
Summary: Next time you bring up Artificial Intelligence and your non-data scientist friends all say “Watson” here’s some perspective you can offer. Their understanding of AI and Watson is very likely to be inaccurate. Here’s what you need to know to set them straight.
When conversation with my non-data scientist friends turns to AI it’s almost inevitable that at least one will remark on the wonders of Watson. To many of the uninformed, Watson is synonymous with AI and clearly it’s already here. All hail Watson.
So without getting so technical that their eyes glaze over, and that can happen pretty fast, here’s a little bit of explanation you can use if you’re caught in the same circumstance.
“Popular” Watson
 The Watson that lives in the imagination of so many folks is the Watson that won the widely televised contest on Jeopardy in 2011. Fewer people are aware that the month following its televised debut, Watson went to Washington and played an untelevised set of matches against members of the House of Representatives where it also won.
The Watson that lives in the imagination of so many folks is the Watson that won the widely televised contest on Jeopardy in 2011. Fewer people are aware that the month following its televised debut, Watson went to Washington and played an untelevised set of matches against members of the House of Representatives where it also won.
By the way, Watson didn’t win either in a walk-off. It missed several questions through faulty logic and several more by being slower to respond than the human opponents.
Also, Watson didn’t emerge overnight. IBM first formulated the challenge in 2005. Keep in mind that Hadoop wasn’t even open-sourced until mid-2006 and didn’t have its first commercial rollout at Yahoo until 2008 so all of this started when Big Data and particularly MPP was barely a gleam in the eye of some very cloistered researchers. It took an IBM team of 15 until 2008 to build a competitive Jeopardy machine and until 2010 to build the Watson that could win.
The point is that the Watson that lives in popular imagination is very old technology, practically archaic in performance compared to the advances of the last five years.
Core Watson and Its Jeopardy Add-Ons
At its core, Watson was and remains a ‘Question Answering Machine’ (QAM). This is fundamentally different from search which returns a list of possible sources where the answer may be found. Question Answering Machines must understand the question with all its semantic and contextual variations and deliver a single answer most likely to be correct.
 Yes, what started off as a massive trivia answering machine is now also the core technology for Siri, Cortana, Alexa, and of course IBM’s Watson.
Yes, what started off as a massive trivia answering machine is now also the core technology for Siri, Cortana, Alexa, and of course IBM’s Watson.
The Jeopardy Watson however had some features that were built in just for the Jeopardy competition. Since winning at Jeopardy includes betting on the Daily Double, Watson was given a separate routine specifically to rapidly identify the Daily Double question and to place an optimum wager.
Second, it had an electronic finger to push the buzzer. Human opponents sometime gain an advantage by anticipating their answer and pushing the buzzer as quickly as possible, even before formulating their answer. Jeopardy Watson couldn’t do that, but it did have an ultra-quick electronic finger to buzz-in once it had reached a conclusion.
It takes on average about 6 or 7 seconds to read the full question which is equivalent to the minimum amount of processing time a human opponent has to begin searching their own knowledge. Tougher questions of course take longer and sometimes the human opponents beat Watson to its conclusion, sometimes not.
This leads to the hardware issue. 2011 Jeopardy Watson had a knowledge base of 200 million structured and unstructured documents equivalent to about 4 terabytes of storage, pretty trivial by today’s standards. At the time this was supported by about $1 Million of IBM’s fastest MPP processors capable of processing about 500 Gigabytes per second, roughly the same as a million books per second. Plus, during practice the knowledge base was held on disk storage but during competition the entire knowledge base was held in RAM to make it as fast as human competitors.
Today’s applications of Watson are orders of magnitude more powerful and less expensive.
Question Answering Machines (QAMs) are the First Leg of AI
To use a more accurate term than AI, let us call this field Cognitive Computing which more correctly indicates the scope of speech, text, and vision that the entire field is intended to have. In the last 12 to 24 months the attention has been on Convolutional Neural Nets (CNNs) and Recurrent Neural Nets (RNNs) that have dramatically enhanced image, text, speech, translation, facial recognition, automated picture and video tagging, and similar. The first leg however was QAMs which were early beneficiaries of Big Data technologies and are today well into the age of exploitation and refinement, with most of the innovation in basic technologies having been achieved.
The Fundamentals of QAMs
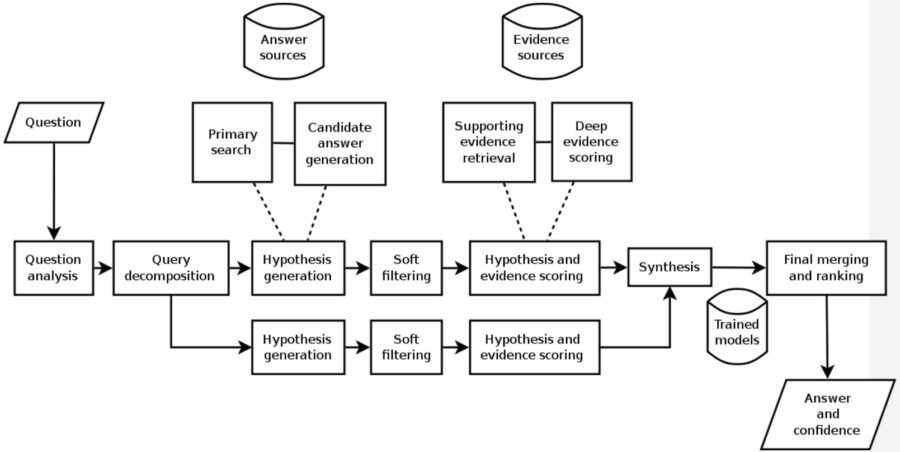
Natural Language Processing (NLP): NLP is at the core of QAMs and is no longer just a word-at-a-time or key word search method. NLP has been steadily advancing to be able to interpret the meaning behind a string of words and to interpret the context of those words in the string. (e.g. “I’m feeling blue”, “find the boat with the red bow”). RNNs with their increasing ability to analyze strings or sequences of words both as input and output are a major driver of improvement.
Access to a Curated Knowledge Base: The process begins by loading a large amount of structured and unstructured source data relating to the domain to be considered (cancer diagnosis, healthcare utilization management, law, social media opinion). Note that the knowledge base is human curated and must be continuously human-updated to remove source documents that are no longer accurate or current as well as adding new material.
Ingestion: QAMs like Watson then start their initial exploration of the knowledge base building indices and metadata to make their subsequent processing more efficient. In some instances QAMs may build graph database adjuncts to assist in answering more precise questions.
Initial Training: QAMs require a form of supervised learning. Data Scientists load a large number of question and answer pairs from which the QAM learns to generalize which terms and idioms go together and also the core of logic regarding most likely answers. QAMs don’t simply repeat these ‘correct’ sample answers, they learn to go beyond and find other correct answers based on this training data.
Hypothesis and Conclusion: When asked a question, the QAM will parse the question to develop a series of potential meanings or hypotheses and look for evidence in the knowledge base supporting them. Each hypothesis is then statistically evaluated for the QAM’s confidence that it is correct and the answers are presented to the end user.
Knowledge Discovery: In some applications multiple answers or alternatives may actually be the goal. These may represent combinations of facts and circumstances that had not previously been thought of by humans, such as combinations of chemicals, drugs, treatments, materials, or chains of DNA that may represent new and novel innovations in their field.
The New Watson Ecosystem
Beyond the popular understanding, Watson is alive and well in a growing ecosystem with increasing capabilities. In addition to increasing sophistication in basic language models, new CNN and RNN applications can be combined with or even used as knowledge inputs for Watson.
In the last year, IBM has released a string of products and developer capabilities including cloud versions from what is now known internally at IBM as the Watson Group. Products have included Watson Analytics, Watson Discovery Advisor, Watson Engagement Advisor, and Watson Oncology.
On the developer side, IBM has rolled out free cloud based apps available via API including IBM Watson Language Translation, IBM Speech to Text, and IBM Text to Speech. These add to the five that IBM had already released, including its Personality Insights and Tradeoff Analytics services, and three services from recently acquired AlchemyAPI, including AlchemyLanguage, AlchemyVision, and AlchemyData News. There are more than 20 Watson services at some stage in the delivery pipeline.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}