
Summary: There are some interesting use cases where combining CNNs and RNN/LSTMs seems to make sense and a number of researchers pursuing this. However, the latest trends in CNNs may make this obsolete.
 There are things that just don’t seem to go together. Take oil and water for instance. Both valuable, but try putting them together?
There are things that just don’t seem to go together. Take oil and water for instance. Both valuable, but try putting them together?
That was my reaction when I first came across the idea of combining CNNs (convolutional neural nets) and RNNs (recurrent neural nets). After all they’re optimized for completely different problem types.
- CNNs are good with hierarchical or spatial data and extracting unlabeled features. Those could be images or written characters. CNNs take fixed size inputs and generate fixed size outputs.
- RNNs are good at temporal or otherwise sequential data. Could be letters or words in a body of text, stock market data, or speech recognition. RNNs can input and output arbitrary lengths of data. LSTMs are a variant of RNNs that allow for controlling how much of prior training data should be remembered, or more appropriately forgotten.
We all know to reach for the appropriate tool based on these very unique problem types.
So are there problem types that need the capability of both these tools?
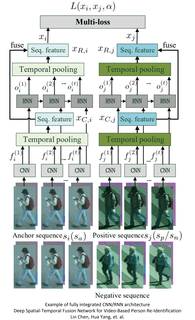 As it turns out, yes. Most of these are readily identified as images that occur in a temporal sequence, in other words video. But there are some other clever applications not directly related to video that may spark your imagination. We’ll describe several of those below.
As it turns out, yes. Most of these are readily identified as images that occur in a temporal sequence, in other words video. But there are some other clever applications not directly related to video that may spark your imagination. We’ll describe several of those below.
There are also several emerging models of how to combine these tools. In most cases CNNs and RNNs have been married as separate layers with the output of the CNN being used as input to the RNN. But there are some researchers cleverly combining these two capabilities within a single deep neural net.
Video Scene Labeling
The classical approach to scene labeling is to train a CNN to identify and classify the objects within a frame and perhaps to further classify the objects into a higher level logical group. For example, the CNN identifies a stove, a refrigerator, a sink, etc. and also up-classifies them as a kitchen.
Clearly the element that’s missing is the meaning of the motion over several frames (time). For example, several frames of a game of pool might correctly say, the shooter sinks the eight ball in the side pocket. Or several frames of a young person learning to ride a two-wheeler followed by the frame of the rider on the ground, might reasonably be summarized as ‘boy falls off bike’.
Researchers have used layered CNN-RNN pairs where the output of the CNN is input to the RNN. Logically the RNN has also been replaced with LSTMs to create a more ‘in the moment’ description of each video segment. Finally there has been some experimentation done with combined RCNNs where the recurrent connection is directly in the kernels as in the diagram above. See more here.
Emotion Detection
Judging the emotion of individuals or groups of individuals from video remains a challenge. There is an annual competition around this held by the ACM International Conference on Multimodal Interaction known as the EmotiW Grand Challenge.
Each year the target data changes somewhat in nature and typically there are different tests for classifying groups of people versus individuals appearing in videos.
2016: Group based happiness intensity.
2017: Group based three class (positive/neutral/negative) emotion detection.
2018 (scheduled for November) is even more complex. The challenge will involve classification of eating conditions. There are three sub-challenges:
- Food-type Sub-Challenge: Perform seven-class food classification per utterance.
- Food-likability Sub-Challenge: Recognize the subjects’ food likability rating.
- Chew and Speak Sub-Challenge: Recognize the level of difficulty to speak while eating.
The key to this challenge is not only the combination of CNNs and RNNs but also the inclusion of an audio track that can be separately modeled and integrated.
In 2016 the winners created a hybrid network consisting of a RNN and 3D convolutional networks (C3D). Data fusion and classification takes place late in the process as is traditional. The RNN takes appearance features extracted by the CNN from individual frames as input and encodes motion later, while C3D models appearance and motion of video simultaneously, subsequently also merged with the audio module.
Accuracy in this very difficult field still isn’t great. The 2016 winners scored 59.02% on the individual faces. By 2017 the individual face scores were up to 60.34% and the group scores were up to 80.89% – keeping in mind that the nature of the challenge changes each year so year-over-year comparison isn’t possible. More on this annual challenge here.
Video Based Person Re-identification / Gait Recognition
The goal here is to identify a person when seen in video (from a database of existing labeled individuals) or simply to recognize if this person has been seen before (re-identification – not labeled). The dominant line of research has been in gait recognition and the evolving field uses full body motion recognition (arm swing, limps, carriage, etc.).
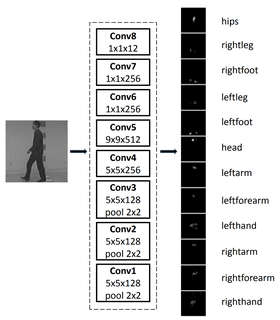 There are some evident non-technical challenges here the most obvious being change in clothing, shoes, partial obscurity from coats or packages, and the like. The technical problems well known in CNN are multiple viewpoints (in fact multiple view points as a single person passes say from right to left offering first front, then side, then back views) and the classical image problems of lighting, albedo, and size.
There are some evident non-technical challenges here the most obvious being change in clothing, shoes, partial obscurity from coats or packages, and the like. The technical problems well known in CNN are multiple viewpoints (in fact multiple view points as a single person passes say from right to left offering first front, then side, then back views) and the classical image problems of lighting, albedo, and size.
Prior efforts were based on combining several frames of CNN derived data representing one full step (gait) into a type of heat map called a Gait Energy Image (GEI).
Addition of an LSTM allowed several ‘steps’ to be analyzed together and the time series capability of the LSTM works as a frame-to-frame view transformation models to adjust for perspective.
This study including the image can be found here. Not surprisingly given the application to surveillance, gait recognition has the highest number of cited research papers, almost all of which are being conducted in China.
Full human pose recognition, both for recognition and for labeling (the person is standing, jumping, sitting, etc.) is the next frontier with separate convolutional models for each body part. Gesture recognition as part of a UI especially in augmented reality is becoming a hot topic.

Weather Prediction
The objective is to predict the intensity of rainfall over a localized region and over a fairly short time span. This field is known as ‘nowcasting’.
Quantifying the Functions of DNA Sequences
Some 98% of human DNA is non-coding, known as Introns. Originally thought to be evolutionary leftovers with no value, geneticists now know that for example 93% of disease associated variants lie in these regions. Modeling properties and functions of these regions is an ongoing challenge recently made somewhat easier by a combination CNN/LSTM called DanQ.
According to the developers “the convolution layer captures regulatory motifs, while the recurrent layer captures long-term dependencies between the motifs in order to learn a regulatory ‘grammar’ to improve predictions. DanQ improves considerably upon other models across several metrics. For some regulatory markers, DanQ can achieve over a 50% relative improvement in the area under the precision-recall curve metric compared to related models.” The study is here.
Creating Realistic Sound Tracks for Silent Videos
MIT researchers created an extensive collection of labeled sound clips of drumsticks hitting pretty much everything they could think of. Using a combined CNN/LSTM, the CNN identifies the visual context (what the drumstick is hitting in the silent video) but since the sound clip is temporal and extends over several frames, the LSTM layer is used to match the sound clip to the appropriate frames.
The developers report that humans were fooled by the predicted sound match more than 50% of the time. See video here.
Future Direction
I was surprised to find such a wealth of examples in which researchers combine CNNs and RNNs to gain the advantages of both. There are even some studies utilizing GANs in hybrid networks that are quite interesting.
However, while these mashups seem to provide additional capabilities there is another, newer and perhaps more prominent line of research that says that CNNs alone can do the job and that the days of RNNs/LSTMs are numbered.
One group of researchers used a novel architecture of deep forests embedded in a node structure to outperform CNNs and RNNs, with significant savings in compute and complexity.
We also reviewed the more mainstream movement by both Facebook and Google who recently abandoned their RNN/LSTM based tools for speech-to-speech translation in favor of Temporal Convolutional Nets (TCNs).
Especially in text problems, but more generally in any time series problem RNNs have an inherent design problem. Because they read and interpret the input text one word (or character or image) at a time, the deep neural network must wait to process the next word until the current word processing is complete.
This means that RNNs cannot take advantage of massive parallel processing (MPP) in the same way the CNNs can. Especially true when the RNN/LSTMs are running both ways at once to better understand context.
This is a barrier that won’t go away and seems to place an absolute limit on the utility of RNN/LSTM architecture. Temporal Convolutional Neural Nets get around this by using CNN architecture which can easily use MPP acceleration with the emerging concepts of attention and gate hopping. For more detail please see our original article.
I’m certainly not one to write off an entire line of research, especially where the need for minimum latency is not as severe as speech-to-speech translation. However, all of these problems described above do seem ripe for a repeated examination using this newer methodology of TCNs.
Other articles by Bill Vorhies.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}