-happening-when-you-add-a-…
Carson Farmer, Whats really happening when you add a file to IPFS? Medium post, August 28, 2018, https://miro.medium.com/max/700/1*47aWoFnX2SqRda94YXCcnw.png
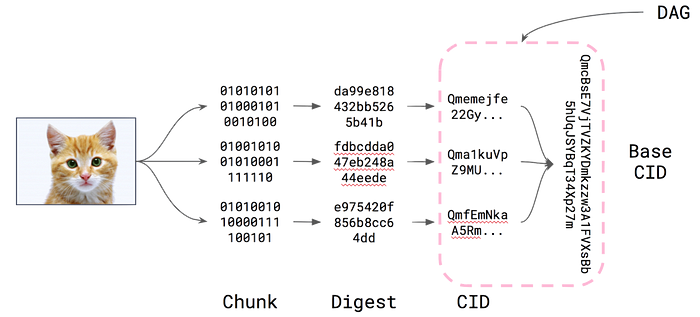{kind=link}
The hierarchical IPLD data structure, in essence, is a directed acyclic graph, which ends up ends up represented as a content identifier, or CID, thats computed from the graph.
Part III of this series will explore the future implications of these new data network capabilities, as well as some of the dominant current use cases.
){kind=link}