

One of the unanticipated consequences of digitization has been data feudalism. A major reason data feudalism was such a surprise was that society just didnt anticipate how quickly online services could scale, or how quickly power would shift as more and more users spent more and more time online. Another surprise was how quickly the services they used would take advantage of the narrow window of opportunity that opened during the 2000s and 2010s to control and harness user data. Governments, caught flat footed, have yet to respond effectively to this development.
Beginning in the 2000s, the world saw tremendous growth in social networking services. With the commoditization of and improvements in distributed compute, networking and storage, each successful social network could scale out to serve hundreds of millions or even billions of users.
Owners of the controlling shares of such a burgeoning service became de facto lords and ladies of the manor. Through the 2010s to the present, the data farm surrounding each manor produced a more and more bountiful harvest with each succeeding year.
The contract users agreed to assigned providers rights to a continual stream of data each user was generating. In this way, each provider collected a tax of sorts in exchange for a service that was otherwise free. The tax was your data harvested from the providers data farm.
Those who signed up were presented with a choice: agree to the providers terms, or dont. Those who didnt stayed disconnected from the rich online communities that emerged.
Those who signed up (as most did) became passive data serfs of a sort. Each data serf helps seed, nurture, harvest and enrich the data from the farms surrounding these online manors. Meanwhile, each provider harvesting a users data maintained and interconnected it with others data–within the providers own data infrastructure. The power of most networked data is therefore now in the hands of the data gentry.
Changing the data custody model
 The laws enacted within the past five years to try to protect personal data–the EUs General Data Protection Regulation (GPDR) and the California Consumer Privacy Act (CCPA) being examples–are well intentioned.
The laws enacted within the past five years to try to protect personal data–the EUs General Data Protection Regulation (GPDR) and the California Consumer Privacy Act (CCPA) being examples–are well intentioned.
But data protection in the current IT environment is a Sisyphean task. Enterprise architectures have been designed to collect and strand data in silos, trap logic in applications, and encourage the creation of more and more silos. (See Dave McCombs book Software Wasteland for a full exploration of how current app-centric architectures fail.)
As an unknown Scot from a past century observed, possession is nine-tenths of the law. How can we get personal data away from providers if the whole ecosystem is in the habit of collecting and making use of that data?
Cloud services perpetuate, rather than alleviate, the problems with older architecture. The only relevant difference between public cloud and on-premise is rent versus buy, and its much simpler to rent. Then the problems become ones of trust and control.
US WPA Art Project, [between 1936 and 1940], https://www.loc.gov/item/98518254/
Hostless or serverless P2P data networks and IPFS
One way to sidestep the old architecture is to move to a more suitable one that already exists. Peer-to-Peer networks arent new, but developments over the past decade have made them more compelling for business use.
Thats particularly the case when it comes to desiloing, data-centric development, and personal data protection. For example, without a central server, each individual user can be in control of their own data from the start, by default. And both data enrichment and app development can be broadly collaborative, even more broadly than Github, by default.
Finally, the development stack for todays P2P data networks is much simpler.
This timeline summarizes the major P2P network developments since the days of Napster and Gnutella, which were designed for music file sharing:
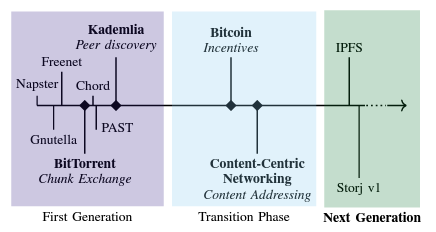
Erik Daniel and Florian Tschorsch, IPFS and Friends: A Qualitative Comparison of Next-Generation Peer-to-Peer Networks, 2021, https://arxiv.org/abs/2102.12737.
The best-known P2P networks in use today are the Bitcoin and Ethereum networks. The goal of these transactional networks has been to harness the power of a tamperproof, immutable blockchain ledger. The ledger with the help of a suitably incentivizing and effective consensus algorithm makes it possible to verify transactions without the help of a third party.
Instead, each peer node can play a role in confirming blocks of transactions. This method also enables tamperproof smart contracts, or legal agreements expressed in self-executing code. Smart contracts will be indispensable in automated commerce and governance, as this illustration underscores:
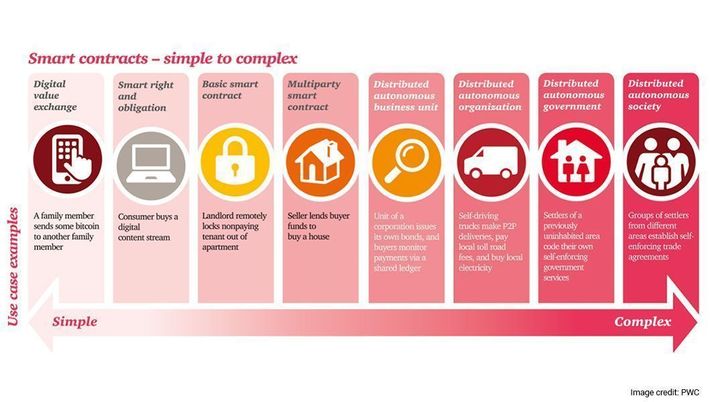
Blockchain (a.k.a., Distributed Ledger Technology, or DLT as the enterprise-class version is called) since its inception in 2009 has been the subject of an enormous amount of hype, primarily because of its association with (marginally) viable cryptocurrency.
But the fact is that blockchain itself or DLT, even as it has evolved over the last 12 years, perpetuates a number of problems with older information infrastructure. In essence, most established chains on their own continue to reinforce the tabular, siloed, opaque status quo weve lived with for 20+ years. It’s more recently created data networks such IPFS that could empower individual users to escape data serfdom–and these can link to the ledgers.
Parts II and III of this series will continue to unpack what next-generation P2P technology could mean for data democracy, as well as whats required to build successful data democracy.
){kind=link}