
Summary: IBM’s Watson QAM (Question Answering Machine), famous for its 2011 Jeopardy win was supposed to bring huge payoffs in healthcare. Instead both IBM and its Watson Healthcare customers are rapidly paring back these projects that have largely failed to pay off. Watson was the first big out-of-the-box commercial application in ML/AI. Has it become obsolete?

Kudos to IBM for being the leader in bringing us so many AI firsts including these:
- 1996 IBM’s Deep Blue scores the first win by a computer against a top human.
- 2011 Watson wins Jeopardy.
I’m sure I’m leaving out many other notable firsts that IBM has scored but since it’s Watson we want to talk about, we’ll stop there.
The remarkable thing about Watson is that in 2011 the other skills that we think of as AI, image and video processing, facial recognition, text and speech processing, game play beyond chess, autonomous vehicles, all these were so primitive they were not yet close to commercial acceptance and wouldn’t be for several more years.
Fast forward to 2013, IBM announces that healthcare and particularly cancer diagnoses and treatment recommendation will the jackpot for Watson.
By 2015 IBM had already invested north of a reported $15 Billion in Watson.
By 2018 the press over the last two years has been heavy with hospitals scaling back or abandoning Watson altogether. In 2017 prestigious MD Anderson tabled their project. New York’s Sloan Kettering Cancer Center has been helping to train Watson since 2012 but doesn’t use the product on its patients. IBM itself announced a scaling back of its employees working on Watson healthcare.
Although Watson was the first large scale AI out of the box, all of this news about its shortcomings makes us ask, is Watson the first AI technique to be abandoned in this fast moving world of ever increasing AI?
What exactly is Watson?
Before we can address the question we have to clarify exactly what Watson is. The problem is that after the Watson Jeopardy win in 2011 IBM was quick to name almost every version of AI it introduced as Watson. This extends to CNN-based image processing and even analytic platforms for modeling that have nothing whatever to do with the original Watson, or the Watson now taking a beating.
Watson is a Question Answering Machine (QAM)
The Watson QAM being experienced by hospitals is very much the same Watson that won Jeopardy. That is, using NLP text inputs and outputs the Watson QAM searches a large corpus of knowledge and provides the one answer judged most likely to be correct.
There’s an important distinction here between a QAM and simple search.
- In ordinary search it’s fair game to return many pages of links to where the answer may be found.
- With QAMs the requirement is to return the one answer scored by the internal model to most likely represent the one correct answer.
As data scientists are intimately aware, but perhaps not the doctors using Watson, all models come with errors, both false negatives and false positives. In cancer this is particularly problematic. You don’t want to be the patient with the false negative whose cancer was missed any more than you want to be the healthy patient given a mis-diagnosis of cancer.
What doctors have been experiencing is a little more nuanced. As expected most of the time Watson was correct in recommending a diagnosis or treatment. However, on occasion Watson would recommend a clearly wrong or inadequate course of treatment.
During the period of optimism following launch, both the hospitals and IBM billed this as a worthwhile second opinion. However, as time went on doctors in the US found that they had to constantly double check the Watson recommendation and that it wasn’t telling them anything they didn’t already know.
During these last several years, IBM also did a pivot with Watson and introduced a version unique to genomics intending to identify treatments based on genomic markers in the patient. There are scattered anecdotal reports that on occasion Watson Genomics would find something the doctors had not anticipated. In limited overseas use these reports were somewhat more common. But in the US where IBM was reportedly charging $200 to $1,000 per patient for this review this didn’t pencil out financially for hospitals.
The bottom line is that Watson for cancer and to a lesser extent in other healthcare applications looks to be limping toward extinction.
Why is this happening?
It’s possible that this is simply a flaw in execution.
It’s also possible that this indicates that the future for AI QAMs has reached a limit and won’t be a major component of AI going forward.
It’s also possible that it’s a little bit of both.
To explore this we need to look back at how the QAM works and what it takes to set it up.
The Fundamentals of QAMs
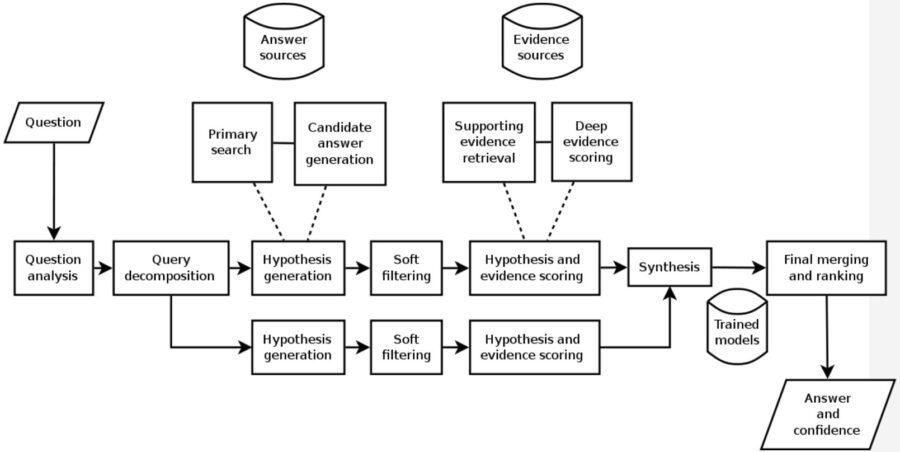
Natural Language Processing (NLP): NLP is at the core of QAMs. NLP has been steadily advancing to be able to interpret the meaning behind a string of words and to interpret the context of those words. (e.g. “I’m feeling blue”, “find the boat with the red bow”). RNNs with their increasing ability to analyze strings or sequences of words both as input and output are a major driver of improvement. So the QAM is able to accept conversational queries (here’s my patient’s medical records and current status, what’s the best course of action), and to provide text output.
Access to a Curated Knowledge Base: The process begins by loading a large amount of structured and unstructured source data relating to the domain to be considered (e.g. cancer diagnosis, healthcare utilization management, law, social media opinion). The knowledge base is human-curated and must be continuously human-updated to remove source documents that are no longer accurate or current as well as adding new material.
Ingestion: QAMs like Watson then start their initial exploration of the knowledge base building indices and metadata to make their subsequent processing more efficient. QAMs may also build graph database adjuncts to assist.
Initial Training: QAMs require a form of supervised learning. Data Scientists load a large number of question and answer pairs from which the QAM learns to generalize which terms and idioms go together and also the core of logic regarding most likely answers. QAMs don’t simply repeat these ‘correct’ sample answers, they learn to go beyond and find other correct answers based on this training data.
Hypothesis and Conclusion: When asked a question, the QAM will parse the question to develop a series of potential meanings or hypotheses and look for evidence in the knowledge base supporting them. Each hypothesis is then statistically evaluated for the QAM’s confidence that it is correct and the answers are presented to the end user.
Knowledge Discovery: In some applications multiple answers or alternatives may actually be the goal. These may represent combinations of facts and circumstances that had not previously been thought of by humans, such as combinations of chemicals, drugs, treatments, materials, or chains of DNA that may represent new and novel innovations in their field. In some cancer applications Watson returns a prioritized list of possible treatments.
Where is the breakdown occurring?
This isn’t meant to be a forensic study of each use case but I have a strong hunch what’s going on here. QAMs like Watson are extremely labor intensive, much more so than any other ML/AI we’re currently utilizing.
There is a very large amount of human labor required to identify and load all the documents and data needed to set up the original corpus of knowledge, and an on-going requirement to continuously review and remove knowledge that is out of date while keeping up with all the new findings in the field.
Add to this the initial and on-going training of the search relevance model which is trained off of human-generated question-and-answer pairs.
This is a very different model of AI/ML implementation than we’ve become used to. My suspicion is that the very large labor component in maintaining the database for a topic as vast and complex as cancer, or healthcare in general, has been its Achilles heel.
Are there examples of where Watson is being successful?
I’m sure there are in situations where the corpus of knowledge is more constrained and less fast changing. When we reviewed Watson in 2016 we listed 30 different examples of how Watson was being employed including these:
Macys developed “Macy’s On Call,” a mobile web app that taps Watson to allow customers to input natural language questions regarding each store’s unique product assortment, services and facilities and receive a customized response to the inquiry.
VineSleuth developed its Wine4.me app to provide wine recommendations for consumers based on sensory science and predictive algorithms. The start-up uses Watson’s language classifier and translation services in kiosks in grocery stores.
Hilton Worldwide uses Watson to power “Connie”–the first Watson-enabled robot concierge in the hospitality industry. Connie draws on domain knowledge from Watson and WayBlazer to inform guests on local tourist attractions, dining recommendations and hotel features and amenities.
Purple Forge developed a Watson based 311 Service for Surrey, Canada to answer citizens’ questions about government services. (When is recyclables pickup?) The app can answer more than 10,000 questions, more efficiently and at lower cost than humans.
The way forward
What these examples have in common is that the knowledge base is much more limited and/or slow to change. Second and perhaps more relevant is that these simpler customer-facing applications are now being addressed with the explosive adoption of chatbots.
So it appears that the ‘bottom end’ of this market is benefiting from the advancements in NLP via chatbots, with or more commonly without Watson QAM.
At the ‘top end’ of this market is where the corpus of knowledge is very large and fast changing. The promise was that a sophisticated QAM hypothesis/search algorithm could combine elements of knowledge not previously combined to create unique new insights.
Watson has some competition in this arena coming at these complex problems from a different approach. For example, one hoped for outcome was the discovery of new chemicals, materials, drugs, or DNA functions. While Watson could conceivably still prove useful in this arena, researchers increasingly are opting for less labor intensive CNNs and RNNs for discovery. This is particularly true in the field of biology.
There may still be a sweet spot for Watson in the middle of this continuum but those opportunities seem increasingly hemmed in by chatbots on the bottom and more advanced techniques on the top.
It’s probably not time to say that QAMs no longer have a place in the pantheon of AI/ML, but the very high labor requirements in setup and maintenance are not as enticing as accomplishing much the same thing with deep neural nets, reinforcement learning, and tons of non-human compute power.
Previous Articles about Watson
30 Fun Ideas for Starting New AI Businesses and Services with Watson
IBM Watson Does Your Taxes: Question Answering Machine versus Expert System
Other articles by Bill Vorhies.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}