
Cross-validation is a technique used to assess the accuracy of a predictive model, based on training set data. It splits the training sets into test and control sets. The test sets are used to fine-tune the model to increase performance (better classification rate or reduced errors in prediction) and the control sets are used to simulate how the model would perform outside the training set. The control and test sets must be carefully chosen for this method to make sense.
This resource is part of a series on specific topics related to data science: regression, clustering, neural networks, deep learning, Hadoop, decision trees, ensembles, correlation, outliers, regression, Python, R, Tensorflow, SVM, data reduction, feature selection, experimental design, time series, cross-validation, model fitting, dataviz, AI and many more. To keep receiving these articles, sign up on DSC.
- Cross-validation in R: a do-it-yourself and a black box approach
- Choice of K in K-fold Cross Validation for Classification in Financ…
- Cross-Validation: Concept and Example in R
- How to Train a Final Machine Learning Model +
- How to create a Best-Fitting regression model?
- Underfitting/Overfitting Problem in M/C learning
- SVM in Practice
- Machine Learning : Few rarely shared trade secrets
- What causes predictive models to fail – and how to fix it?
- Use PRESS, not R squared to judge predictive power of regression
- Stacking models for improved predictions
- Data Science Dictionary
- Handling Imbalanced data when building regression models
- 11 Important Model Evaluation Techniques Everyone Should Know
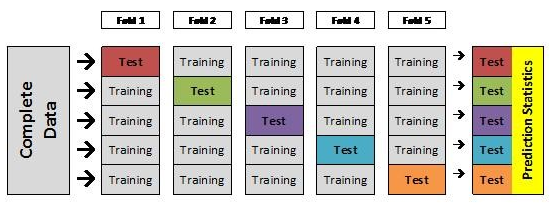
Source for picture: article flagged with a +
DSC Resources
- Services: Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Contributors: Post a Blog | Ask a Question
- Follow us: @DataScienceCtrl | @AnalyticBridge
{kind=link}