
In this post, you discovered how to train a final machine learning model for operational use. You have overcome obstacles to finalizing your model, such as:
- Understanding the goal of resampling procedures such as train-test splits and k-fold cross validation.
- Model finalization as training a new model on all available data.
- Separating the concern of estimating performance from finalizing the model.
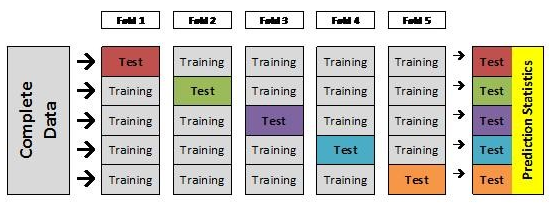
Source for picture: click here (K-fold cross-validation)
Introduction
The machine learning model that we use to make predictions on new data is called the final model. There can be confusion in applied machine learning about how to train a final model. This error is seen with beginners to the field who ask questions such as:
- How do I predict with cross validation?
- Which model do I choose from cross-validation?
- Do I use the model after preparing it on the training dataset?
This post will clear up the confusion. It contains the following sections:
- What is a Final Model?
- The Purpose of Train/Test Sets
- The Purpose of k-fold Cross Validation
- Why do we use Resampling Methods?
- How to Finalize a Model?
There is a Q&A section at the bottom, answering the following questions:
- Why not keep the model trained on the training dataset?
- Why not keep the best model from the cross-validation?
- Won’t the performance of the model trained on all of the data be different?
- Each time I train the model, I get a different performance score; should I pick the model with the best score?
The read the full article, click here.
DSC Resources
- Services: Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Contributors: Post a Blog | Ask a Question
- Follow us: @DataScienceCtrl | @AnalyticBridge
Popular Articles
{kind=link}