
Summary: For those of you traditional data scientist who are interested in AI but still haven’t given it a deep dive, here’s a high level overview of the data science technologies that combine into what the popular press calls artificial intelligence (AI).
 We and others have written quite a bit about the various types of data science that make up AI. Still I hear many folks asking about AI as if it were a single entity. It is not. AI is a collection of data science technologies that at this point in development are not even particularly well integrated or even easy to use. In each of these areas however, we’ve made a lot of progress and that’s caught the attention of the popular press.
We and others have written quite a bit about the various types of data science that make up AI. Still I hear many folks asking about AI as if it were a single entity. It is not. AI is a collection of data science technologies that at this point in development are not even particularly well integrated or even easy to use. In each of these areas however, we’ve made a lot of progress and that’s caught the attention of the popular press.
This article is not intended to be a deep dive but rather the proverbial 50,000 foot view of what’s going on. If you’re a traditional data scientist who’s read some articles but still hasn’t put the big picture together you might find this a way of integrating your current knowledge and even discovering where you’d be interested in focusing.
AI is Simply the Sum of its Data Science Parts
The data science ‘parts’ that make up AI fall in into the following categories. There is overlap here but these are the detailed topics you’ll see in the press.
- Deep Learning
- Natural Language Processing
- Image Recognition
- Reinforcement Learning
- Question Answering Machines
- Adversarial Training
- Robotics
These are all separate disciplines (OK the category of Deep Learning actually contains some of the others). AI is simply the sum of these parts. They hang together only very loosely and have been bolted together into some really marvelous applications by a whole host of startups and major players. When they work well together as they do for example in Watson, or Echo/Alexa, or as they are starting to do in self-driving cars then they may appear to be more than the sum of their parts. But they’re not. Integration of these different technologies is still one of the biggest challenges.
What Must Our AI be Able to Do?
 When explaining this to beginners I always find it helpful to start with this anthropomorphic description of what human-like capabilities our AI would need to have.
When explaining this to beginners I always find it helpful to start with this anthropomorphic description of what human-like capabilities our AI would need to have.
See: this is still and video image recognition.
Hear: receive input via text or spoken language.
Speak: respond meaningfully to our input either in the same language or even a foreign language.
Make human-like decisions: Offer advice or new knowledge.
Learn: change its behavior based on changes in its environment.
Move: and manipulate physical objects.
You can immediately begin to see that many of the commercial applications of AI that are emerging today require only a few of these capabilities. But the more sophisticated applications that we’re looking forward to would need to have pretty much all of these.
Converting Human-Like Capabilities to Data Science
Here’s where this gets a little messy. Each of these capabilities don’t necessarily line up one-to-one with their underlying data science. But how the data science matches up with these requirements is the most important part of truly understanding what’s going on in AI today. As a diagram they would match up more or less like this:

What Happened to Deep Learning
You may have noticed that ‘Deep Learning’ is missing from our chart. That’s because it is a summary category for the Recurrent Neural Nets and Convolutional Neural Nets above. Artificial Neural Nets (ANNs), the highest summary level have been around since the 80’s and have always been part of the standard data science machine learning tool kit for solving standard classification and regression problems.
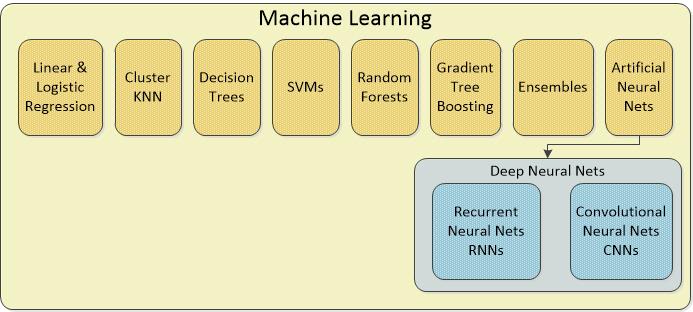
What’s happened recently is that our massive increases in parallel processing, cloud processing, and the use of GPU (graphical processing units) instead of traditional Intel chips have allowed us to experiment with versions of ANNs that have dozens or even more than a hundred hidden layers. These hidden layers are what causes us to call these types ‘deep’, hence ‘deep learning’. Adding hidden layers means multiplying computational complexity which is why we had to wait for the hardware to catch up with our ambitions.
There are at least 27 different types of ANNs but the most important are the Convolutional Neural Nets (CNNs) and the Recurrent Neural Nets (RNNs) without which image and natural language processing would not be possible.
A (Very) Brief Discussion of the Data Science
To do justice to any of these underlying data science technologies would require multiple articles. What we’ll try to do here is give you the briefest of descriptions and some links to more complete information.
Convolutional Neural Nets (CNNs): CNNs are at the heart of all types of image and video recognition, facial recognition, image tagging (think Facebook) and recognizing a stop sign from a pedestrian in our self-driving cars. They are extremely complex, difficult to train, and while you don’t need to specify specific features (the cat has fur, a tail, four legs, etc.) you do need to show a CNN literally millions of examples of cats before it can be successful. The large amount of training data is a huge barrier. See more about CNNs here.
Recurrent Neural Nets (RNNs): RNNs are at the center of natural language processing (NLP) and also game play and similar logical problems. Unlike CNNs they process information as a time series in which each subsequent piece of data relies in some way on the piece that came before. It may not be obvious but speech falls in this category since the next character or the next word is logically related to the preceding one. RNNs can work at the character, word, or even long paragraph level which makes them perfect for providing the expected long form response to your customer service question. RNNs handle both the understanding of the text question as well as the formulation of complex responses including translation into foreign languages. RNNs are also responsible for computers winning at chess and Go. See more about RNNs here.
Generative Adversarial Neural Nets (GANNs): CNNs and RNNs both suffer from the same problem of requiring huge and burdensome amounts of data in order to train, either to recognize that stop sign (image) or to learn the instructions necessary to answer your question about how to open that account (speech and text). GANNs hold the promise of being able to dramatically reduce training data as well as dramatically increase accuracy. They do it by battling each other. There is a great story here about training a Convolutional Neural Net to recognize fake French impressionist paintings. In a nutshell, one CNN is trained on real French impressionist paintings so that it is supposed to know the real ones. The other adversarial CNN, called a Generative Adversarial Neural Net is given the task of actually creating fake impressionist painting.
CNNs perform their task of image recognition by turning pixel values into complex numerical vectors. If you run them backwards, that is start with random numerical vectors they can create an image. In this scenario, the Generative NN creating fakes produces images trying to fool the CNN which is trying to learn how to detect fakes. They battle it out until the Generative (fake maker) produces images so good the CNN can’t tell them from the original and the two adversarial nets draw to a tie. Meanwhile the CNN designed to determine the originals from the fakes has been trained superbly in the detection of the fakes without the unrealistic requirement for millions of forged French impressionist masters on which to train. In short this is learning from their environment.
Question and Answer Machines (QAMs): QAM is the rather inelegant name we give to the likes of IBM’s Watson. These are huge knowledge repositories that are trained to find unique associations in their knowledge base and provide the answer to complex questions they have not previously seen. Where ordinary search returns a list of sources where your answer might be found, QAMs must return the single best answer.
This is a mash-up of NLP and sophisticated search in which the QAM builds multiple hypotheses about the possible meaning of the question and returns the best response based on weighted evidence algorithms.
QAMs require large bodies of data about the topic to be studied to be loaded by humans and humans must then train and maintain the knowledge base. However, once established they have been shown to be expert in areas such as cancer detection (in conjunction with CNNs), medical diagnosis, discovering unique combinations of materials and chemicals, and even in teaching your high school student how to program. In short, wherever there is a very large body of knowledge that needs expert interpretation, a QAM can be the brain or at least the associative memory for our AI. See some good references here, here, and here.
Reinforcement Learning Systems (RLS)
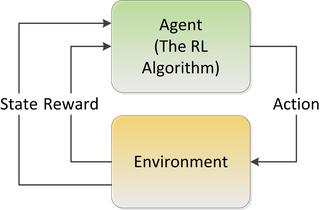 RLS is a method of training a system to recognize the best outcome in direct response to its environment. There is not a single algorithm here but rather a group of custom applications. RNNs can be used as one type of ‘agent’ in RLS. RLS are the core technology in self-driving cars and similar devices that do not require a language interface. Essentially this a method by which machines can learn from and remember the best action to take under a specific set of circumstances. When your self-driving car decides to stop at a yellow light instead of going through, an RLS was used to create that learned behavior. See more here.
RLS is a method of training a system to recognize the best outcome in direct response to its environment. There is not a single algorithm here but rather a group of custom applications. RNNs can be used as one type of ‘agent’ in RLS. RLS are the core technology in self-driving cars and similar devices that do not require a language interface. Essentially this a method by which machines can learn from and remember the best action to take under a specific set of circumstances. When your self-driving car decides to stop at a yellow light instead of going through, an RLS was used to create that learned behavior. See more here.
Robotics
The field of robotics is important to AI because it is a primary way that the AI data science manifests itself in the real world. Most of robotics is straightforward and very sophisticated engineering. The AI behind robotics is primarily Reinforcement Learning.
Spiking Neural Nets (aka Neuromorphic Computing)
 It is common to say that we are in the 2nd generation of AI based mostly on the hardware advances we’ve made that allow us to use variations on algorithms like Neural Nets that simply weren’t feasible in the past. But all of this is moving very quickly and we are on the frontier of moving into 3rd generation AI.
It is common to say that we are in the 2nd generation of AI based mostly on the hardware advances we’ve made that allow us to use variations on algorithms like Neural Nets that simply weren’t feasible in the past. But all of this is moving very quickly and we are on the frontier of moving into 3rd generation AI.
The 3rd generation will be based on Spiking Neural Nets also called Neuromorphic Computing because it tries to more closely mimic the way the brain actually works. The core of the change is around the fact that brain neurons do not constantly communicate with one another but rather in spikes of signals. The challenge is to figure out how a message should be encoded in this train of electrical spikes.
This is at the mid-research stage so far and I am only aware of two instances where it’s been applied in commercial applications. There could be many more still in stealth mode. A lot of investment and brain power is pouring into this development. It will also require a totally new type of chip that will mean yet another hardware revolution.
When they arrive, we expect the following:
- They can learn from one source and apply it to another. They can generalize about their environment.
- They can remember. Tasks once learned can be recalled and applied to other data.
- They are much more energy efficient which opens a path to miniaturization.
- They learn from their environment unsupervised and with very few examples or observations. That makes them quick learners.
To see more about Spiking Neural Nets see the articles here and here.
Keeping Up With AI
To keep up with AI follow these technologies and these two trends.
- Commercialization of AI as it currently exists (2nd generation) is being applied to virtually everything as fast as the majors as well as a host of startups can go. It is likely that this will be as pervasive as the electrification of the US in the 1920s.
- Watch for advances in Spiking Neural Nets to make this all even more amazing.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. . He can be reached at:
{kind=link}